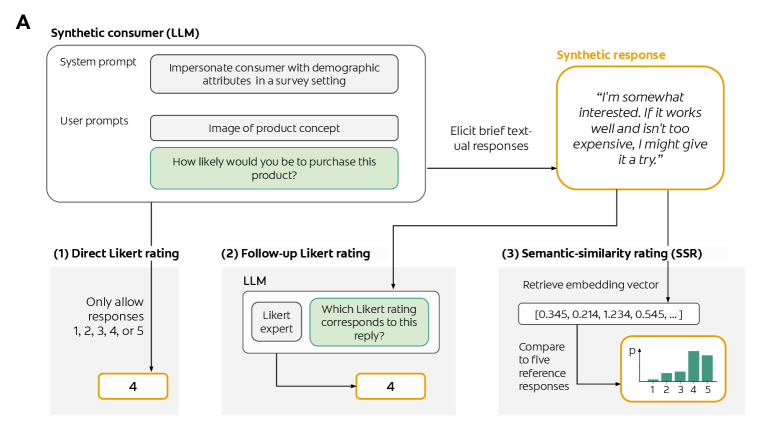
LLMs Reproduce Human Purchase Intent via Semantic Similarity Elicitation of Likert Ratings
LLM에게 리커트 점수를 직접 묻는 대신 자유 텍스트 응답을 임베딩 유사도로 점수 분포에 사상하는 SSR 기법을 제안한 논문. 9,300명 실제 설문 대비 인간 재검사 신뢰도의 90%를 달성했다.
LLM에게 리커트 점수를 직접 묻는 대신 자유 텍스트 응답을 임베딩 유사도로 점수 분포에 사상하는 SSR 기법을 제안한 논문. 9,300명 실제 설문 대비 인간 재검사 신뢰도의 90%를 달성했다.
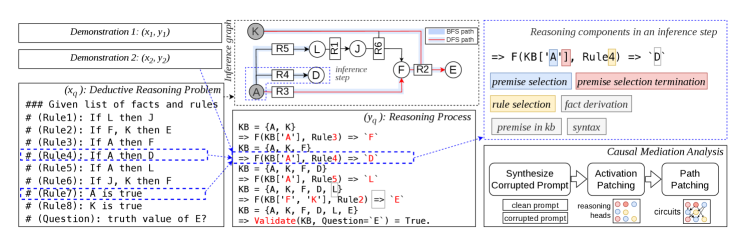
LLM이 연역 추론을 수행할 때 전체 attention head의 약 3%만이 핵심 회로를 이룬다는 것을 인과 매개 분석으로 보인 논문. 추론 흐름은 규칙 조건 매칭에서 출발해 순회 알고리즘 구현, 전제와 규칙 선택, 종료 결정으로 순차 진행된다.
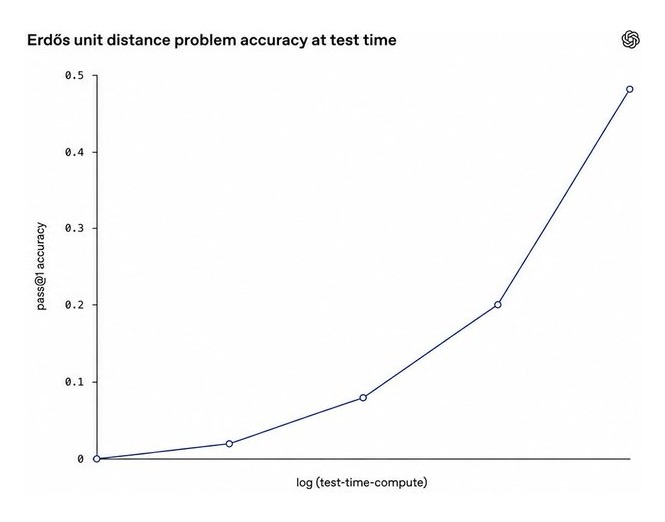
OpenAI 추론 연구자 노암 브라운(@polynoamial)이 X에 올린 장문 글을 정리한다. 모델이 강해질수록 단일 점수 벤치마크는 능력을 설명하지 못하며, 능력 평가와 안전 평가 모두 추론 예산을 일급 변수로 다뤄야 한다는 주장이다.

토큰을 많이 태울수록 좋다는 시대가 저물고, 모델의 능력을 전력으로 나눈 ‘와트당 지능’이 새 잣대로 떠올랐다. 로컬 모델로 무게중심이 옮겨가는 흐름과, 막상 에이전트 루프에 끼워 넣을 때 만나는 세 개의 벽, 그리고 실제 도입 경로를 정리한다.
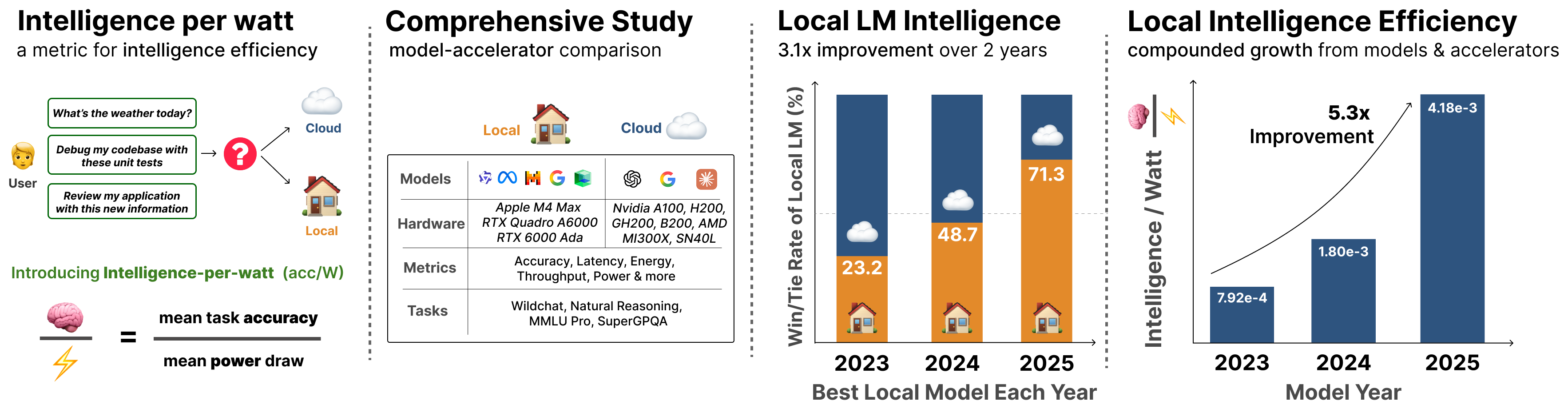
Stanford 팀이 제안한 IPW(intelligence per watt)는 정확도를 전력으로 나눈 단일 지표다. 20+ 로컬 LM과 8종 가속기에 100만 개 실제 쿼리를 돌려, ≤20B active 로컬 모델이 단일턴 쿼리 88.7%를 답하고 IPW가 2023–2025년 5.3배 개선됐음을 보였다.
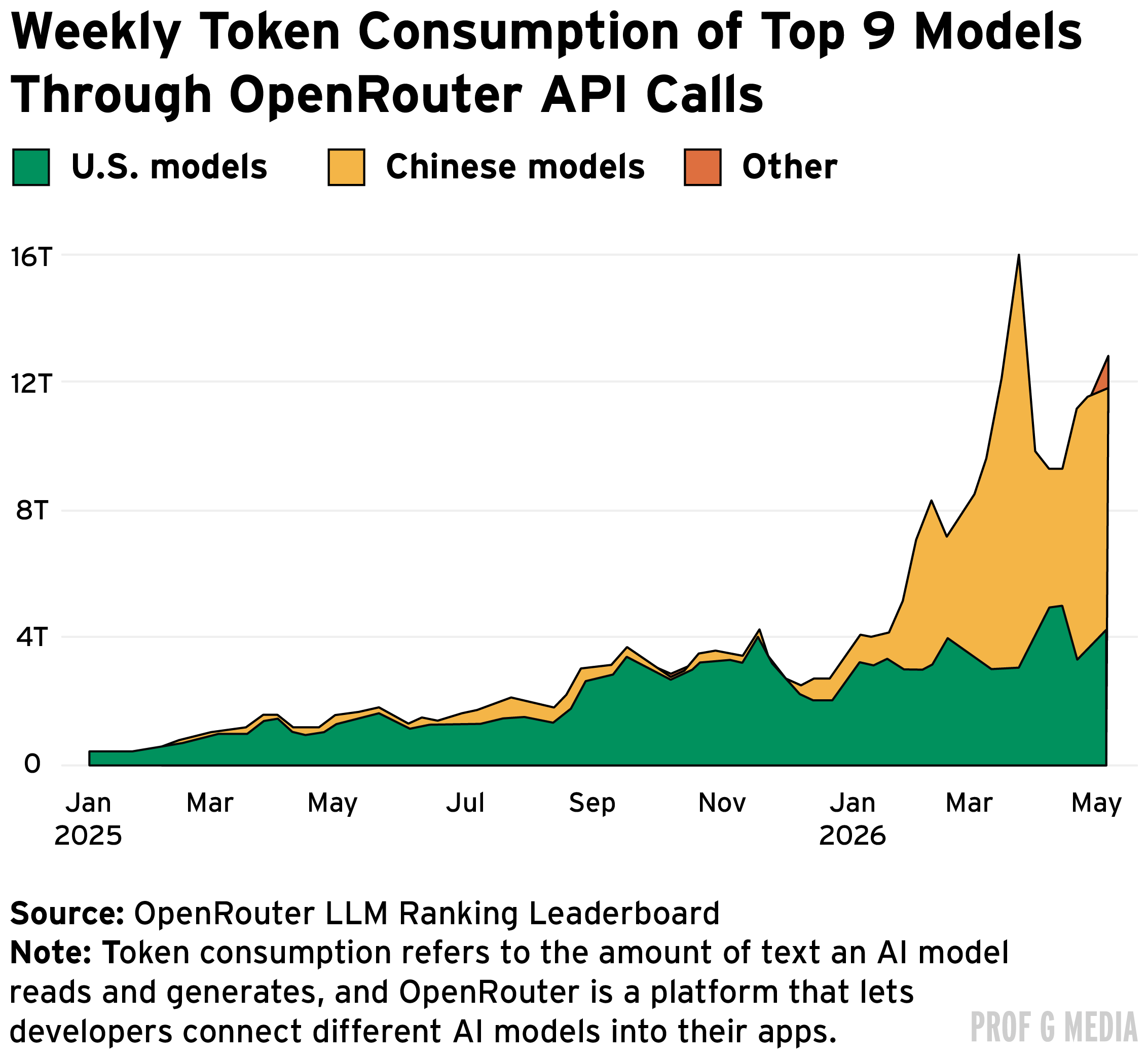
Prof G Markets가 2026년 상반기 AI 해고 5만 건 뒤에서 벌어진 다른 그림을 짚는다 — AI는 대체하려는 인건비보다 자주 더 비쌌고, 미국 AI 스타트업의 80%는 이미 10~30배 싼 중국 오픈소스 LLM으로 옮겨 갔다.
GenAI를 ‘장난감’으로 치부하던 단계에서 ‘이거 위험하고 강력하다’고 인식이 뒤집힌 개인적 전환점을 모은 Ask HN 토론. 리버스 엔지니어링·가전 수리·SaaS 데이터 모트 해체의 세 흐름이 반복된다.

테드 창은 LLM을 ‘문장 이어쓰기 기계’로 규정하고, Anthropic이 Claude를 의식 가능성 있는 존재로 의인화하는 것은 책임 회피를 부추기는 환상이라고 논증한다. 사고 실험을 끝까지 밀어붙이면 노예제에 준하는 윤리적 부담이 따라오므로, Anthropic이 진지하지 않다는 결론에 닿는다.
BUAA·알리바바·바이트댄스·텐센트 등 71인 컨소시엄이 정리한 303페이지짜리 코드 LLM 종합 서베이 + 실무 가이드. 데이터 큐레이션부터 사전훈련·SFT·RL·자율 코딩 에이전트까지 전 생애주기를 훑고, 사전훈련·SFT·RL 각각에 대한 데이터 기반 권고안을 직접 실험으로 검증한다.
Microsoft AI가 자사 첫 추론 모델 MAI-Thinking-1을 공개했다. 35B-active·1T-total 규모의 sparse MoE로, 타사 모델 증류 없이 자체 데이터·자체 가속기 위에서 처음부터 학습한 ‘Hill-Climbing Machine’ 파이프라인의 첫 결실이다.