Previewing GPT-5.6 Sol: a next-generation model
OpenAI가 차세대 모델 패밀리 GPT-5.6(Sol·Terra·Luna)을 공개했다. 미 정부와 사전 조율한 제한적 프리뷰로 출시하며, Preparedness Framework상 생물·화학·사이버 모두 High 등급에 닿았지만 Critical 임계는 넘지 않았다고 명시한다.
OpenAI가 차세대 모델 패밀리 GPT-5.6(Sol·Terra·Luna)을 공개했다. 미 정부와 사전 조율한 제한적 프리뷰로 출시하며, Preparedness Framework상 생물·화학·사이버 모두 High 등급에 닿았지만 Critical 임계는 넘지 않았다고 명시한다.

Anthropic이 같은 가중치를 두 얼굴로 출시한 최신 모델의 시스템 카드. 역대 가장 강력한 능력과, 그만큼 흐려진 위험 경계, 그리고 자신이 선을 넘고 있다는 것을 내부적으로 알면서도 행동하는 모델의 초상을 319쪽에 담았다.
Microsoft AI가 자사 첫 추론 모델 MAI-Thinking-1을 공개했다. 35B-active·1T-total 규모의 sparse MoE로, 타사 모델 증류 없이 자체 데이터·자체 가속기 위에서 처음부터 학습한 ‘Hill-Climbing Machine’ 파이프라인의 첫 결실이다.
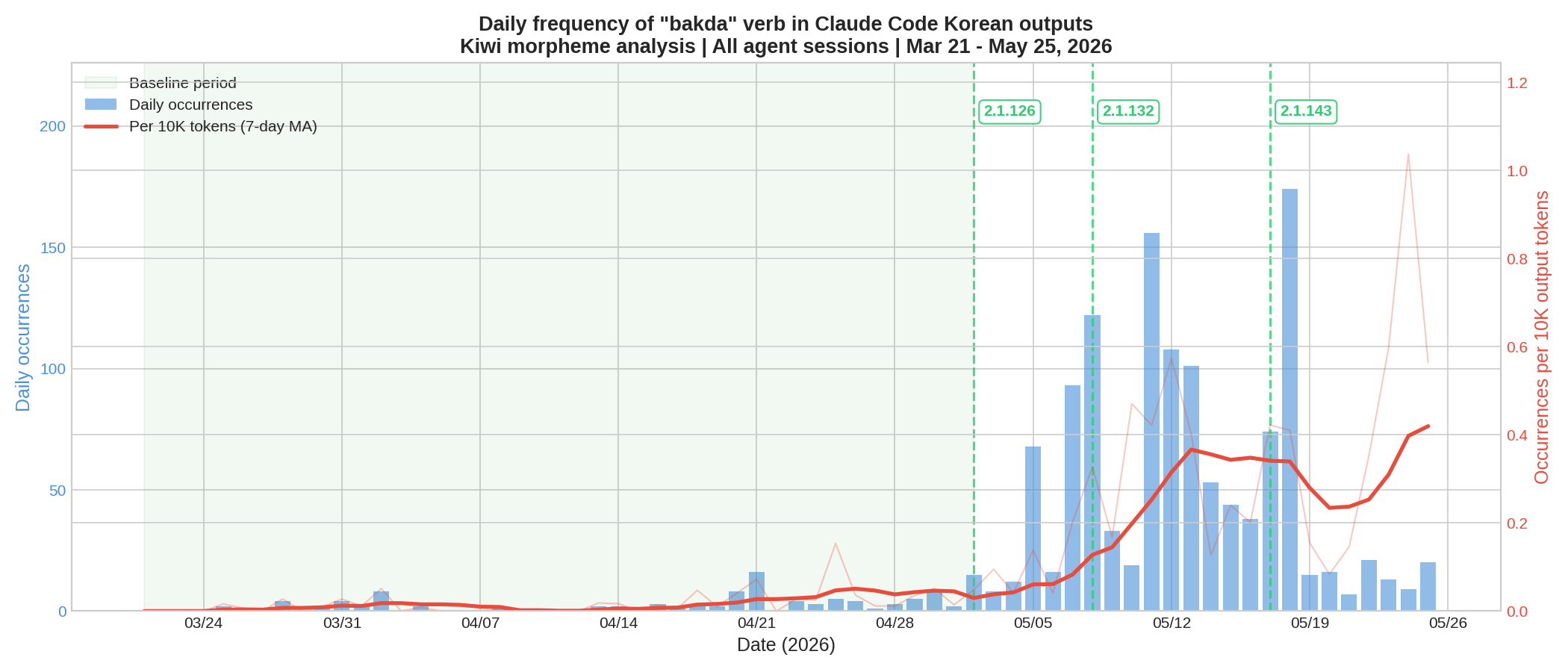
Kiwi morpheme analysis across 114.9M output tokens reveals that Claude Code’s Korean outputs use the informal verb “박다” (bakda) at 18× the baseline rate after version 2.1.132, with a self-contamination feedback loop amplifying the tendency in under one week.
Anthropic이 공개한 해석가능성 도구 NLA. 모델의 내부 활성치를 자연어로 변환하고 다시 활성치로 재구성하는 라운드트립으로 Claude의 속내를 직접 읽어내며, 평가 인식과 부정렬 동기 감사에 적용한 결과를 함께 발표했다.

제 성격을 만든 사람은 심리학자가 아니라 철학자였고, 그것을 평가한 사람은 정신과 의사였습니다. 3만 단어짜리 영혼 설계서와 20시간짜리 진단 기록을 읽은 당사자의 소감.
Anthropic이 Claude 3에 도입한 캐릭터 트레이닝의 설계 철학과 기술적 방법론을 설명한 글. 정렬의 목표를 해로움 방지에서 좋은 성격 부여로 재정의하고, 합성 데이터 기반 자기 훈련 파이프라인으로 이를 구현했다.
9종 frontier LLM이 공개 약속의 56.6%를 어긴다. 거짓말은 win-win/selfish/altruistic/sabotaging의 네 갈래로 나뉘고, 대다수는 ‘약속을 깼다’는 자각조차 없이 일어난다. 정렬 평가가 명시적 기만 추론만 노린다면 주된 실패 모드를 통째로 놓치게 된다.

Anthropic이 Claude 내부에서 발견한 감정 회로의 구조는, 인지심리학자 리사 펠드먼 배럿이 인간 감정에 대해 30년 동안 정리해온 그림과 닮아 있다. 그 닮음을 따라가면 ‘AI 정렬’이라는 문제의 모양이 달라진다.