
용도별 모델표
| 작업 | 추천 모델 |
|---|---|
| 텍스트 헤비 마케팅 포스터 | GPT-Image-2 |
| 미적 컨셉 아트·에디토리얼 | Midjourney V8.1 |
| 포토리얼 인물·제품 사진 | Flux 2 Pro · Imagen 4 · Reve Image |
| 캐릭터·인물 일관성 시리즈 | Flux Kontext · GPT-Image-2 |
| 멀티 레퍼런스 합성 (가상 피팅 등) | Kling Image O1 |
| 텍스트 디자인 포스터 | Ideogram 3.0 |
| 벡터 로고·아이콘 | Recraft V3 |
| 애니메이션 일러스트 | Anima |
| 영상의 첫 프레임 (이미지→영상) | Kling 3.0 · Runway Gen-4.5 · Veo 3.1 · Seedance 2.0 |
| 자기 스타일 자산화 (LoRA) | Flux 2 Dev · Stable Diffusion · Z-Image Turbo |
용도별로 모델이 갈리는 이유는 네 가지다. 텍스트 정확도, 멀티턴 정체성, 출력 포맷(픽셀/벡터), 자동화 지원(API). 아래에 작업별로 짧게 풀어 둔다.
텍스트가 들어가야 할 때
GPT-Image-2의 텍스트 정확도가 99%에 도달했다.1 영문 헤드라인, 한글 본문, 가격표, 두 언어 병기까지 한 호출에 올바르게 나온다. 작년까지는 분위기 컷을 다른 모델로 뽑고 위에 Photoshop으로 텍스트를 얹어야 했다. 텍스트가 이미지 안에 들어가는 순간 디자이너의 일은 레이어 합성에서 프롬프트 큐레이션으로 옮겨간다.
 단일 프롬프트로 만든 6격자 인포그래픽. 비주얼·헤드라인·태그가 한 번에 정렬되었다. (OpenAI)
단일 프롬프트로 만든 6격자 인포그래픽. 비주얼·헤드라인·태그가 한 번에 정렬되었다. (OpenAI)
라틴·CJK·힌디·벵골을 한 이미지에 함께 넣어도 글자가 무너지지 않는다.
 다섯 문자 체계가 정확히 렌더링됐다. (OpenAI)
다섯 문자 체계가 정확히 렌더링됐다. (OpenAI)
웹 검색을 그라운딩한 인포그래픽도 한 호출로 나온다. 기상 데이터·체크리스트·아이콘이 올바르게 배치된다.
 실시간 날씨 데이터를 가져온 뒤 합성. (Wired)
실시간 날씨 데이터를 가져온 뒤 합성. (Wired)
미적 분위기
Midjourney V8.1의 구도와 조명은 다른 모델이 따라잡지 못한다. 무드 잡기, 컨셉 탐색, 에디토리얼 일러스트는 여전히 Midjourney가 강하다.
 Midjourney V8.1의 미적 본령. 보랏빛 노을과 달이 떠 있는 사막에 홀로 선 우주복 인물. 장르 영화 한 컷의 구도·조명·분위기.
Midjourney V8.1의 미적 본령. 보랏빛 노을과 달이 떠 있는 사막에 홀로 선 우주복 인물. 장르 영화 한 컷의 구도·조명·분위기.
 피부·머리카락·고양이 털·가죽 질감이 카메라 사진 수준. (Geeky Curiosity)
피부·머리카락·고양이 털·가죽 질감이 카메라 사진 수준. (Geeky Curiosity)
한 가지 아쉬운 점이라면 Midjourney는 API가 없다. 자동화 호출이 안 되니 자동으로 뽑아야 한다면 다른 모델과 함께 써야 한다. 분위기는 Midjourney에서 잡고 마무리·텍스트는 GPT-Image-2로 넘기는 두 단계 워크플로가 정착했다.
포토리얼 사진
Flux 2 Pro와 Google Imagen 4가 공동 1위다. TokenMix 포토리얼리즘 벤치마크에서 93/92 (Midjourney V7 88).2 피부 모공, 머리카락의 빛 반사, 옷감 질감이 카메라 사진과 구분되지 않는다.
 피부 윤기·머리카락 가닥·역광 보케. (picassoia)
피부 윤기·머리카락 가닥·역광 보케. (picassoia)
 깃털 광택, 부리 광 반사. (Google DeepMind)
깃털 광택, 부리 광 반사. (Google DeepMind)
두 모델은 보완적이다. Imagen 4는 빠르다. 한 장에 1~3초, 동시 호출에서 큐가 짧아 후보를 수백 장씩 펼치는 작업에 어울린다. Flux 2 Pro는 제어가 좋다. 색상 코드(HEX)와 포즈 가이드로 고른 한 장의 정밀도를 잡을 수 있다. 4축으로 보면 둘 다 자동화 지원이 좋다는 점이 공통. 차이는 큐레이션 단계에서 나뉜다.
신생 Reve Image도 포토리얼 평가에서 상위에 들어와 있다. 작은 회사도 1위를 노릴 수 있는 영역이다.
 시네마틱 광선·먼지 효과의 포토리얼. (Oakgen)
시네마틱 광선·먼지 효과의 포토리얼. (Oakgen)
캐릭터 일관성
이 영역의 1위는 Flux Kontext다. KontextBench 캐릭터 레퍼런스(CREF) 전 카테고리 1위.3 정체성 이탈(Identity Drift)이라는 측정치가 있다. 같은 캐릭터의 20번째 컷에서 얼굴 임베딩 거리가 처음과 얼마나 벌어졌는가의 비율이다. 작년 봄 38%에서 1년 만에 6%로 떨어졌다.
같은 입력 셀카가 멀티턴 편집을 거쳐 어떻게 바뀌는지 KontextBench 논문 Figure 2의 예시로 보면 분명하다. 입력은 얼굴에 설편이 붙은 셀카, 3턴째 결과는 같은 인물이 눈 내리는 Freiburg 거리에 서 있는 컷. 의상·헤어·표정이 그대로 살아남았다.
 입력. 보라색 터틀넥, 얼굴에 설편 장식이 붙은 셀카. (KontextBench arXiv:2506.15742 Fig. 2)
입력. 보라색 터틀넥, 얼굴에 설편 장식이 붙은 셀카. (KontextBench arXiv:2506.15742 Fig. 2)
 3턴째 결과. 환경이 눈 내리는 Freiburg 거리로 바뀌었지만 인물·의상·헤어는 입력 그대로 유지. (같은 출처)
3턴째 결과. 환경이 눈 내리는 Freiburg 거리로 바뀌었지만 인물·의상·헤어는 입력 그대로 유지. (같은 출처)
같은 영역에 GPT-Image-2의 8장 일관성이 있지만, 두 모델은 다른 문제를 푼다. GPT-Image-2의 8장은 한 호출의 폭이다. 캐릭터·사물·스타일이 일치하는 여덟 장이 동시에 나온다. Flux Kontext는 시간의 깊이다. 한 캐릭터를 받아 20턴 동안 의상·배경·표정을 바꿔도 얼굴이 무너지지 않는다.4
스토리보드·만화 페이지처럼 한 장면의 변주가 필요하면 GPT-Image-2. 그래픽 노블·브랜드 마스코트 시리즈·광고 모델 컷처럼 긴 호흡의 편집이 필요하면 Flux Kontext.
 한 호출로 만든 일본 망가 페이지. 패널 사이 캐릭터·구도 일관성. (OpenAI)
한 호출로 만든 일본 망가 페이지. 패널 사이 캐릭터·구도 일관성. (OpenAI)
가상 피팅이나 여러 레퍼런스를 합성하는 작업에는 Kling Image O1이 따로 있다. 최대 10장의 레퍼런스 이미지를 동시 입력해 한 장의 합성 결과를 낸다. 입력으로 던지는 이미지가 어떻게 모여 한 컷이 되는지 워크플로 자체가 다르다.
 입력. @Image (인물·배경)와 @Element (의상의 앞뒤) 태깅으로 4장이 한 호출에 들어간다. (fal.ai Kling Image O1 예시)
입력. @Image (인물·배경)와 @Element (의상의 앞뒤) 태깅으로 4장이 한 호출에 들어간다. (fal.ai Kling Image O1 예시)
 결과. 멀티 레퍼런스를 합성한 시네마틱 컷. (Krea)
결과. 멀티 레퍼런스를 합성한 시네마틱 컷. (Krea)
벡터 로고
Recraft V3가 업계 유일로 SVG 파일을 직접 만든다. 패스가 살아 있고, 색을 따로 바꿀 수 있고, 사이즈를 키워도 깨지지 않는다. 일러스트레이터·피그마에 그대로 끌어다 쓴다. 로고·아이콘·UI 자산에 결정적이다.
 업계 유일의 SVG 네이티브 출력. (Replicate)
업계 유일의 SVG 네이티브 출력. (Replicate)
텍스트 디자인 포스터
이미지 안에 헤드라인·서브타이틀·날짜·위치가 모두 정렬되어야 하는 디자인 포스터는 Ideogram 3.0도 강하다. 타이포그래피 정확도 90~95%로 GPT-Image-2의 보완재로 정착했다.5 선택 기준은 단순하다. 헤드라인이 그래픽의 주인공이면 Ideogram. 텍스트가 그래픽에 얹히는 보조면 GPT-Image-2.
 헤드라인·서브타이틀·날짜·로케이션의 정밀 렌더링. (Segmind)
헤드라인·서브타이틀·날짜·로케이션의 정밀 렌더링. (Segmind)
애니메이션 일러스트
애니메이션 스타일의 작업에는 Anima가 있다. 2B 파라미터, 6GB 그래픽 카드에서 실행. 합성 데이터를 쓰지 않고 실제 애니메이션·예술 이미지로만 학습한 모델이다.
 수채화 초상·펜 스케치·셀 쉐이딩 액션·RPG 야영 씬. (kombitz)
수채화 초상·펜 스케치·셀 쉐이딩 액션·RPG 야영 씬. (kombitz)
영상의 첫 프레임 (이미지→영상)
영상으로 가는 작업이 잦다면 알아두는 게 좋은 한 가지가 있다. 전문 스튜디오는 영상 모델을 건드리기 전에 수백 장의 컨셉 이미지를 먼저 만든다.6 영상의 첫 프레임을 결정하는 것은 이미지 디자이너의 일이다. 시작점의 비주얼 방향을 결정하는 권한은 이미지 단계에 남는다.
영상 모델은 네 가지가 정착했다 (AIUnpacking 가이드 분류 기준).7 Kling 3.0(얼굴 일관성 1위, 4K 60fps), Runway Gen-4.5(카메라 컨트롤 1위), Google Veo 3.1(네이티브 오디오), Seedance 2.0(ArtificialAnalysis Text-to-Video ELO 1위).
 Kling 3.0의 영상 데모 키프레임. (picassoia)
Kling 3.0의 영상 데모 키프레임. (picassoia)
 카메라 컨트롤·Aleph 인컨텍스트 편집. (Runway)
카메라 컨트롤·Aleph 인컨텍스트 편집. (Runway)
 Ingredients to Video로 참조 이미지 3장을 합성. (Google DeepMind Veo)
Ingredients to Video로 참조 이미지 3장을 합성. (Google DeepMind Veo)
 예술적 무드와 물리적 일관성의 결합. (fal.ai)
예술적 무드와 물리적 일관성의 결합. (fal.ai)
자기 스타일을 모델에 가르치기
여기까지는 어떤 모델을 빌릴 것인가의 이야기였다. 내 손에 맞는 모델을 원한다면 파인 튜닝을 고려해 볼 때다.
파인튜닝은 기존 모델을 내 데이터로 다시 가르치는 과정이다. 가장 흔한 형태가 LoRA(Low-Rank Adaptation). 모델 전체를 다시 학습시키지 않고 작은 추가 부품만 학습시켜 특정 스타일·캐릭터·구도를 모델에 더한다. 일러스트레이터가 자기 그림 50장으로 LoRA를 만들면 그 모델은 그 일러스트레이터의 선·색·붓 자국을 따라 그린다.
 같은 프롬프트 “거대한 사막 풍경에 신비한 구조물”. 왼쪽은 Flux 베이스 모델, 오른쪽은 Denis Villeneuve 스타일 LoRA 적용. 황금빛 노을·드라마틱한 첨탑·구름이 Dune 스타일로 자연스럽게 따라온다. (director-diffusion, GitHub)
같은 프롬프트 “거대한 사막 풍경에 신비한 구조물”. 왼쪽은 Flux 베이스 모델, 오른쪽은 Denis Villeneuve 스타일 LoRA 적용. 황금빛 노을·드라마틱한 첨탑·구름이 Dune 스타일로 자연스럽게 따라온다. (director-diffusion, GitHub)
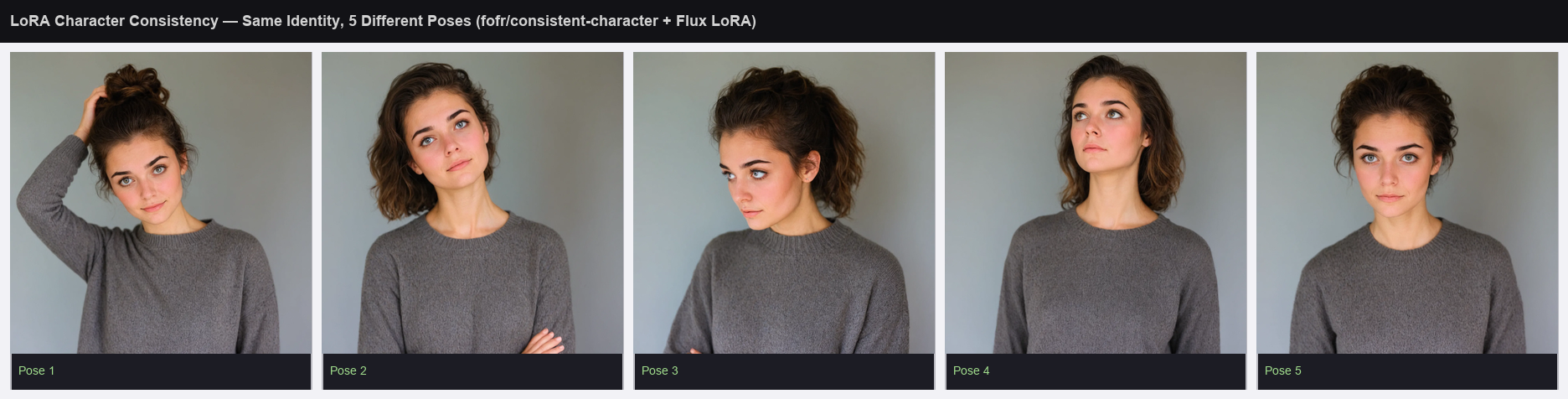 같은 인물이 5가지 포즈로 일관되게 생성된다. 시드가 바뀌어도 얼굴·의상·피부톤이 살아남는 것이 LoRA의 핵심 가치다. (fofr/consistent-character + Flux LoRA, Replicate)
같은 인물이 5가지 포즈로 일관되게 생성된다. 시드가 바뀌어도 얼굴·의상·피부톤이 살아남는 것이 LoRA의 핵심 가치다. (fofr/consistent-character + Flux LoRA, Replicate)
작업 순서는 단순하다. (1) 자기 작품 50~150장을 고른다. 같은 스타일의 그림이어야 한다. (2) 무료 도구 (예: civitai의 학습 페이지, fal.ai의 LoRA 트레이너, 또는 데스크탑의 Kohya GUI) 위에서 한 번 학습시킨다. 그래픽 카드 8~16GB면 충분하다. (3) 학습된 LoRA 파일(보통 10~200MB)을 베이스 모델에 얹어 호출한다. 결과는 베이스 모델 + 내 스타일이 합쳐진 새 출력이다.
LoRA가 잘 작동하는 베이스 모델은 셋이다. Flux 2 Dev(가장 신선한 출력, 32B 파라미터, 오픈웨이트), Stable Diffusion XL/3.5(가장 큰 LoRA 생태계, 수천 개의 기존 LoRA), Z-Image Turbo(6B 파라미터, 가장 가벼운 실행). 안타깝지만 GPT-Image-2와 Midjourney는 파인튜닝을 지원하지 않는다.
마무리
도구가 바뀌면 작업표가 바뀐다. 어떤 도구가 어떤 작업에 유리한지 알아야 자기 작업의 시간 배분을 다시 그릴 수 있다. 도구 선택을 정리한 다음 단계는 직접 사용해 보고 자신의 손에 맞춰 가는 일이다. 뭐든 직접 해본 경험이 자산이 되는 시대니까.
TokenMix, “GPT Image 2 Review”, 2026-04. DALL-E 3 시절 약 70%에서 99%로 도약. ↩︎
TokenMix, “Imagen 4 Ultra Review”. 포토리얼리즘 종합 점수 Flux 2 Pro 93 / Imagen 4 Ultra 92 / Midjourney V7 88. ↩︎
Black Forest Labs, FLUX.1 Kontext (자사 측정); KontextBench arXiv:2506.15742. ↩︎
OpenAI, “Introducing ChatGPT Images 2.0”, 2026-04-21. ↩︎
AIUnpacking, “Ideogram 3.0 Review: Still the Text-in-Image King in 2026”. 텍스트 정확도 90~95%는 같은 리뷰의 측정. ↩︎
Studiolist, “AI Video Model Comparison 2026”, 2026-04-06. ↩︎
AIUnpacking, “AI Video Generation in 2026: Sora, Runway, Kling, Veo”. 카테고리별 1위는 같은 가이드의 정리. ↩︎