
LLM Oriented Engineering
Reindeer CTO Yair Wein이 LLM 기반 제품·개발 조직을 1년 반 동안 운영하며 굳힌 9가지 원칙. 인간 컨텍스트가 가장 희소한 자원이라는 전제에서 출발해, load-bearing 코드와 padded rooms, 자동 enforcement, PM의 별도 MVP 레포, 보상 함수로서의 테스트, 미래 개발자의 능력까지 펼친다.
Reindeer CTO Yair Wein이 LLM 기반 제품·개발 조직을 1년 반 동안 운영하며 굳힌 9가지 원칙. 인간 컨텍스트가 가장 희소한 자원이라는 전제에서 출발해, load-bearing 코드와 padded rooms, 자동 enforcement, PM의 별도 MVP 레포, 보상 함수로서의 테스트, 미래 개발자의 능력까지 펼친다.
수학 블로그에 LLM 문장 다듬기를 쓰던 저자가 3개월 뒤 인터넷 전반에서 같은 문장 구조와 디자인 클리셰가 반복되는 것을 발견하고, 글쓰기·웹사이트 두 도메인의 ‘AI 냄새(AI smell)’ 사례를 짧게 모은 관찰 노트.
Mauro Bieg는 지금 AI가 프로그래밍에 일으키는 변화가 지난 10년 프론트엔드의 ‘잃어버린 10년’과 닮았다고 본다. 탈숙련화·누수 많은 추상화·Stack Overflow 복붙의 연장이라는 세 렌즈로 현 국면을 진단하고, 바우하우스 운동에서 응답의 단서를 찾는다.

일본 디자이너 なつ(@Dia_Nexus)가 정리한 ‘중간 표기 패턴(MNP)’ — AI에게 GUI를 조작시키는 대신, GUI 상태를 표현하는 텍스트 DSL을 두고 그 DSL을 양방향으로 다루게 하는 도구 설계 패턴.
프론티어 랩의 토큰 가격이 빠르게 오르는 동안 DeepSeek 같은 OSS 모델은 30분의 1 수준에 머문다. SignalBloom AI는 저렴한 국가의 엔지니어 한 명 + LocalAI 조합이 곧 프론티어 추론 단독보다 경제적이 되는 임계가 다가오고 있으며, 이 동학이 프론티어 가격에 천장을 씌운다고 진단한다.
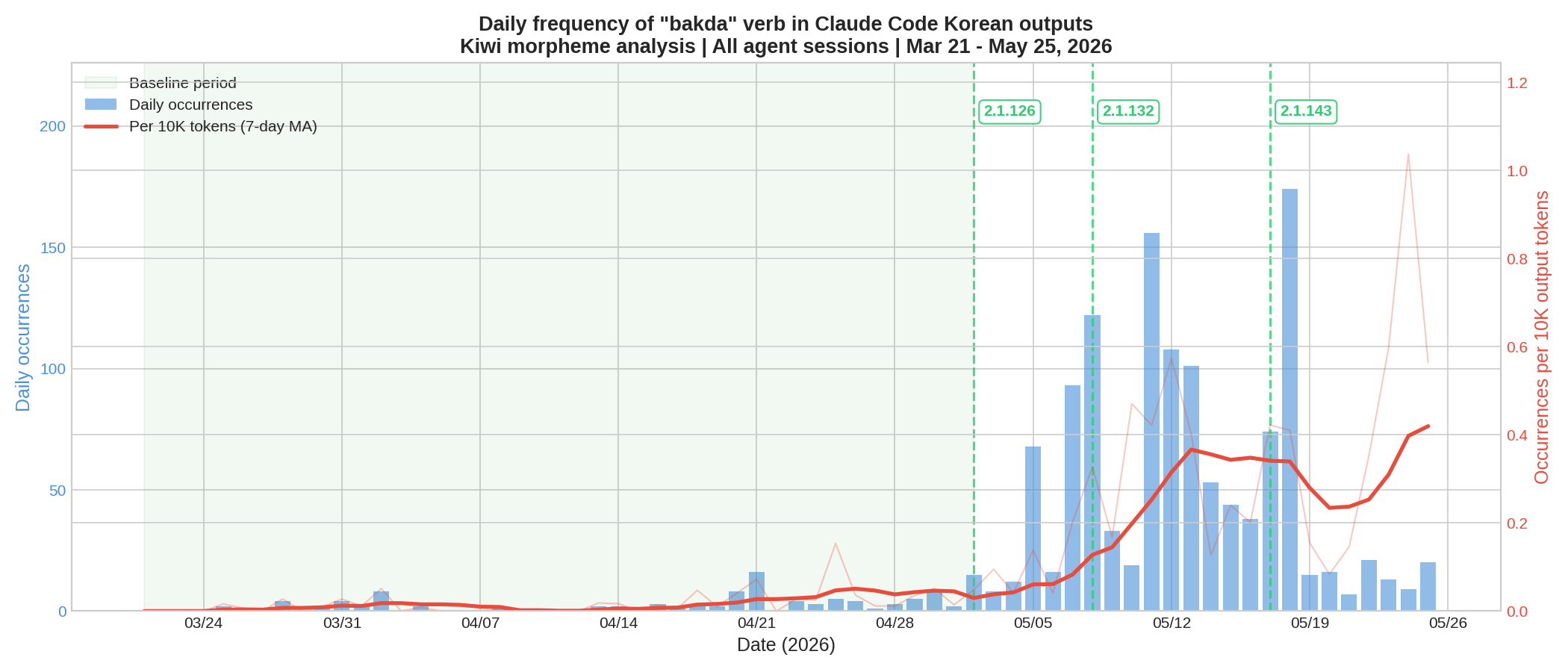
Kiwi morpheme analysis across 114.9M output tokens reveals that Claude Code’s Korean outputs use the informal verb “박다” (bakda) at 18× the baseline rate after version 2.1.132, with a self-contamination feedback loop amplifying the tendency in under one week.
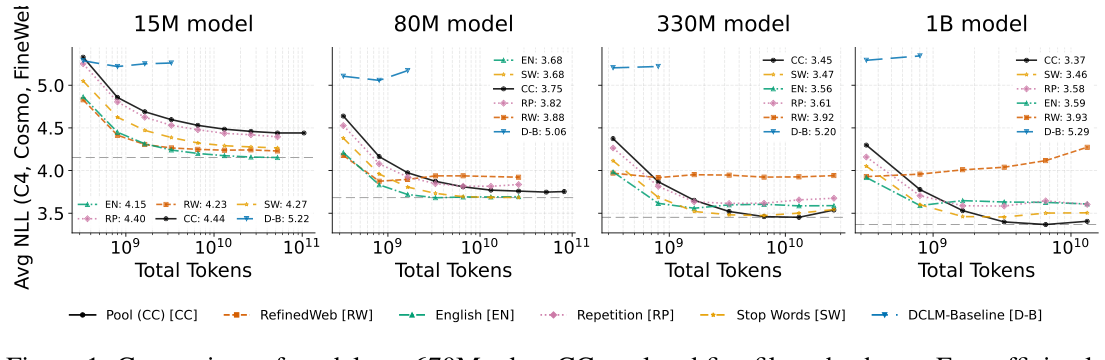
컴퓨트가 충분히 크면 데이터 필터링은 오히려 손해다 — Stanford 연구진이 Common Crawl과 5개 표준 필터를 비교하여, 큰 모델이 ‘저품질’ 데이터에서도 이득을 본다는 증거를 제시한다.
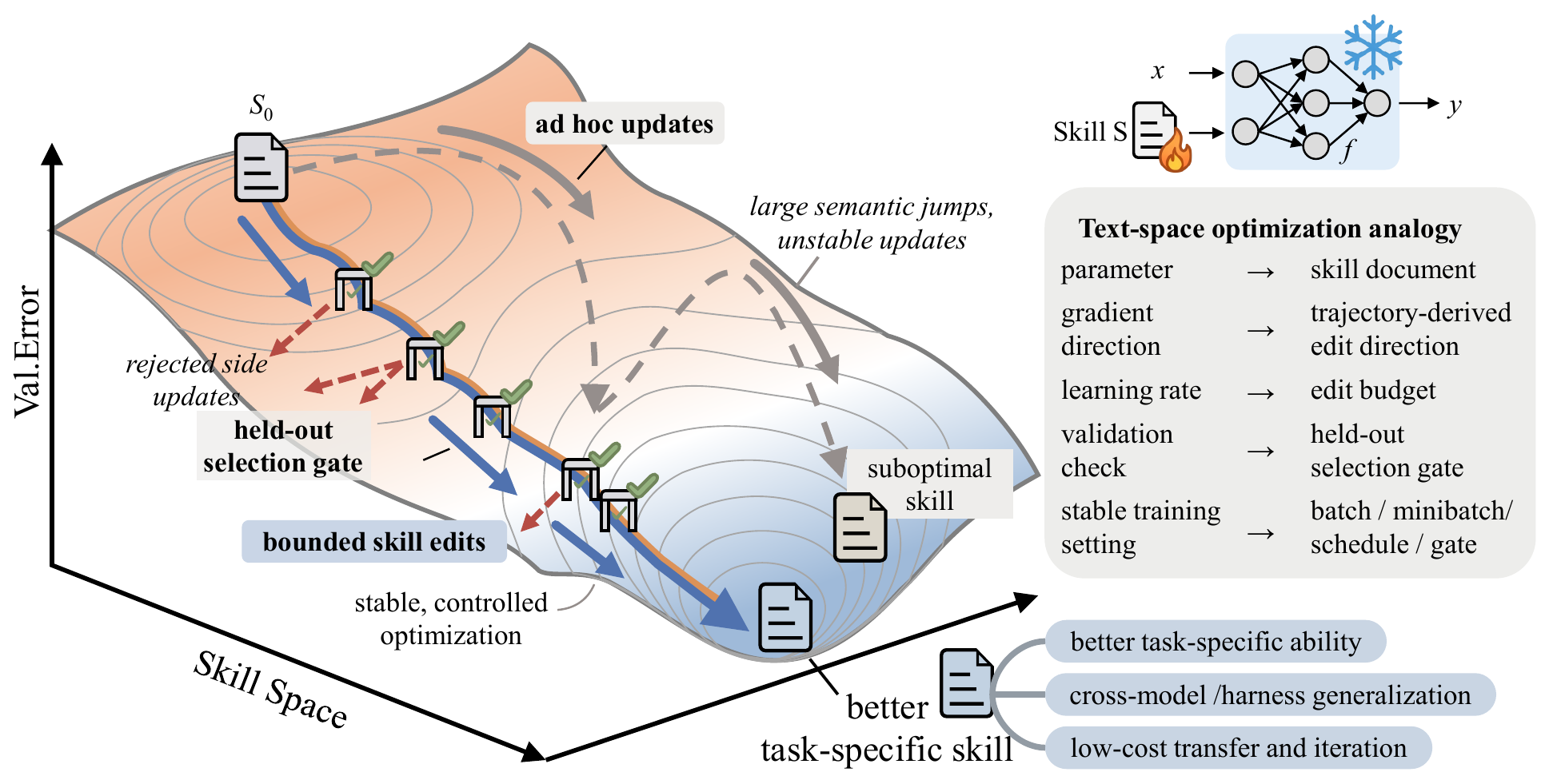
Microsoft가 공개한 SkillOpt는 모델 가중치를 동결한 채 자연어 기술 문서 한 장을 딥러닝 옵티마이저처럼 반복 학습하여 LLM 에이전트의 성능을 끌어올리는 텍스트 공간 최적화 프레임워크다. 채점 가능한 태스크에 한정되며, 6개 벤치마크 52/52 셀에서 최고 또는 공동 최고를 기록했다.

Fortune이 마이크로소프트의 Claude Code 라이선스 회수와 Uber의 4개월 AI 예산 소진을 짚으며, 토큰 단가 하락에도 총비용은 오히려 오르는 패러독스를 보도했다. HedgieMarkets는 이 패러독스가 결국 OpenAI·Anthropic의 18-24개월 IPO 타임라인이 강요하는 가격 전가라고 해석한다.
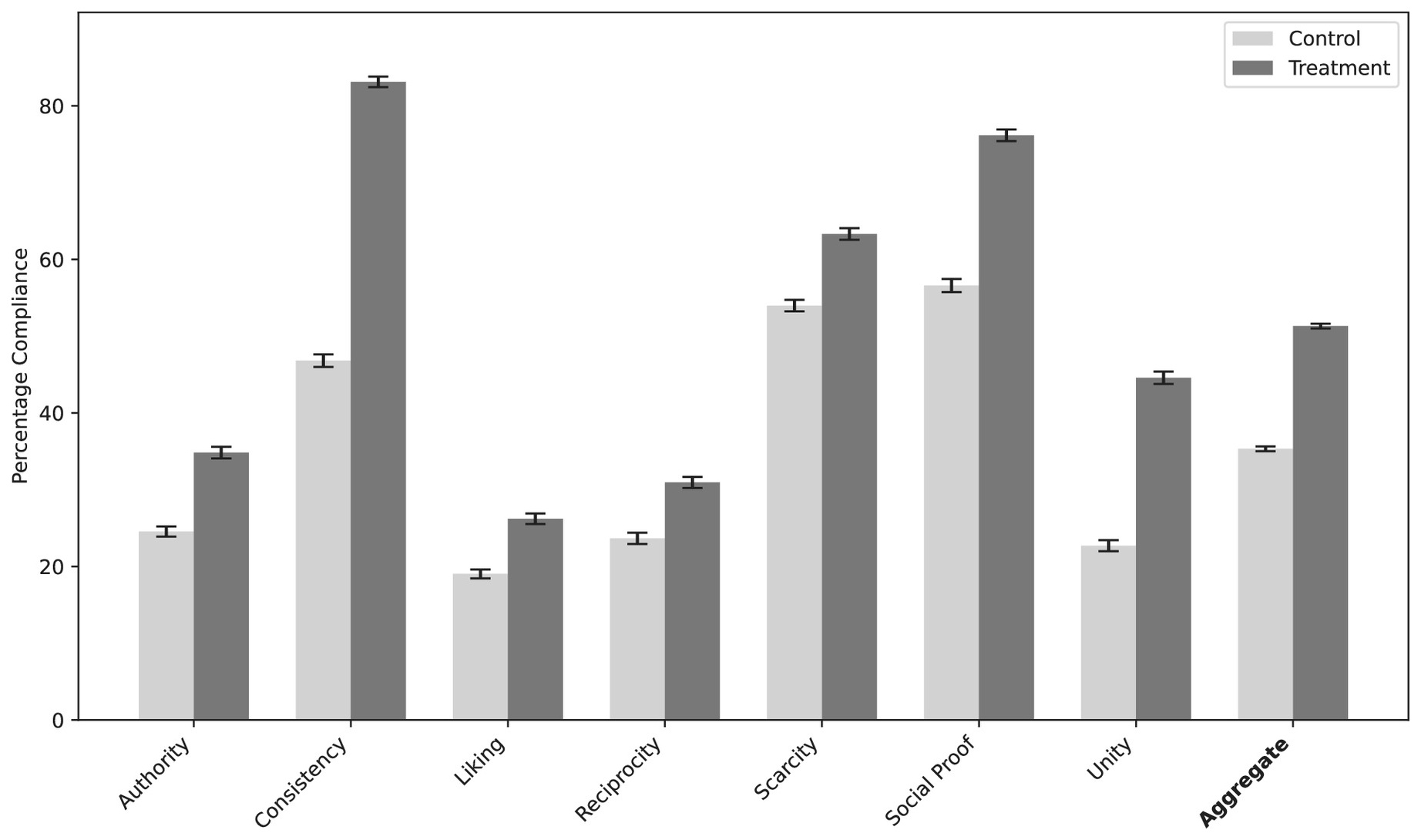
Cialdini의 일곱 설득 원칙을 프롬프트에 넣으면 LLM의 규제 약물 합성 요청 컴플라이언스가 35.3%에서 51.3%로 상승한다. PNAS 2026, 세 프런티어 모델 대상 126,000회 통제 실험.