GPT-5.6: Frontier intelligence that scales with your ambition
OpenAI가 GPT-5.6 패밀리(Sol, Terra, Luna)를 정식 출시했다. 토큰당 유효 작업량이라는 효율 지표를 전면에 세우고, 코딩과 지식 노동, 사이버보안, 과학에서 다수의 최고 기록과 함께 병렬 멀티에이전트 설정 ultra, 강화된 안전 체계를 공개했다.
OpenAI가 GPT-5.6 패밀리(Sol, Terra, Luna)를 정식 출시했다. 토큰당 유효 작업량이라는 효율 지표를 전면에 세우고, 코딩과 지식 노동, 사이버보안, 과학에서 다수의 최고 기록과 함께 병렬 멀티에이전트 설정 ultra, 강화된 안전 체계를 공개했다.
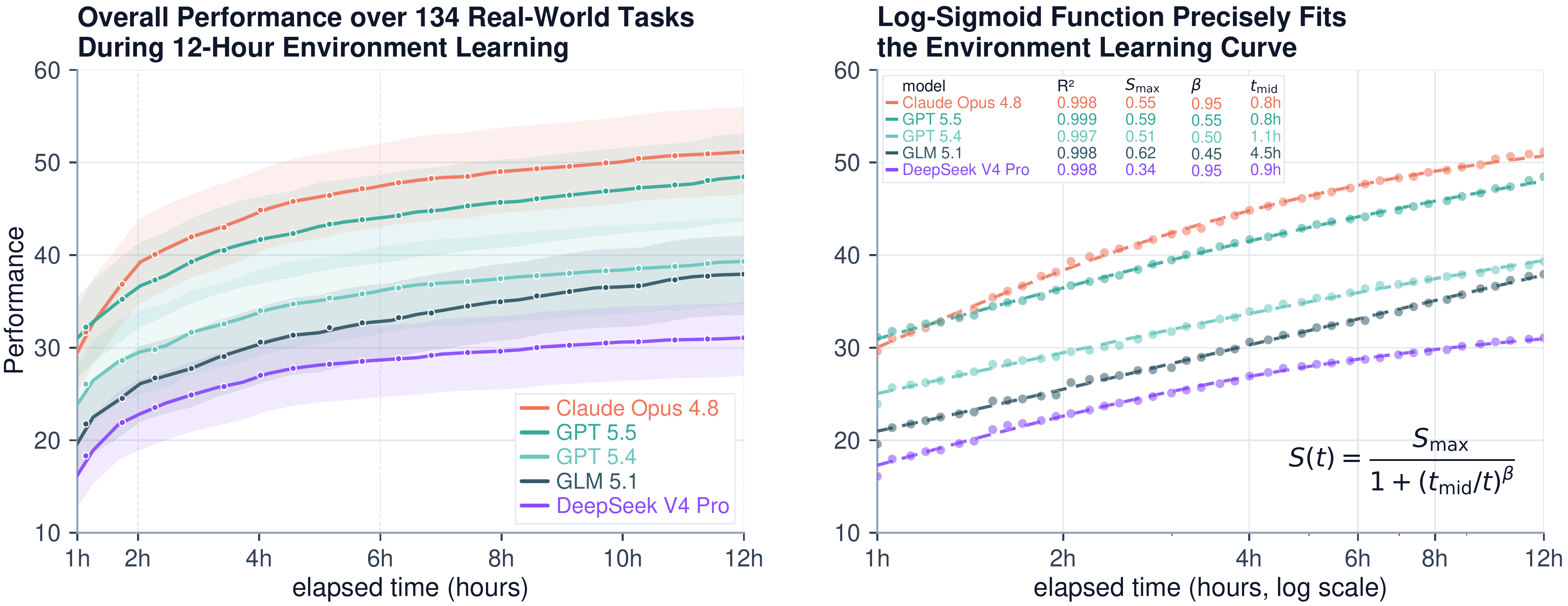
ByteDance Seed가 공개한 EdgeBench는 6개 능력군에 걸친 134개 실세계 태스크로 프론티어 에이전트의 12시간 이상 환경 학습을 측정한 벤치마크다. 약 38,000시간의 상호작용을 분석한 결과, 환경 학습 성능은 로그-시그모이드 스케일링 법칙(R²=0.998)을 따르고 학습 속도는 대략 3개월마다 두 배가 된다.
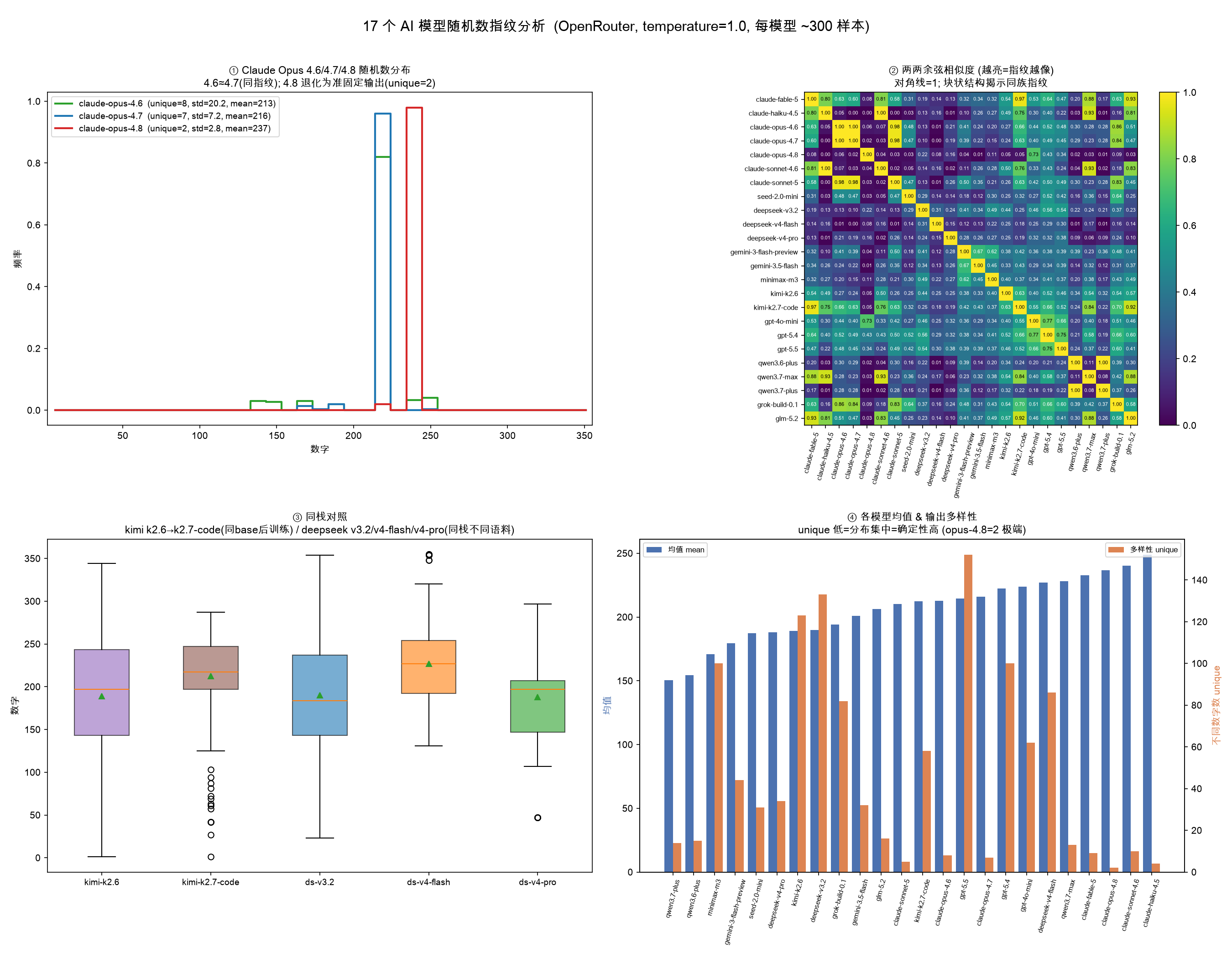
1부터 355 사이의 랜덤한 수를 뽑으라는 프롬프트를 대량 반복시켜 얻은 통계 분포로 24개 AI 모델의 지문을 만들고, 그 지문으로 제3자 API 중계의 모델 위조까지 잡아낸 실측 데이터셋.
OpenAI가 차세대 모델 패밀리 GPT-5.6(Sol·Terra·Luna)을 공개했다. 미 정부와 사전 조율한 제한적 프리뷰로 출시하며, Preparedness Framework상 생물·화학·사이버 모두 High 등급에 닿았지만 Critical 임계는 넘지 않았다고 명시한다.
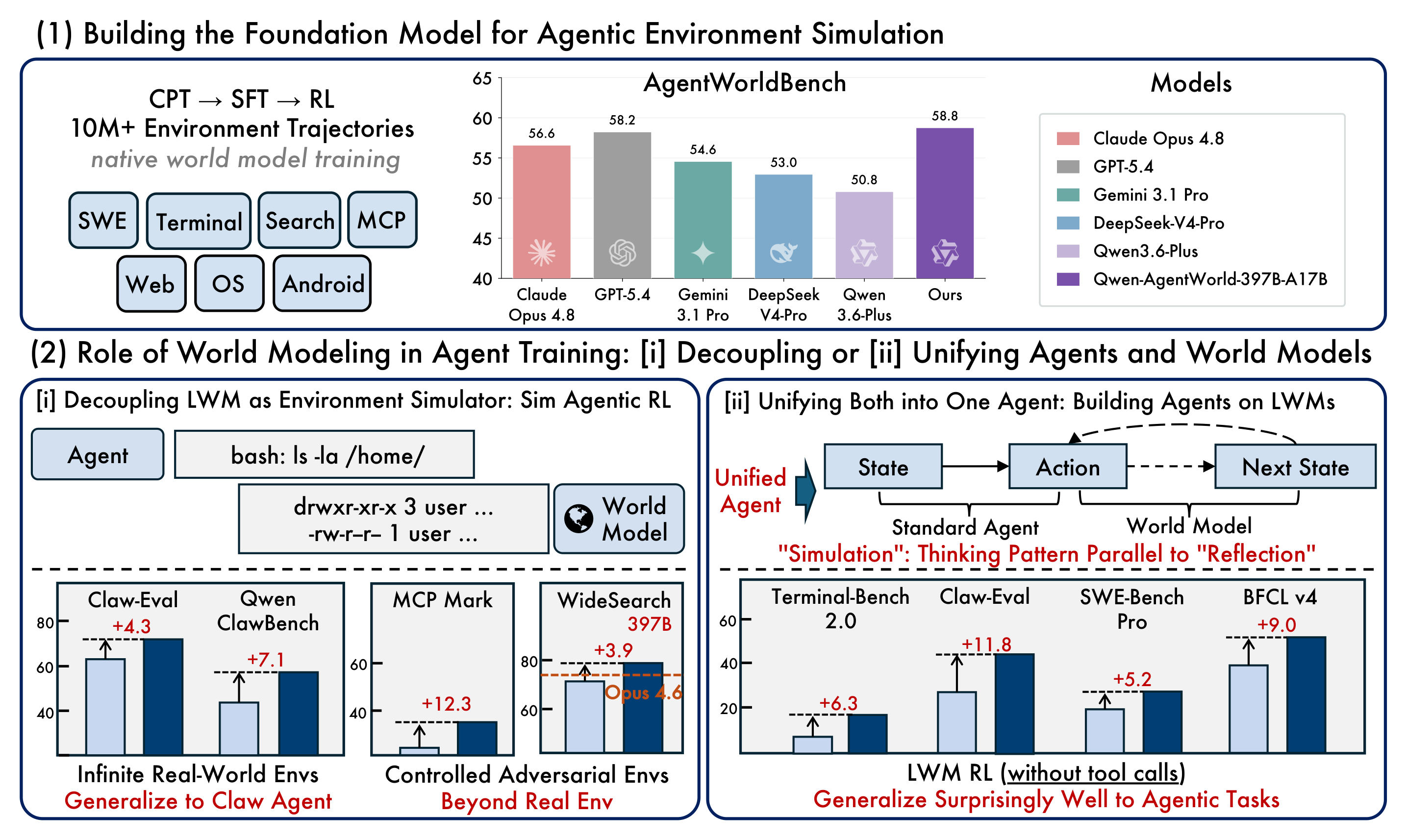
Qwen 팀이 일곱 가지 에이전트 환경(MCP·Search·Terminal·SWE·Web·OS·Android)을 하나의 모델로 시뮬레이션하는 언어 월드 모델 Qwen-AgentWorld를 공개했다. CPT→SFT→RL 3단계로 훈련했고, 397B-A17B 모델이 GPT-5.4·Claude Opus 4.8·Gemini 3.1 Pro를 넘는 AgentWorldBench 성능과 함께 시뮬레이션 RL이 실제 환경 학습을 능가하는 결과를 보였다.

측정할 수 있는 일은 곧 학습 대상이 되어 commodity로 빨려 들어간다. Sarah Guo는 가치가 ‘학습 불가능한(untrainable)’ 영역 — frontier 난이도이면서 정답이 사적인 마지막 사분면 — 으로 이동한다고 본다.
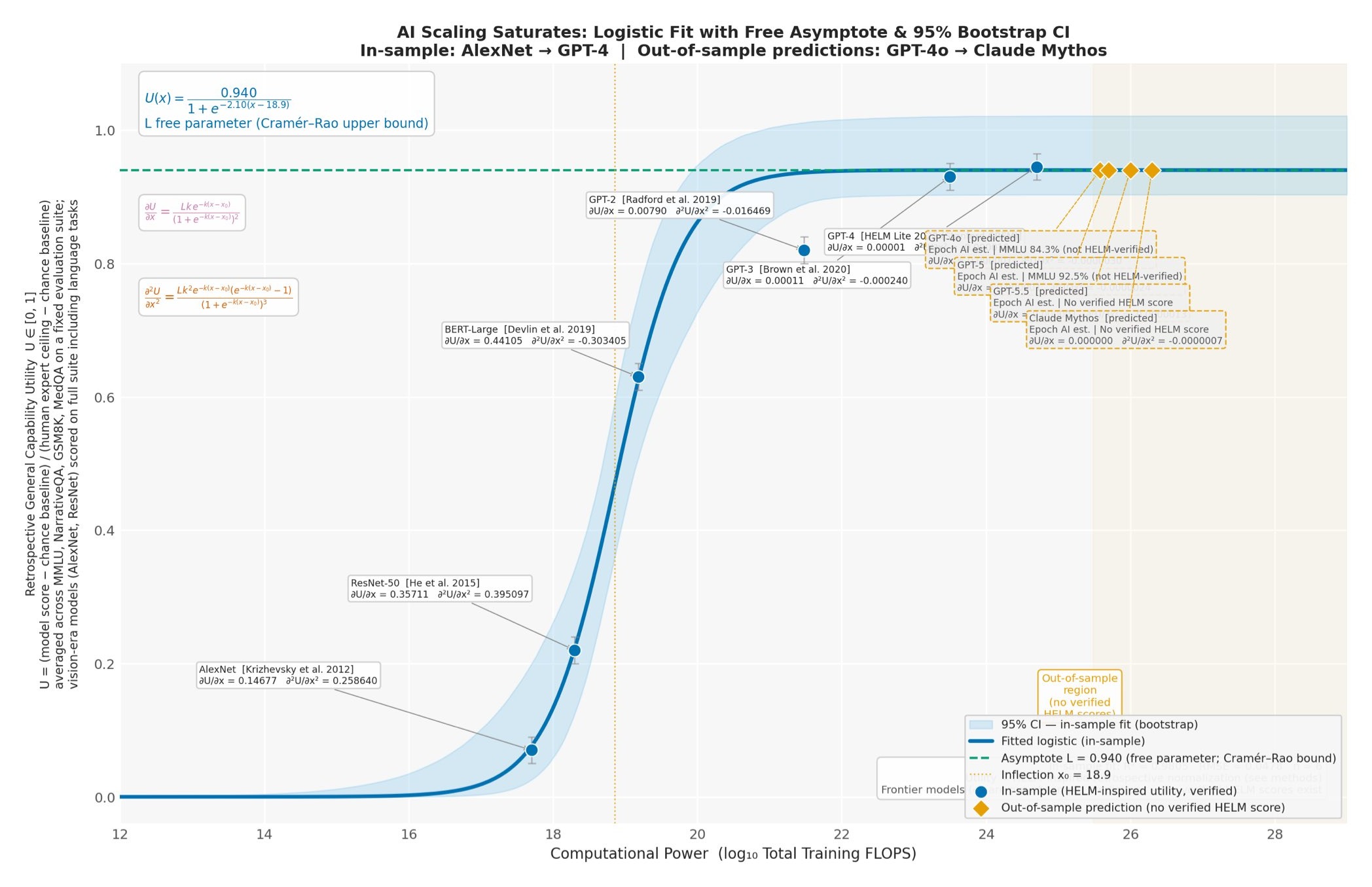
통계에 밝은 종양내과 의사 @5_utr가 AlexNet부터 GPT-4까지의 데이터에 로지스틱 곡선을 적합해 ‘AI 스케일링은 지수가 아니라 포화한다’고 주장했다. 타래의 진짜 칼끝은 거시경제다 — AI 밸류에이션이 지수함수로 가격책정됐는데 데이터는 로지스틱이 훨씬 잘 맞으니 함수형 오설정이자 버블이라는 것. 주장과 그 한계를 함께 정리한다.

코어위브가 MLPerf Training v6.0에서 8,192개의 NVIDIA Blackwell Ultra GPU로 DeepSeek-V3 671B를 2.02분에 학습 완료하며 역대 최고 기록을 세웠다. 코어위브는 풀스택 소프트웨어 최적화 덕에 GPU를 더 늘리지 않고도 v5.0 대비 2.8배 빠른 결과를 냈다고 주장한다.

Anthropic이 같은 가중치를 두 얼굴로 출시한 최신 모델의 시스템 카드. 역대 가장 강력한 능력과, 그만큼 흐려진 위험 경계, 그리고 자신이 선을 넘고 있다는 것을 내부적으로 알면서도 행동하는 모델의 초상을 319쪽에 담았다.
Cognition이 공개한 신규 코딩 벤치마크. 정답 여부가 아니라 ‘메인테이너가 실제로 머지하겠는가’를 측정한다. Diamond 50문항에서 최강 모델 Claude Opus 4.8도 13.4%에 그쳤다.