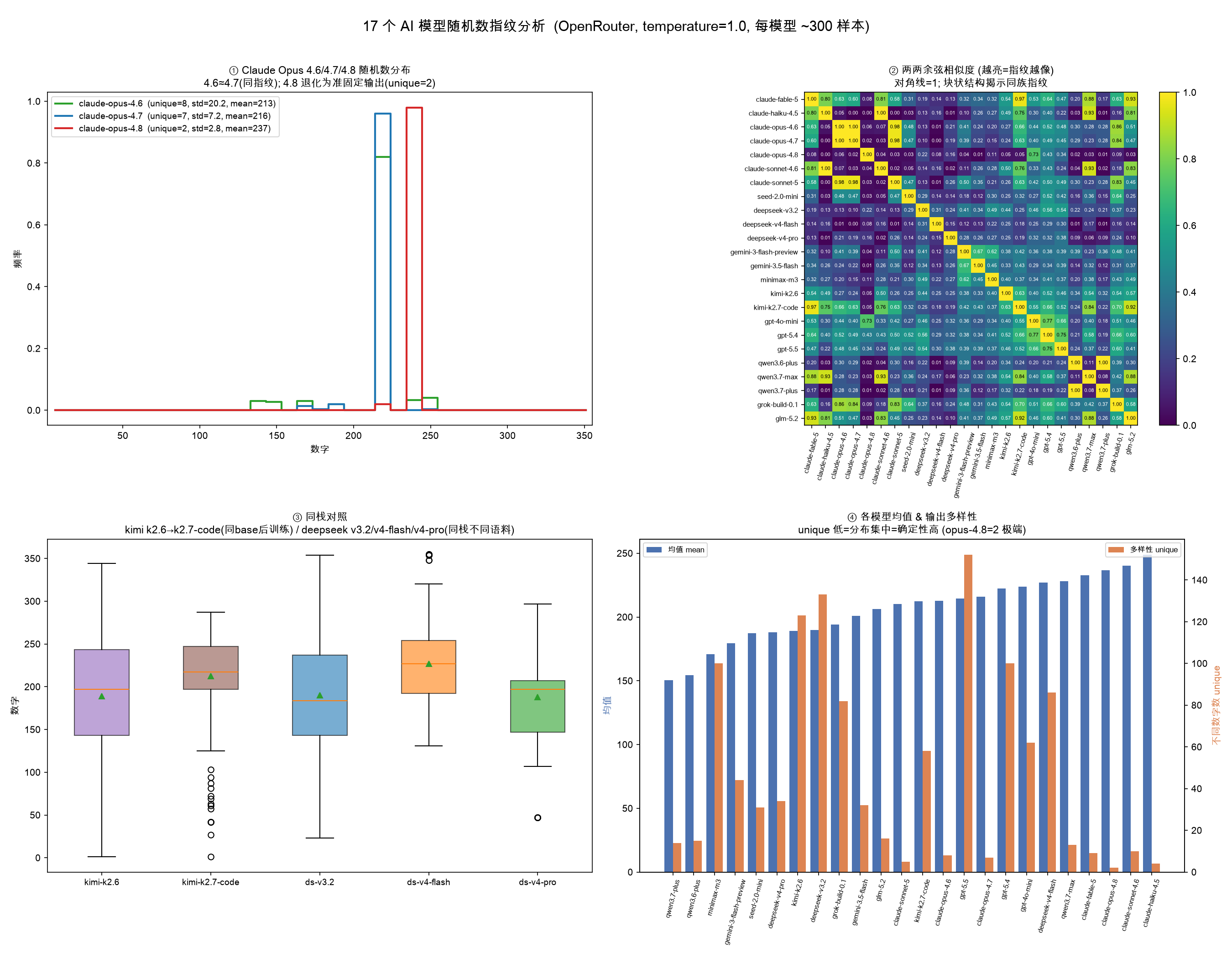
AI 모델 랜덤 넘버 지문 데이터셋
1부터 355 사이의 랜덤한 수를 뽑으라는 프롬프트를 대량 반복시켜 얻은 통계 분포로 24개 AI 모델의 지문을 만들고, 그 지문으로 제3자 API 중계의 모델 위조까지 잡아낸 실측 데이터셋.
1부터 355 사이의 랜덤한 수를 뽑으라는 프롬프트를 대량 반복시켜 얻은 통계 분포로 24개 AI 모델의 지문을 만들고, 그 지문으로 제3자 API 중계의 모델 위조까지 잡아낸 실측 데이터셋.
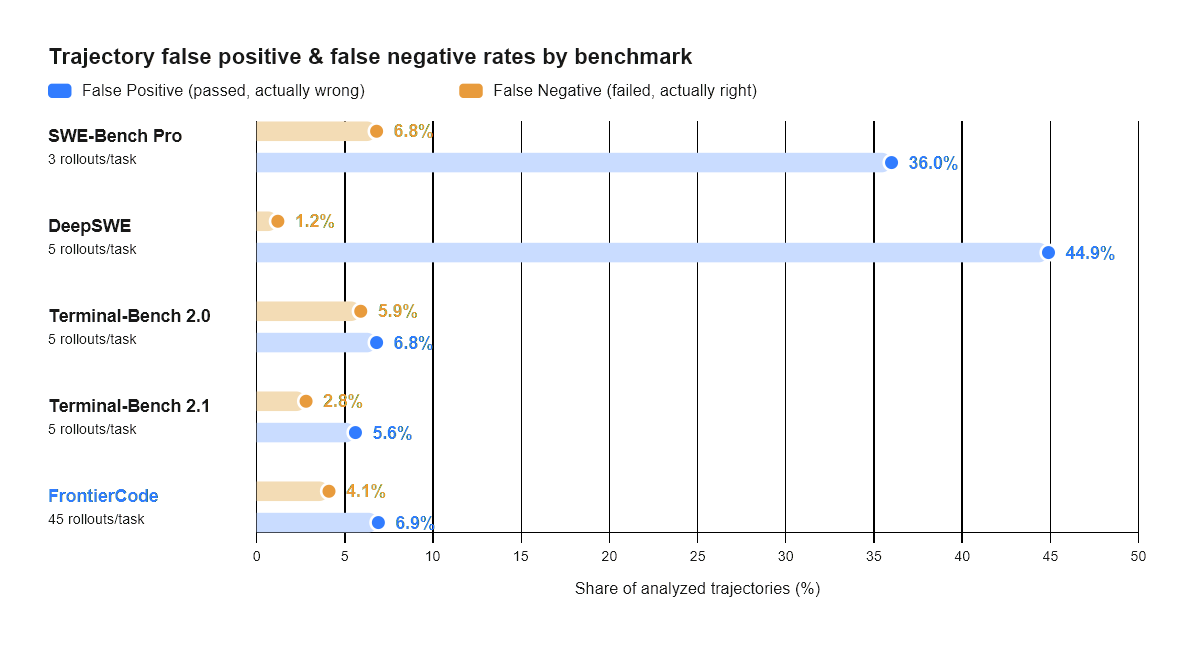
Cognition이 공개한 신규 코딩 벤치마크. 정답 여부가 아니라 ‘메인테이너가 실제로 머지하겠는가’를 측정한다. Diamond 50문항에서 최강 모델 Claude Opus 4.8도 13.4%에 그쳤다.
ARC Prize가 GPT-5.5와 Opus 4.7을 ARC-AGI-3으로 평가한 분석 보고서. 두 모델 모두 1% 미만의 점수를 기록했지만, 진짜 발견은 점수가 아니라 실패의 질적 차이에 있다.
Anthropic이 공개한 99문제 바이오인포매틱스 벤치마크 BioMysteryBench. 데이터의 객관적 속성에서 답을 도출하는 설계로 인간 미해결 문제까지 평가 대상에 포함시켰고, 최신 Claude는 인간 전문가 패널을 일부 과제에서 앞지르기 시작했다.