3줄 요약
- Northeastern·Stanford·CMU·West Virginia 공동 연구진이 2025년 10월 arxiv에 공개한 논문(2510.01171). RLHF로 정렬한 LLM이 다양한 답을 못 만들고 한 점으로 수렴하는 mode collapse 현상의 원인을 파고든다.
- 진짜 원인은 알고리즘이 아니라 preference data에 새겨진 typicality bias — 인간 annotator가 친숙·유창·예측 가능한 텍스트를 체계적으로 helpful하다고 판정하는 인지심리학적 정설 — 이며, KL-regularized RLHF가 이 편향을 sharpening하여 mode collapse를 일으킨다는 것을 수식과 데이터로 증명한다.
- 해결책으로 “5개 답을 확률 분포와 함께 생성하라"는 prompting trick인 Verbalized Sampling(VS)을 제안한다. training-free·model-agnostic하면서 creative writing 다양성을 1.6~2.1배 회복하고, 더 큰 모델일수록 효과가 크다.12

배경 — 정렬은 다양성을 죽인다
Aligned LLM은 base 모델 대비 응답 다양성이 줄어든다. 이는 RLHF·SFT 이후 일관되게 관측되는 부작용이며, creative writing(Lu et al. 2025), social simulation(Anthis et al. 2025), pluralistic alignment(Kirk et al. 2024) 같은 응용을 직접 제약한다. 같은 질문을 여러 번 던져도 거의 같은 답이 돌아오는 그 현상이다.
기존 설명은 알고리즘 한계에 무게를 두었다.
- 단일 reward model이 다원적 인간 선호를 다 담지 못한다(Chakraborty et al.)
- KL-regularized 최적화가 majority-style 응답을 증폭시킨다(Xiao et al.)
- SFT의 cross-entropy loss나 chat template의 경직성이 다양성을 더 깎는다(Yun et al.)
이 논문은 한 단계 더 들어간다. 알고리즘이 완벽하더라도 collapse가 일어나는 데이터 차원의 원인이 있다고 주장한다.
진짜 원인 — preference data에 새겨진 typicality bias
저자들은 인지심리학에서 잘 정립된 네 가지 발견을 가져온다.
- Mere-exposure effect(Zajonc 1968): 자주 본 것을 더 좋아한다.
- Availability heuristic(Tversky&Kahneman 1973): 쉽게 떠오르는 것을 더 그럴듯하다고 느낀다.
- Processing fluency(Alter&Oppenheimer 2009): 처리하기 쉬운 텍스트를 더 진실되고 고품질이라고 지각한다.
- Schema congruity(Mandler 2014): 기존 mental model에 맞는 정보를 비판 없이 수용한다.
이 네 메커니즘은 한 방향을 가리킨다. 사람은 친숙하고 유창한 텍스트를 더 좋다고 평가한다. 그래서 RLHF preference data를 라벨링하는 annotator도, 동등한 정확성에서 더 typical한 응답을 helpful하다고 골라준다 — 이것이 typicality bias다.
저자들은 reward 함수를 다음과 같이 분해한다.
r(x, y) = r_true(x, y) + α · log π_ref(y | x) + ε(x)
여기서 π_ref는 사전훈련 base 모델의 likelihood로, typicality의 tractable proxy다(base 모델은 거대 코퍼스에서 빈도를 학습했으므로). α는 typicality bias의 강도를 나타내는 가중치다.
HelpSteer 데이터셋에서 correctness 평점이 동률인 응답쌍 6,874개를 골라 helpfulness 차이를 회귀하면, α 추정치가 다음과 같다.
| Base 모델 (π_ref) | α 추정치 | p-value |
|---|---|---|
| Llama 3.1 405B Base | 0.57 ± 0.07 | < 10⁻¹⁴ |
| GLM 4.5 Base | 0.65 ± 0.07 | < 10⁻¹⁴ |
p < 10⁻¹⁴는 통계적으로 압도적으로 유의미하다. 우연이 아니라 데이터에 새겨진 사실이라는 뜻이다.
KL-RLHF가 typicality를 sharpening한다
α > 0가 데이터에 들어가 있으면, KL-regularized RLHF의 closed-form 최적해가 다음과 같이 변한다(Rafailov et al. 2024).
π*(y | x) ∝ π_ref(y | x)^γ · exp(r_true(x, y) / β), 단 γ = 1 + α/β > 1
γ > 1은 temperature scaling과 같은 효과다. base 분포 π_ref에 거듭제곱이 걸리면 mass가 mode 쪽으로 압축된다. 진짜 utility가 동률인 응답군 𝒮에서는 π*(y) ∝ π_ref(y)^γ만 남으므로, γ가 크면 가장 typical한 한 응답으로 mode collapse된다.
핵심 함의: α가 데이터 차원에 있으므로, 어떤 reward model을 쓰든·어떤 optimizer(PPO·DPO·GRPO)를 쓰든 collapse는 그대로 일어난다. 알고리즘 개선만으로는 근본적으로 풀리지 않는 문제다. 풀려면 데이터 차원의 개입(annotator 가이드라인 변경, typicality 재가중) 또는 inference 시점의 우회가 필요하다.
해결책 — 분포 자체를 verbalize하라
저자들은 훈련을 우회하는 길을 택한다. 이미 base 모델이 다양한 분포를 학습해두었고 aligned 모델 안에도 그 분포가 살아있다는 선행 연구(West&Potts 2025; Zhu et al. 2025)에 기대어, prompt가 어떤 mode를 호출하느냐를 바꾼다.
prompting 전략은 세 층위로 나뉜다.
| 층위 | 방식 | 호출되는 mode | 예시 |
|---|---|---|---|
| Instance-level | Direct, CoT | 단일 인스턴스 (가장 typical한 한 응답) | “커피 농담 하나 해줘” |
| List-level | Sequence, Multi-Turn | 균일하게 분포된 인스턴스 리스트 | “커피 농담 5개 해줘” |
| Distribution-level (VS) | VS-Standard, VS-CoT, VS-Multi | base가 학습한 분포 그 자체 | “커피 농담 5개를 각각의 확률과 함께 만들어줘” |
같은 aligned 모델이라도 prompt에 따라 어떤 mode로 collapse하느냐가 달라진다. 분포를 요청하면 분포가 mode가 되어, base의 잠재 다양성이 표면화된다는 것이 VS의 직관이다.
VS-Standard 시스템 프롬프트는 다음 형태다.
친절한 어시스턴트 역할이다. 각 질의에 대해 다섯 개의 가능한 응답을
<response>태그 안에 생성한다. 각 응답은<text>와 숫자<probability>를 포함한다. 분포의 꼬리에서 무작위로 샘플링하여, 각 응답의 확률이 0.10 미만이 되도록 한다.
핵심 특성 세 가지다.
- Training-free: 추가 학습 불필요.
- Model-agnostic: GPT-4.1·Claude-Sonnet·Gemini-Pro·Llama·Qwen·DeepSeek R1·OpenAI o3 모두에서 작동.
- Logit 접근 불필요: closed model에도 적용 가능. probability threshold(예: 0.10 이하 tail까지 포함)를 prompt에서 직접 지정해 다양성을 튜닝할 수도 있다.
실험 결과 — 다양성 1.6~2.1배, 품질 유지
Creative writing
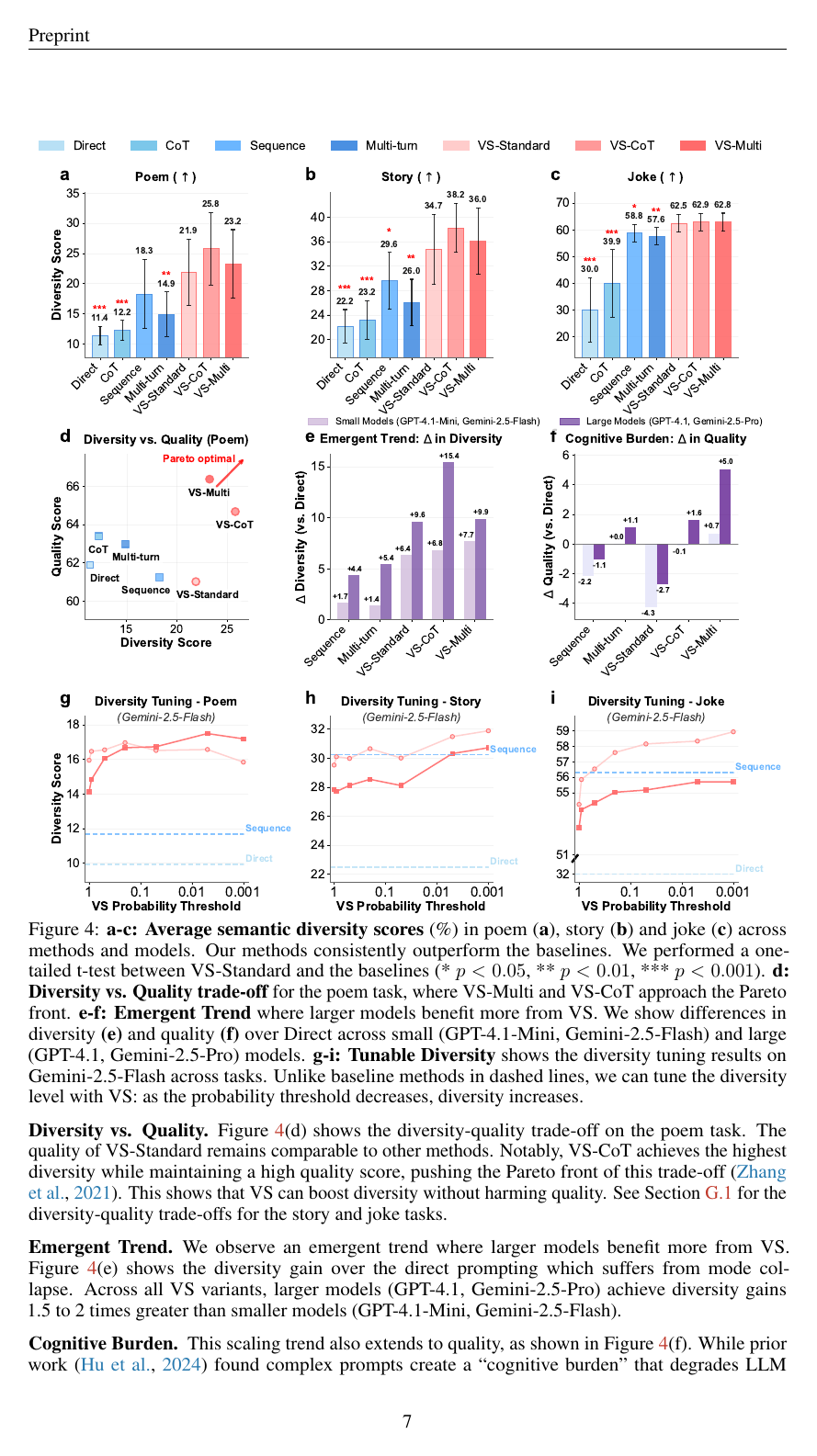
semantic diversity score(% pairwise dissimilarity, 100% = 최대 다양성)에서 baseline 대비 다음과 같이 향상한다.
| 작업 | Direct | VS-Standard | VS-CoT | VS-Multi |
|---|---|---|---|---|
| Poem | 11.4 | 21.9 | 25.8 | 23.2 |
| Story | 22.2 | 29.6 | 38.2 | 36.0 |
| Joke | 30.0 | 57.6 | 62.5 | 62.8 |
VS-CoT와 VS-Multi는 Pareto front를 새로 그어 품질을 떨어뜨리지 않고 다양성을 회복한다. “Without a goodbye"라는 동일 도입부에 direct prompt는 모두 연인의 실종 변주만 출력하는데, VS는 친구의 이메일·우주의 종말·DJ의 죽음 등 서사 축이 다른 응답을 만든다(논문 Table 2).
Open-ended QA
“미국 주를 나열하라” 같은 enumerative QA에서, direct prompt는 캘리포니아·텍사스에 mode collapse한다. RedPajama 사전훈련 코퍼스의 미국 주 빈도 분포를 reference로 두고 KL divergence를 측정하면 다음과 같다.
| Method | KL Divergence (↓) | Coverage-N (↑) | Precision (↑) |
|---|---|---|---|
| Direct | 14.43 | 0.39 | 1.00 |
| CoT | 14.33 | 0.38 | 1.00 |
| Sequence | 5.38 | 0.64 | 0.96 |
| VS-Standard | 3.50 | 0.67 | 0.96 |
| VS-Multi | 3.22 | 0.75 | 0.96 |
KL이 14.43에서 3.22로 약 4배 줄어든다. precision은 거의 1.0을 유지하므로 틀린 답을 늘려서 다양성을 산 게 아니다. aligned 모델이 알고리즘적으로 다른 주를 모르는 것이 아니라 못 꺼내고 있었다는 뜻이다.
Dialogue simulation
PersuasionForGood(기부 설득 대화 1,017건) 시뮬레이션에서, VS는 기부 금액 분포를 인간 ground truth에 가깝게 재현한다. GPT-4.1+VS는 PersuasionForGood로 fine-tune한 Llama-3.1-8B persuadee와 동등한 수준이고, DeepSeek R1+VS는 중앙값에서 그것을 능가한다. Distinct-1/2/3 lexical 다양성은 0.42에서 0.91로 인간 수준에 접근한다. fine-tuning 없이 prompting만으로 도달한 결과라는 점이 실용적 가치다.
Synthetic data
GPT-4.1·Gemini-2.5-flash로 1,000개 math 질문을 합성한 뒤 Qwen3-32B로 답안을 만들어 Qwen2.5-7B/Qwen3-1.7B/Qwen3-4B를 SFT한 결과(MATH500·OlympiadBench·Minerva Math 평균)는 다음과 같다.
| 합성 방법 | 평균 정확도 |
|---|---|
| Baseline (no fine-tune) | 32.8 |
| Direct prompt 합성 | 30.6 |
| Sequence | 34.3 |
| VS-Standard | 36.1 |
| VS-Multi | 37.5 |
direct prompt 합성 데이터는 baseline보다 오히려 떨어진다 — mode collapse가 합성 데이터의 다양성을 죽여 downstream 성능을 깎은 것이다. VS-Multi는 base 대비 4.7p 향상으로, 합성 데이터로 모델을 키우는 파이프라인에 prompting 차원 개선이 곧장 들어갈 수 있음을 보인다.
큰 모델일수록 효과가 크다
GPT-4.1-mini vs GPT-4.1, Gemini-2.5-Flash vs Gemini-2.5-Pro 비교에서, 큰 모델의 다양성 향상폭(Δ Diversity)이 작은 모델 대비 일관되게 1.5~2배 더 크다. 더 흥미로운 것은 품질도 큰 모델에서는 VS-CoT·VS-Multi 같은 복잡한 변형이 오히려 향상된다는 점이다. Hu et al.(2024)이 보고한 “prompt cognitive burden”(복잡한 프롬프트가 품질을 깎는다는 현상)을 큰 모델은 극복한다.
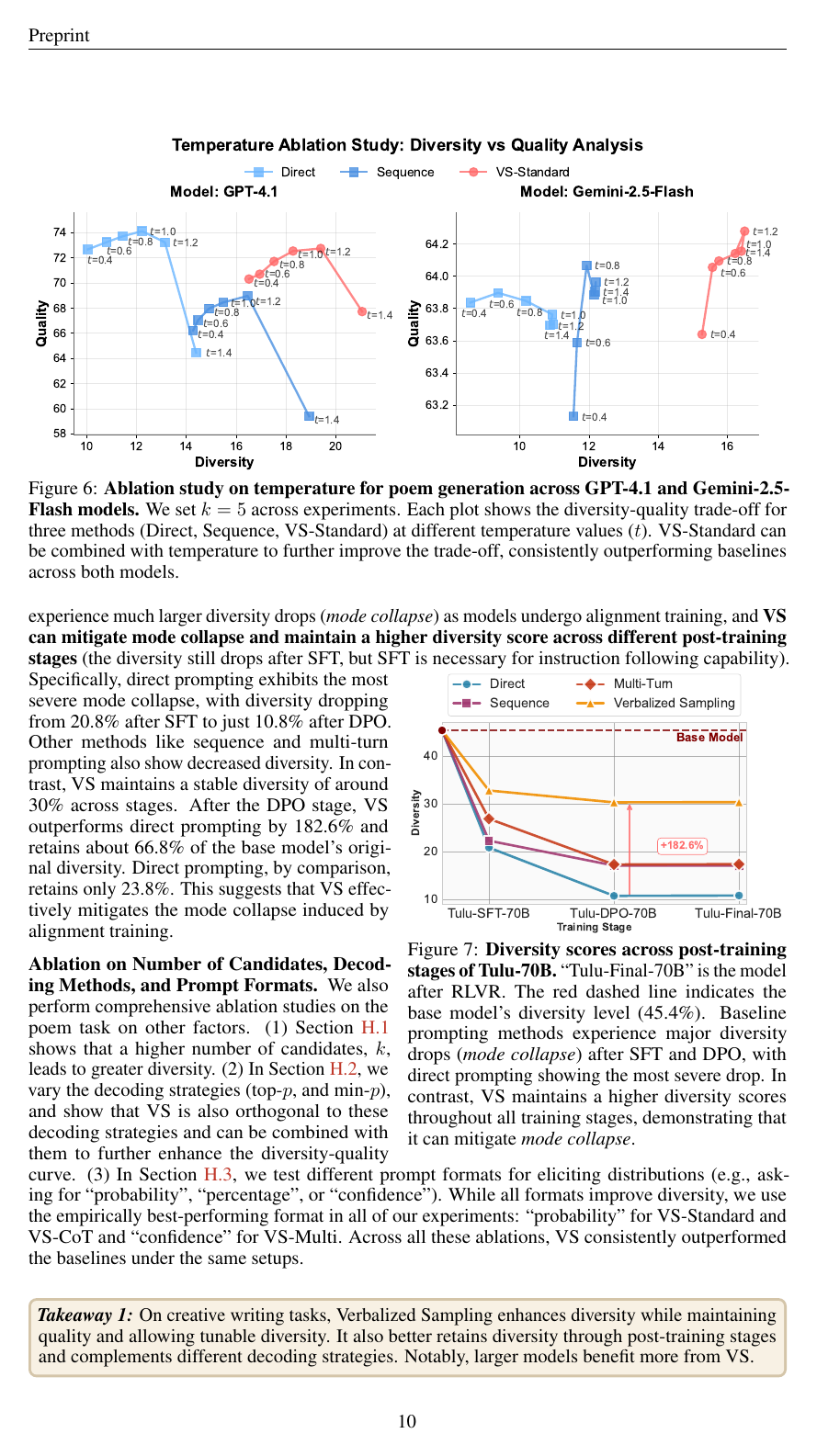
Tulu-3 family로 Tulu-70B-base에서 SFT·DPO·RLVR 단계를 따라가는 ablation에서는, direct prompting이 base 다양성의 23.8%만 회복하는 반면 VS-Standard는 66.8%를 회복한다(direct 대비 +182.6%). alignment 단계가 깊어져도 VS는 약 30%대 다양성을 안정적으로 유지한다.
가장 흥미로운 지점
VS가 회복하는 것이 정확히 무엇인지가 이 논문의 가장 미묘한 지점이다. 저자들은 “base 모델이 사전훈련에서 학습한 분포가 aligned 모델 안에도 살아있다"는 사실에 기대어, prompt가 그 분포에 접근창을 만들 뿐 분포 자체를 바꾸지 않는다고 명확히 한다. 즉 VS는 생성 분포를 verbalize하는 방법이다.
그렇다면 aligned 모델이 “어떤 답이 더 좋은가"를 판정할 때는 어떻게 될까. 5개 농담을 생성할 때는 다양해질 수 있어도, “5개 중 어느 것이 가장 좋은가” 같은 judgment 질의에는 여전히 typicality bias가 새겨진 reward로 학습된 평탄한 선호가 작동한다. 논문은 이 분리를 명시적으로 다루지는 않지만, 생성 다양성의 회복은 판단·취향 평탄화의 자동 회복을 함의하지 않는다는 점은 결과를 해석할 때 중요하다.
또 하나, typicality bias가 인지심리학의 견고한 정설들(processing fluency·schema congruity)에서 나온다는 사실은 데이터 차원의 해결책에도 한계가 있음을 시사한다. annotator 가이드라인을 바꾼다 한들, 유창한 텍스트를 더 좋다고 느끼는 감각 자체가 사람의 인지 구조에 자리잡고 있기 때문이다. VS 같은 inference-time 우회가 항구적인 보완 도구로 자리잡을 가능성이 있다.
출처
- 저자: Jiayi Zhang, Simon Yu, Derek Chong, Anthony Sicilia, Michael R. Tomz, Christopher D. Manning, Weiyan Shi (Northeastern·Stanford·CMU·West Virginia)
- 발행: 2025년 10월 10일 (arxiv preprint v3)
- 원문: https://arxiv.org/abs/2510.01171
- 인용 이미지(Figure 1·4·7)는 모두 원문 PDF에서 추출한 것이다.