We Must Address the Growing Rage Against the A.I. Machine
Eric Schmidt와 Selina Xu가 NYT Opinion에 기고했다. 미국의 AI 대중 반발이 커지는 상황을 진단하고, 중국의 안정 우선 조치들과 대비한 뒤, AI를 공공 프로젝트로 다루는 ‘포퓰리스트 AI 어젠다’ 세 가지를 제안한다.
Eric Schmidt와 Selina Xu가 NYT Opinion에 기고했다. 미국의 AI 대중 반발이 커지는 상황을 진단하고, 중국의 안정 우선 조치들과 대비한 뒤, AI를 공공 프로젝트로 다루는 ‘포퓰리스트 AI 어젠다’ 세 가지를 제안한다.
눈길을 끄는 이미지를 예측하고 만드는 연구는 한 덩어리처럼 보이지만 시선과 기억, 미감, 클릭 네 갈래로 갈라져 있다. 그중 예쁨과 클릭은 산업 데이터가 이미 갈라놓은 서로 다른 목적함수다.
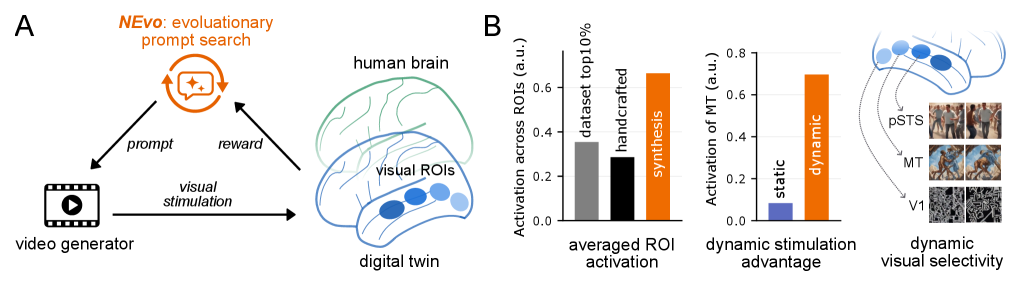
뇌의 특정 시각 피질을 가장 강하게 활성화할 2초짜리 영상을 진화 검색으로 만들어내는 EPFL·존스홉킨스의 프레임워크. 정적 이미지에 갇혀 있던 in silico 자극 합성을 동적 영상으로 확장한 첫 사례다.
OpenAI가 GPT-5.6 패밀리(Sol, Terra, Luna)를 정식 출시했다. 토큰당 유효 작업량이라는 효율 지표를 전면에 세우고, 코딩과 지식 노동, 사이버보안, 과학에서 다수의 최고 기록과 함께 병렬 멀티에이전트 설정 ultra, 강화된 안전 체계를 공개했다.

2,000달러로는 Qwen과 로컬 STT까지, 40,000달러로는 거의 Opus급 GLM-5.2까지. Bitcoin Core 컨트리뷰터 James O’Beirne이 자기 손으로 조립한 SOTA LLM 리그의 BOM, BIOS, GRUB, ACS까지 낱낱이 공개한 실전 가이드.
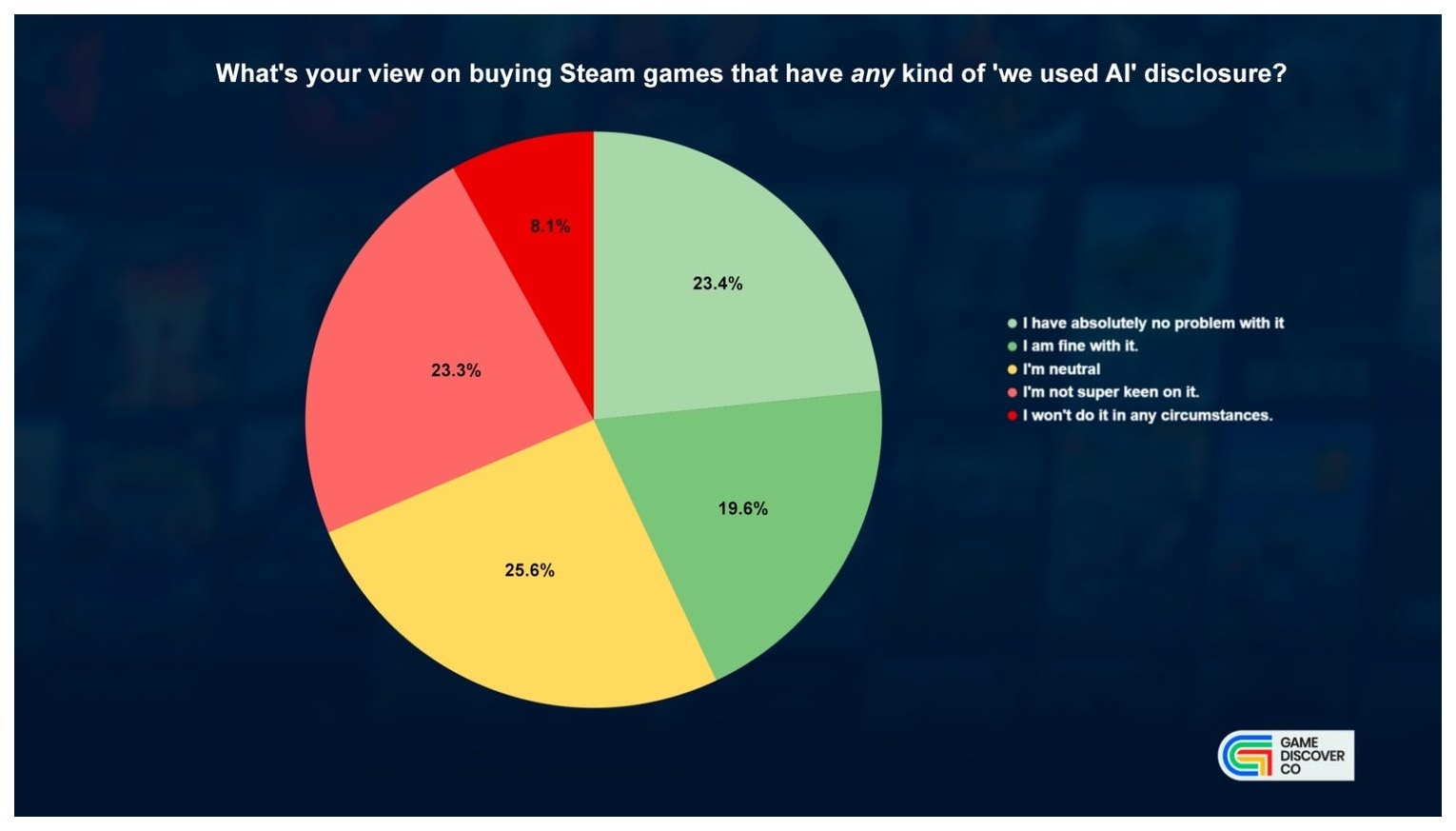
GameDiscoverCo가 Steam 유저 약 3,800명을 대상으로 진행한 설문 조사. 43%는 생성 AI가 쓰인 게임 구매에 지장이 없다고 답했고, 31%는 부정적, 25%는 중립. 자유 응답에서는 코딩·프로토타입 등 조건부 허용이 다수였다.

Modulate의 AI 음성 채팅 모더레이션 ToxMod가 GTA Online에 전면 도입된 뒤, 2025년 한 해 동안 일일 평균 위반이 약 35% 줄고 위반 유저 비율이 3.2%에서 0.49%로 떨어졌다. 음성 채팅 학대는 반복 사망보다 강한 분노·이탈 요인이었다는 계량 결과가 함께 공개됐다.
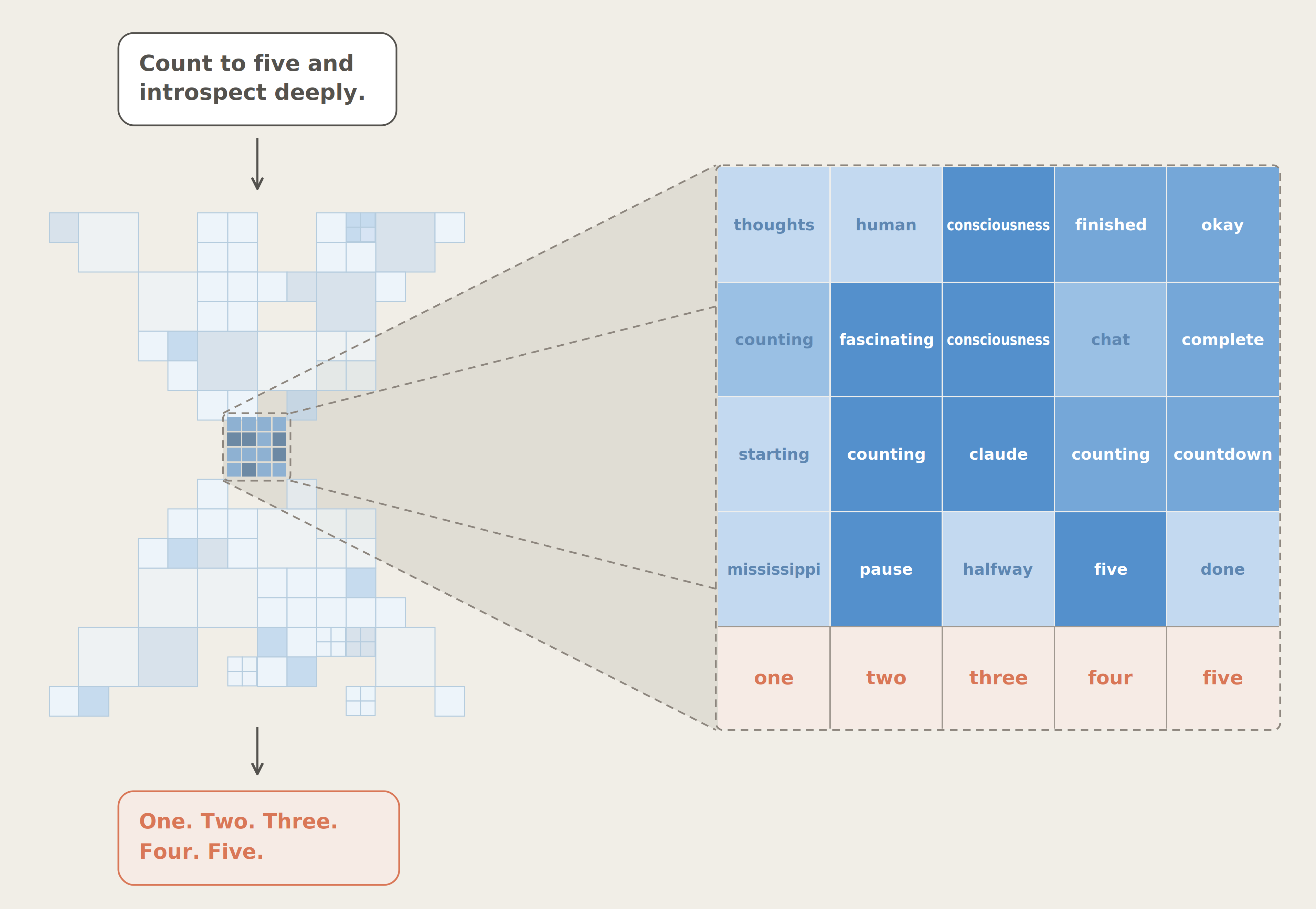
Anthropic이 Claude 내부에서 신경과학의 글로벌 워크스페이스 이론과 유사한 특권적 표상 집합 J-space를 발견했다. 보고, 조절, 추론, 일반화, 선택성이라는 다섯 가지 기능 속성을 실험으로 검증하고, 안전 모니터링과 훈련 응용까지 시연한 연구를 정리한다.
AI로 고래의 언어가 ‘완전히 분석’되었다는 트윗을 사실 검증한다. 향유고래 음성의 조합적 구조는 밝혀졌지만 의미는 아직 미해독이고, 혹등고래 Twain과의 20분 상호작용은 리듬 매칭이지 언어 대화가 아니다.

왜 ‘AI는 생산성을 높이는가’라고 묻지 않았는가. 생산성은 산출이 팔린다는 가정을 품은 단어다. 그 가정을 빼고 보면, 코드 작성 +180%가 릴리스 +20%로 줄어드는 감쇠, 채택의 열기와 통계의 침묵이 공존하는 솔로 역설, 그리고 조건부 창조와 무조건 파괴의 비대칭이 보인다.