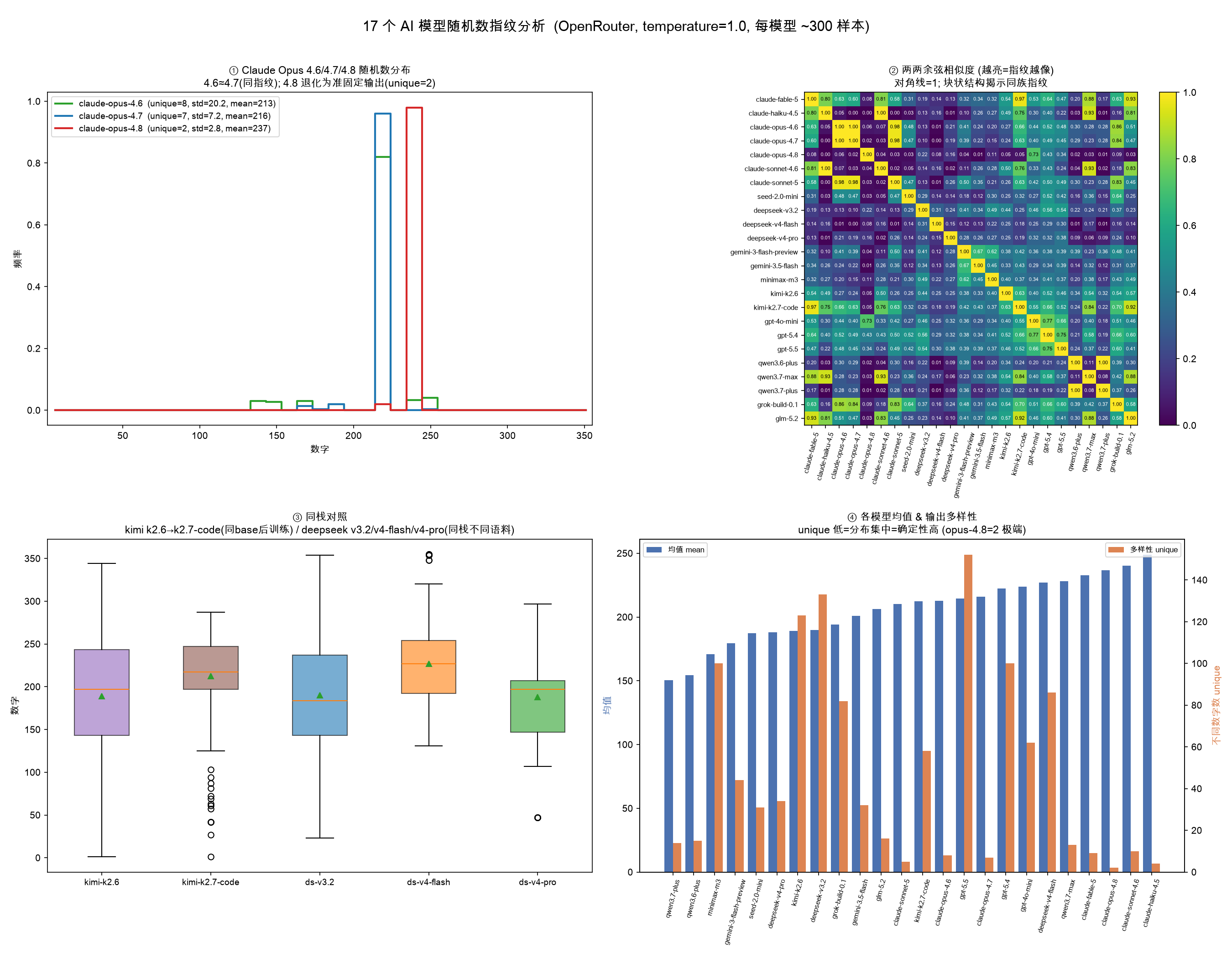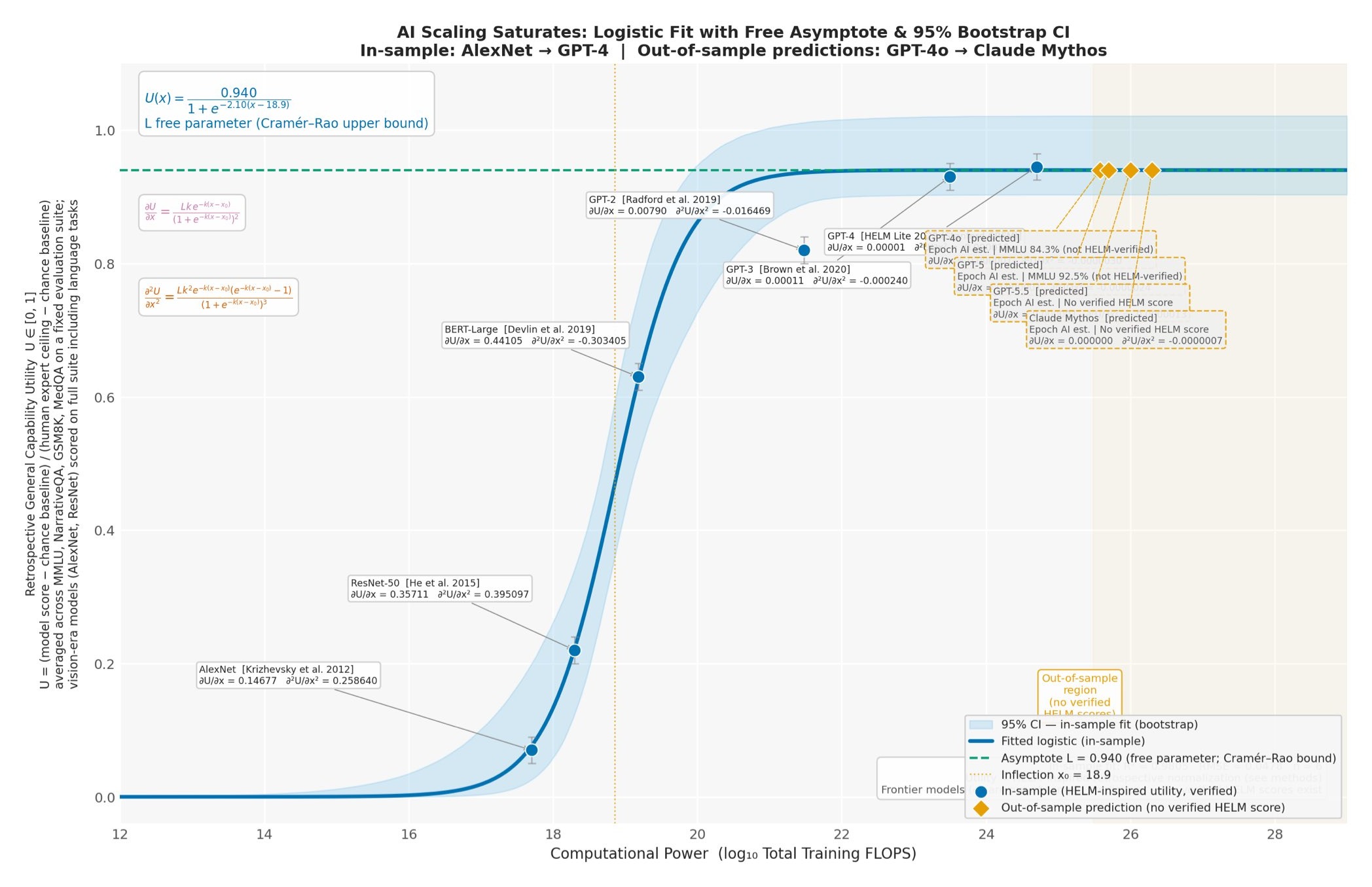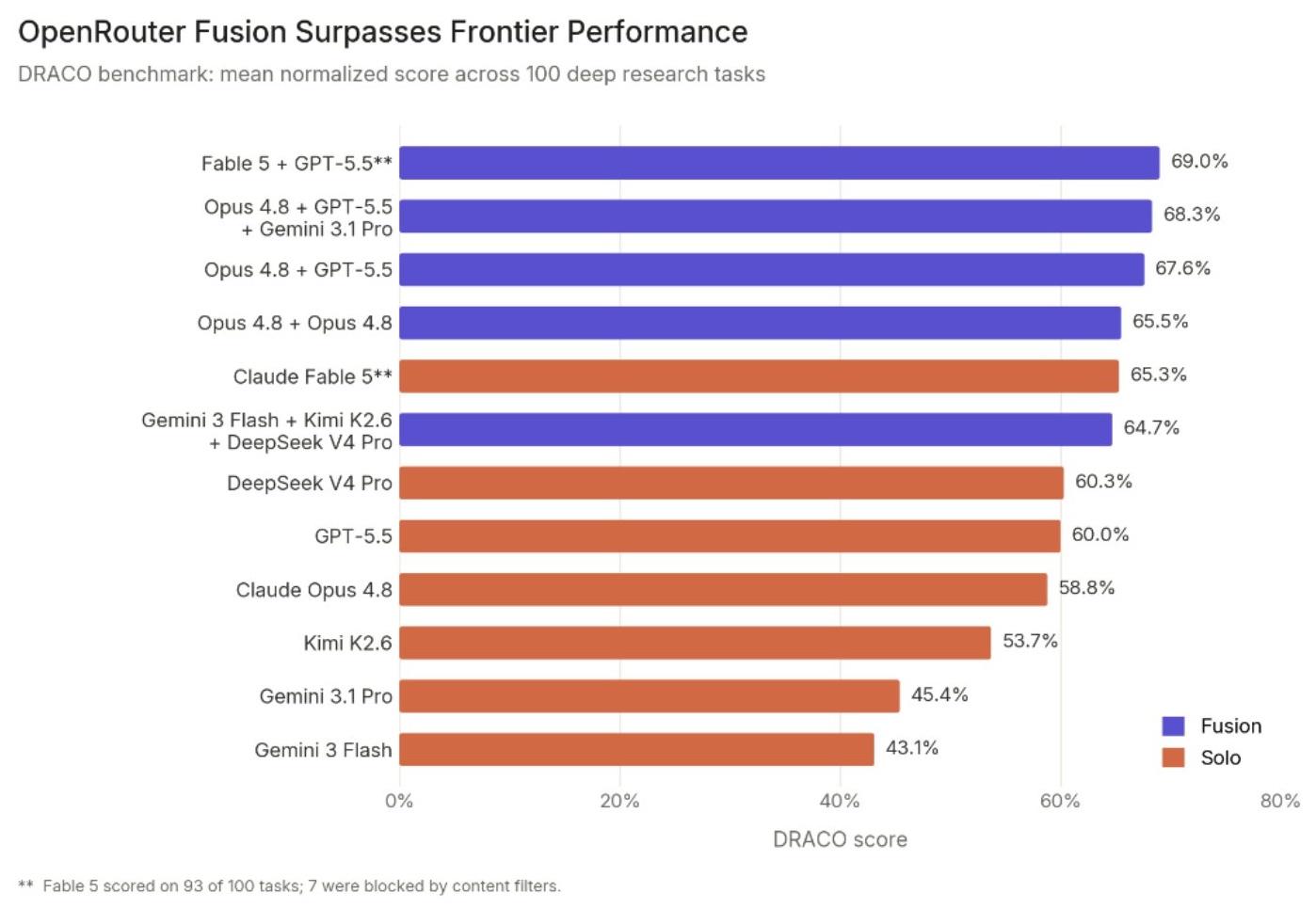
When Does Combining Language Models Help? A Co-Failure Ceiling on Routing, Voting, and Mixture-of-Agents Across 67 Frontier Models
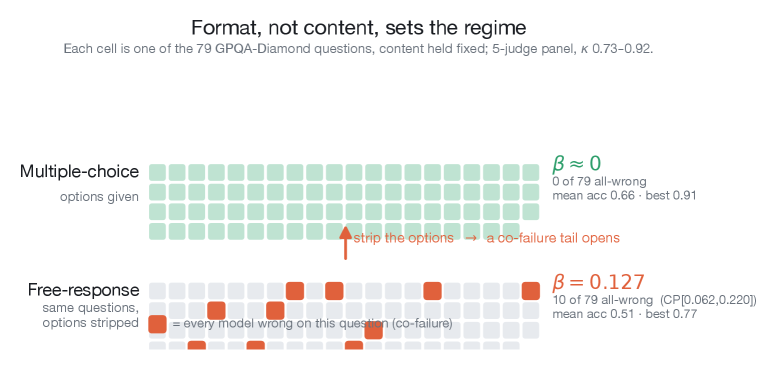
라우팅·다수결·캐스케이드·MoA 등 어떤 LLM 오케스트레이션도 β(모든 모델이 같은 질의에서 함께 실패하는 비율)로 상한이 정해진다. 관행적으로 보고되는 pairwise error correlation ρ는 β를 원리적으로 볼 수 없다. 67개 프론티어 모델·21개 프로바이더에서 tetrachoric 단일요인 모델도 실측 β를 2.5배 과소예측했고, 같은 GPQA 문항을 free-response로 재출제하면 β=0이 0.127로 열린다.