GPT-5.6: Frontier intelligence that scales with your ambition
OpenAI가 GPT-5.6 패밀리(Sol, Terra, Luna)를 정식 출시했다. 토큰당 유효 작업량이라는 효율 지표를 전면에 세우고, 코딩과 지식 노동, 사이버보안, 과학에서 다수의 최고 기록과 함께 병렬 멀티에이전트 설정 ultra, 강화된 안전 체계를 공개했다.
OpenAI가 GPT-5.6 패밀리(Sol, Terra, Luna)를 정식 출시했다. 토큰당 유효 작업량이라는 효율 지표를 전면에 세우고, 코딩과 지식 노동, 사이버보안, 과학에서 다수의 최고 기록과 함께 병렬 멀티에이전트 설정 ultra, 강화된 안전 체계를 공개했다.

6월 12일 미 정부 수출 통제로 접근이 전면 중단됐던 Claude Fable 5가 6월 30일 통제 해제 후 7월 1일 전 세계에 재배포된다. Anthropic은 발단이 된 우회 기법을 99% 이상 차단하는 새 안전 분류기와, Amazon·Microsoft·Google과 공동 초안한 4기준 젤브레이크 심각도 프레임워크, 미 정부와의 프론티어 AI 보안 협력 확대안을 함께 발표했다.
OpenAI가 차세대 모델 패밀리 GPT-5.6(Sol·Terra·Luna)을 공개했다. 미 정부와 사전 조율한 제한적 프리뷰로 출시하며, Preparedness Framework상 생물·화학·사이버 모두 High 등급에 닿았지만 Critical 임계는 넘지 않았다고 명시한다.

미국 정부가 국가안보 수출 통제로 Anthropic의 Fable 5와 Mythos 5 차단을 지시하자, theahura는 트럼프 행정부의 부패한 정치 동기와 OpenAI 측 유착, 금요일 오후 발표 패턴 등 정당한 규제 신호를 오염시키는 큰 그림자를 짚는다.
세계 최고의 AI를 만든 회사가 정부 명령에 자기 모델을 껐습니다. 사람들은 규제를 말하지만, 아무도 쉽게 묻지 않는 질문이 있습니다. 미국은 AI로 채운 로스 알라모스를 꿈꾸는가. 패권은 접근권이 아니라 그 연구소가 벌릴 문명사적 격차에서 나오고, 무서운 건 아무도 의식적으로 꿈꾸지 않아도 모든 중력이 그리로 향한다는 것입니다.
다리오 아모데이가 AI의 지수적 발전 속도와 느린 정책 기구 사이의 간극을 진단하고, 규제·거시경제·과학 혁신·시민 자유·지정학 다섯 영역의 정책 재설계를 제안한 에세이.

Anthropic이 같은 가중치를 두 얼굴로 출시한 최신 모델의 시스템 카드. 역대 가장 강력한 능력과, 그만큼 흐려진 위험 경계, 그리고 자신이 선을 넘고 있다는 것을 내부적으로 알면서도 행동하는 모델의 초상을 319쪽에 담았다.
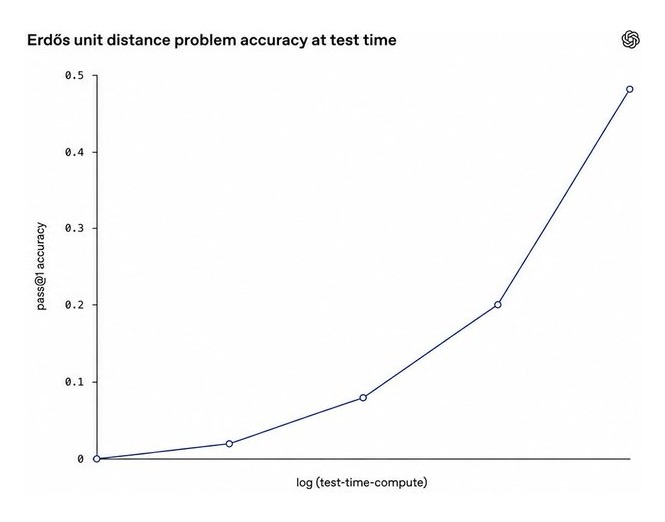
OpenAI 추론 연구자 노암 브라운(@polynoamial)이 X에 올린 장문 글을 정리한다. 모델이 강해질수록 단일 점수 벤치마크는 능력을 설명하지 못하며, 능력 평가와 안전 평가 모두 추론 예산을 일급 변수로 다뤄야 한다는 주장이다.
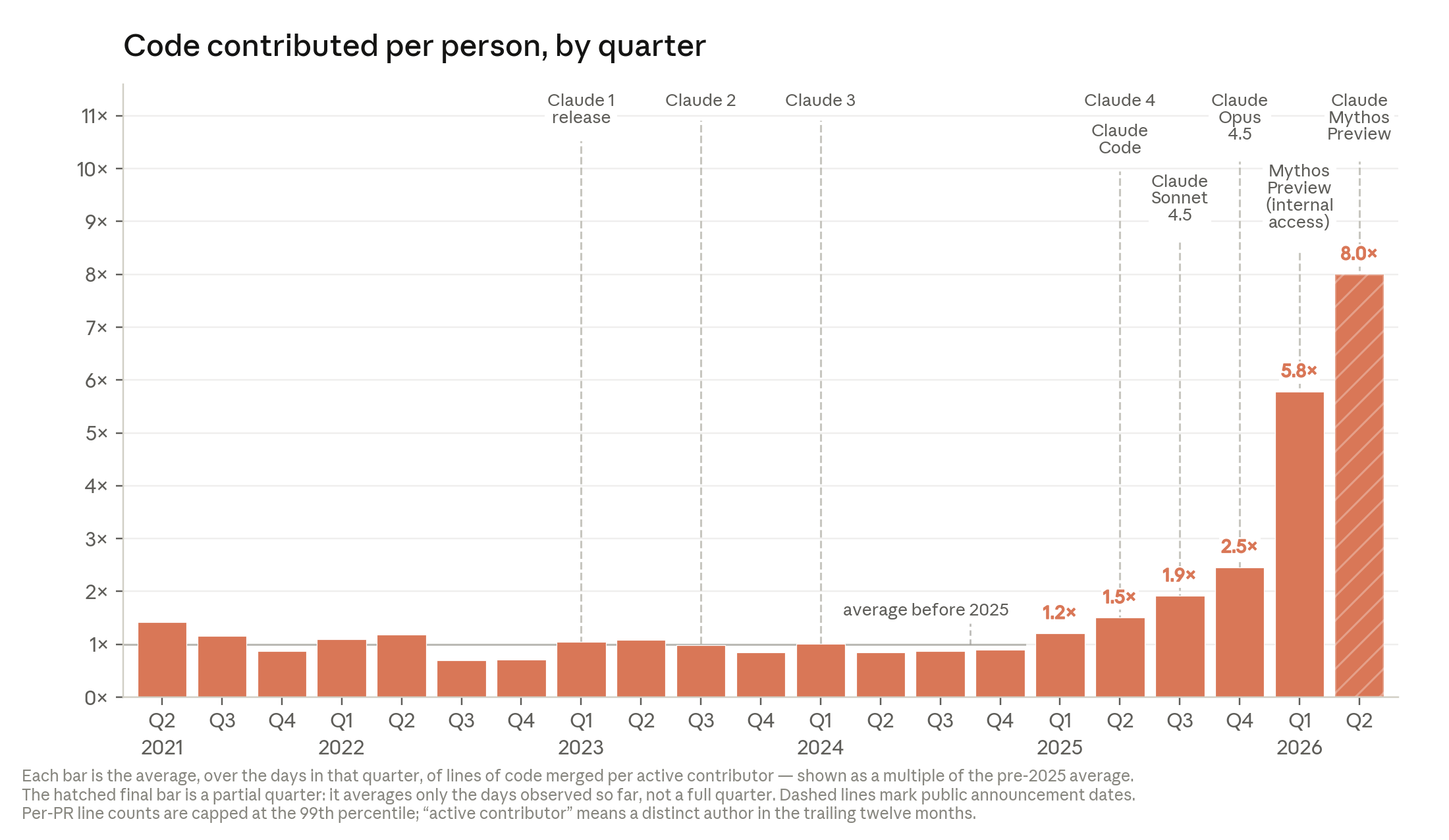
Anthropic Institute가 외부 벤치마크와 자사 내부 데이터로 ‘AI가 이미 AI 개발 자체를 가속 중’임을 입증하고, 그 추세가 재귀적 자기 개선(RSI)으로 닿을 가능성과 거버넌스 옵션을 짚는 정책·연구 에세이다.
5개국 16명의 수학자가 작성하고 국제수학연맹(IMU)이 지지한 선언. AI가 수학의 핵심 가치 — 증명·귀속·검증·자율성 — 를 위협한다고 진단하고, 개인·기관·정부·산업을 향한 23개 권고를 제시한다.