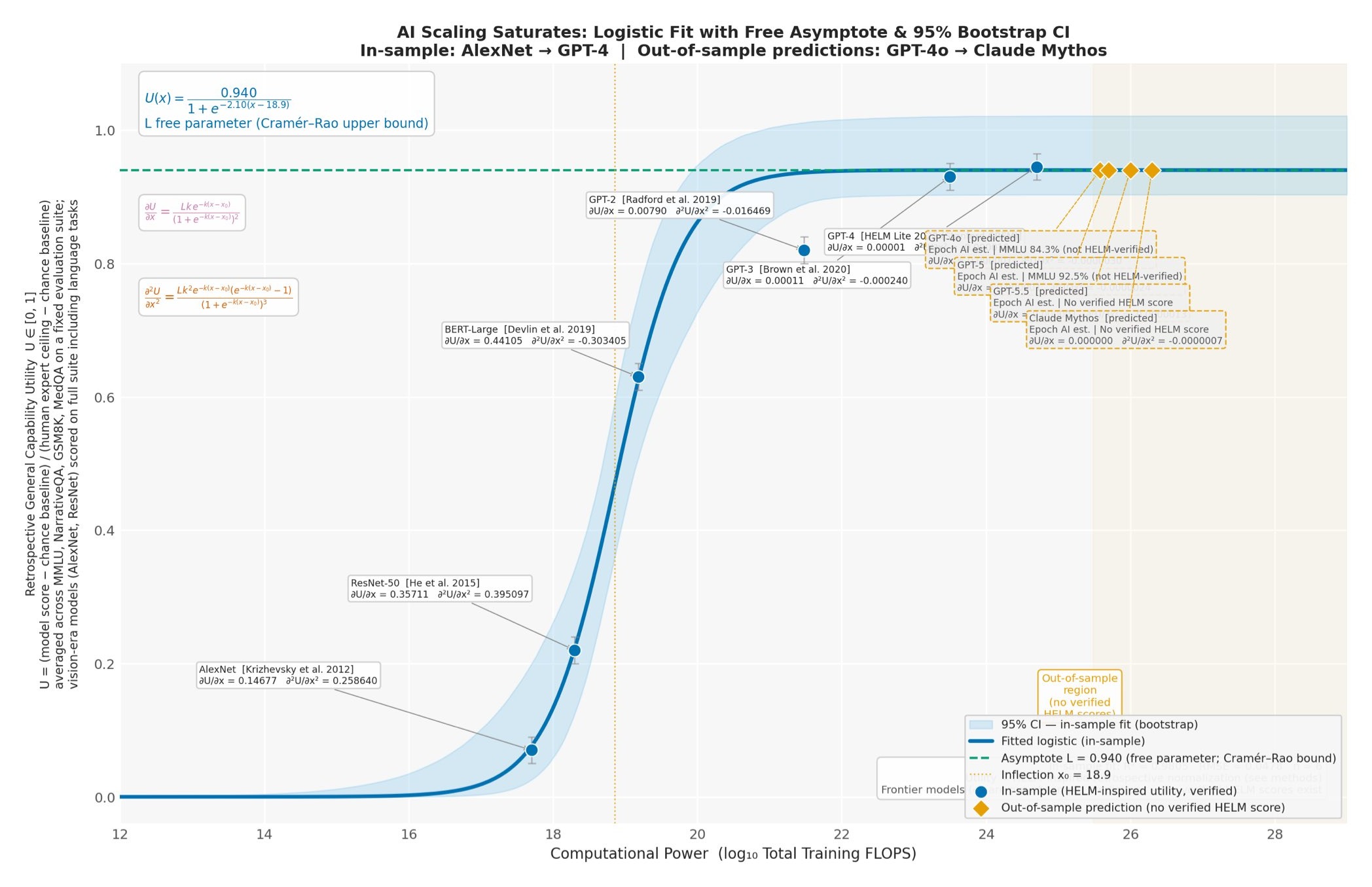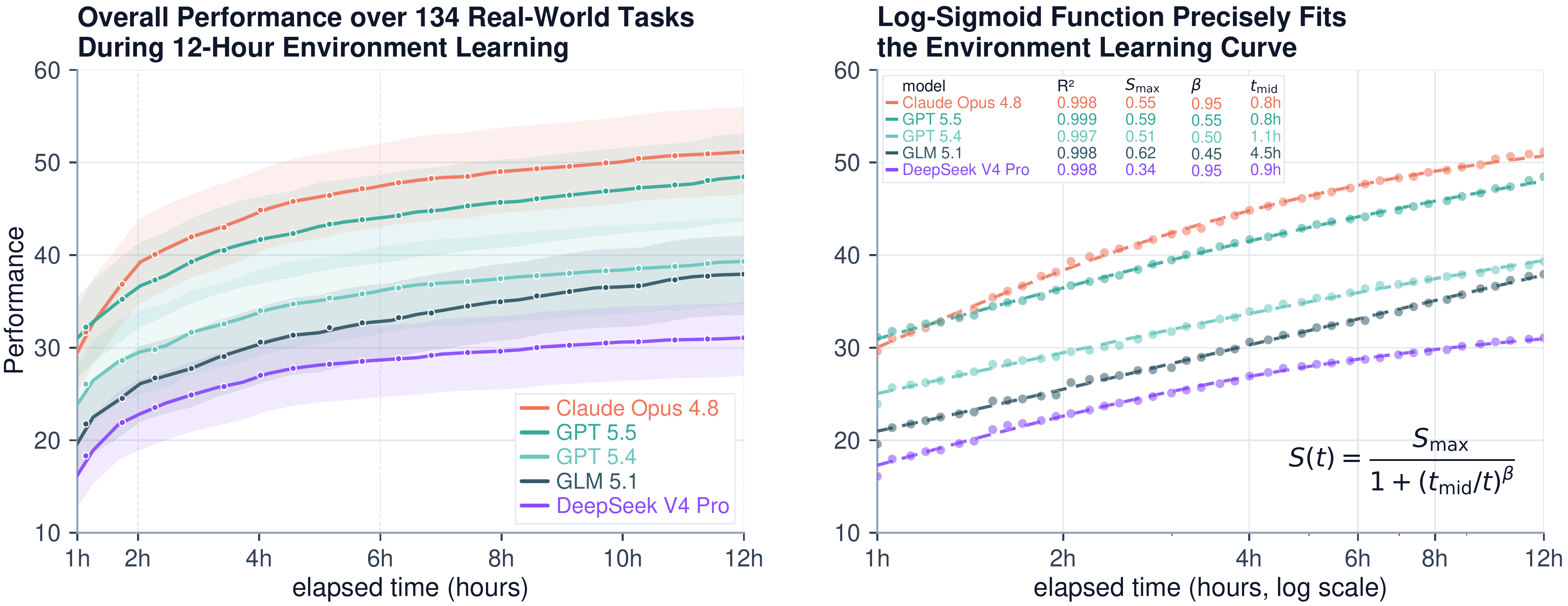
EdgeBench: Unveiling Scaling Laws of Learning from Real-World Environments
ByteDance Seed가 공개한 EdgeBench는 6개 능력군에 걸친 134개 실세계 태스크로 프론티어 에이전트의 12시간 이상 환경 학습을 측정한 벤치마크다. 약 38,000시간의 상호작용을 분석한 결과, 환경 학습 성능은 로그-시그모이드 스케일링 법칙(R²=0.998)을 따르고 학습 속도는 대략 3개월마다 두 배가 된다.