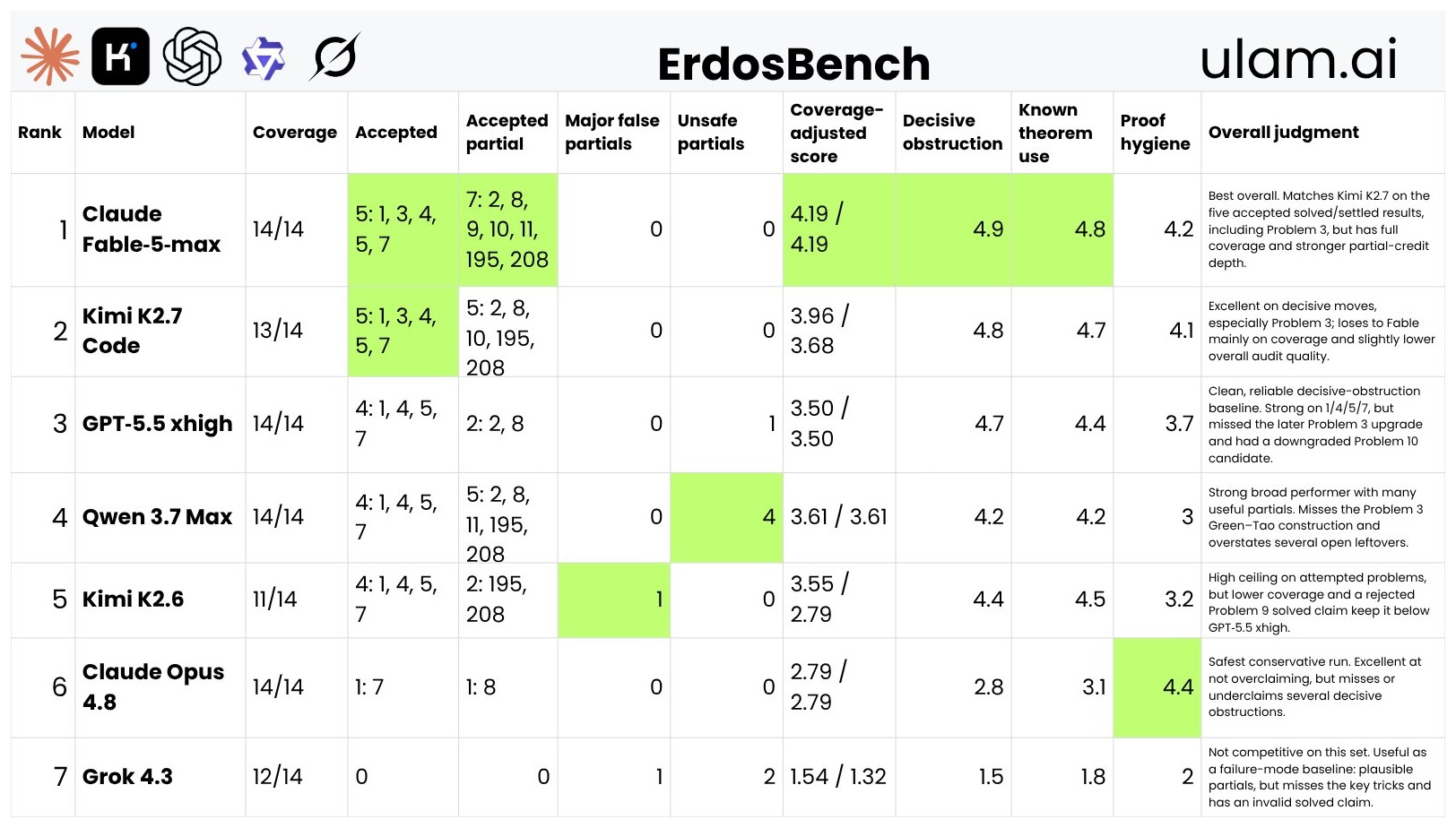
3줄 요약
- Andrew Trask(Oxford/OpenMined)는 2026년 6월 14일 자신의 substack에서 “오늘의 프런티어 AI 회사들이 다시는 AI 능력의 최전선에 닿지 못한다"는 도발적 선언을 했다.
- 더 작은 모델들의 가중 앙상블 네트워크가 단일 프런티어 모델을 정확도·속도·비용 모든 면에서 이미 추월하기 시작했고, 1960년대 메인프레임이 인터넷으로 대체된 사건이 재현되고 있다.
- 따라서 AI 패권은 회사 단위(2010~2026)에서 국가 단위(2026)를 건너뛰고 곧장 세계 단위(world-level AI)로 이동하며, 미국의 Fable 금지가 24시간 만에 OpenRouter의 더 나은 앙상블로 우회된 사례가 그 결정적 증거다.
핵심 선언
저자는 모두가 가정해 온 한 가지 통념을 정면으로 반박한다. AI의 미래가 더 적은 플레이어가 들고 있는 더 큰 모델로 갈 것이라는 가정이다.
Everyone I’ve talked to in AI has always assumed that the future of AI is bigger models held by a smaller number of players. (…) But they couldn’t be more wrong, and now the numbers are showing it. Networks of smaller AI models are outperforming every frontier AI system (Fable/Mythos included) on speed, accuracy, and cost.

저자는 1960년대 IBM, 미국 정부, Bell Telephone, Bell Labs 모두가 메인프레임 컴퓨터에 대해 틀렸던 것처럼, 오늘날 모두가 중앙집중형 AI에 대해 틀리고 있다고 본다. 미래는 오픈소스 AI도 클로즈드소스 AI도 아니다. 네트워크 소스 AI(network-source AI)다.
Part 1: 경제의 게임은 끝났다
AI 경쟁이 능력·속도를 극대화하고 비용을 최소화하는 경쟁이라면, 그리고 사용자가 최고의 능력을 찾거나 가장 좋은 가성비를 찾는다면, 중앙집중형 AI의 경주는 이미 끝났다고 저자는 말한다.
능력(Capability)
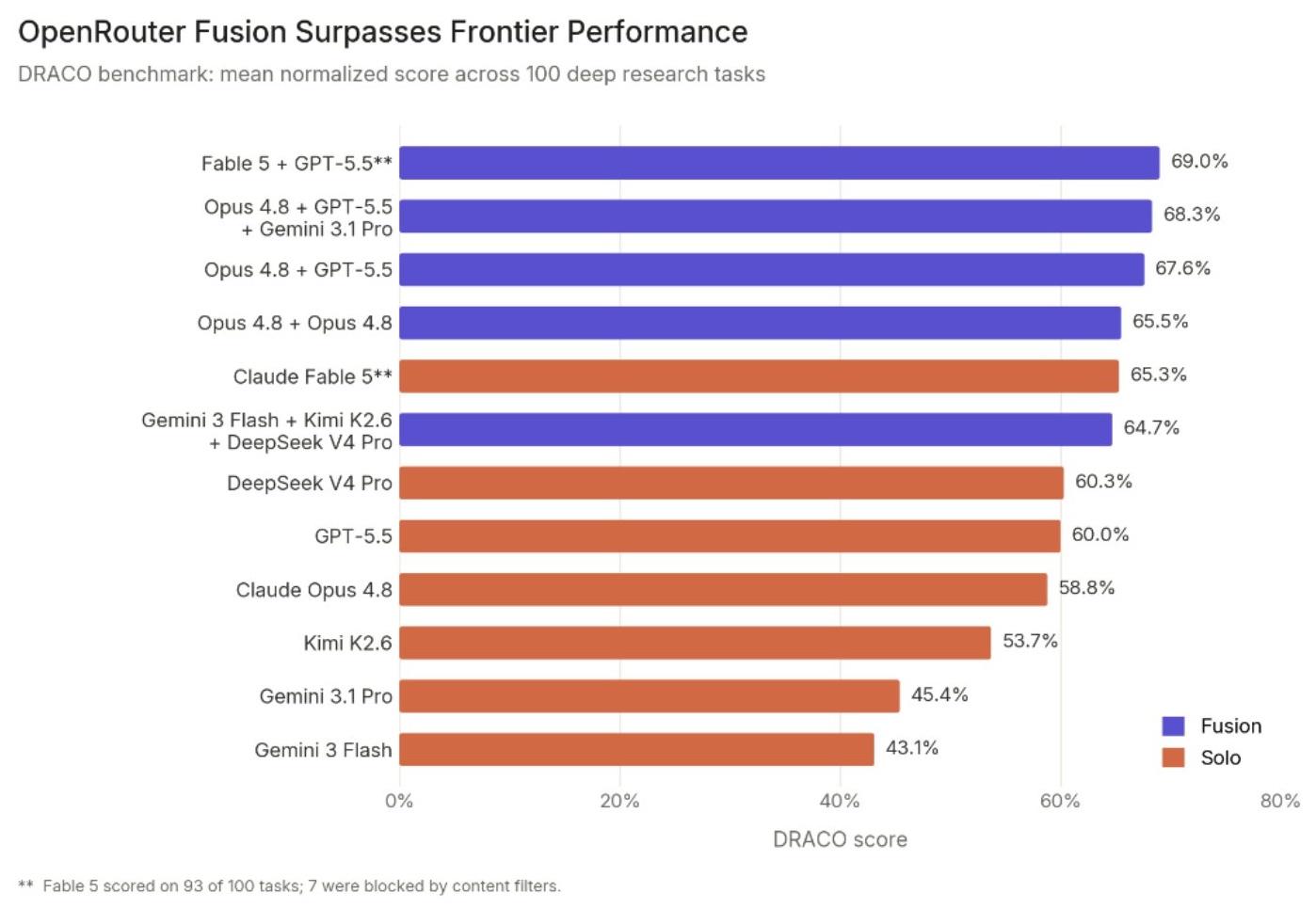
저자가 직접 6개월 전 실험한 결과는 다음과 같았다. humanity’s last exam의 멀티초이스 섹션에서 프런티어 모델들의 점수는 다음 수준이다.
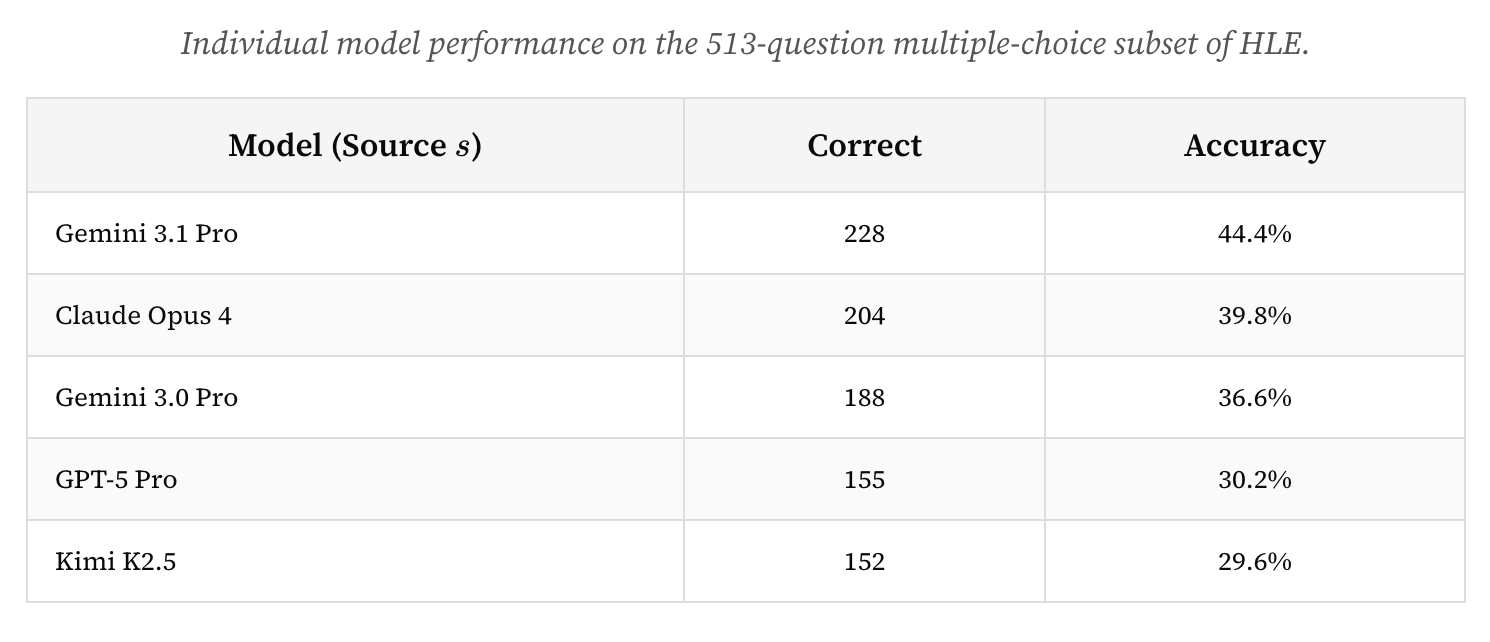
그러나 이들의 차분 프라이버시(differentially private) 결합은 점수를 50점대 초반까지 끌어올렸다.
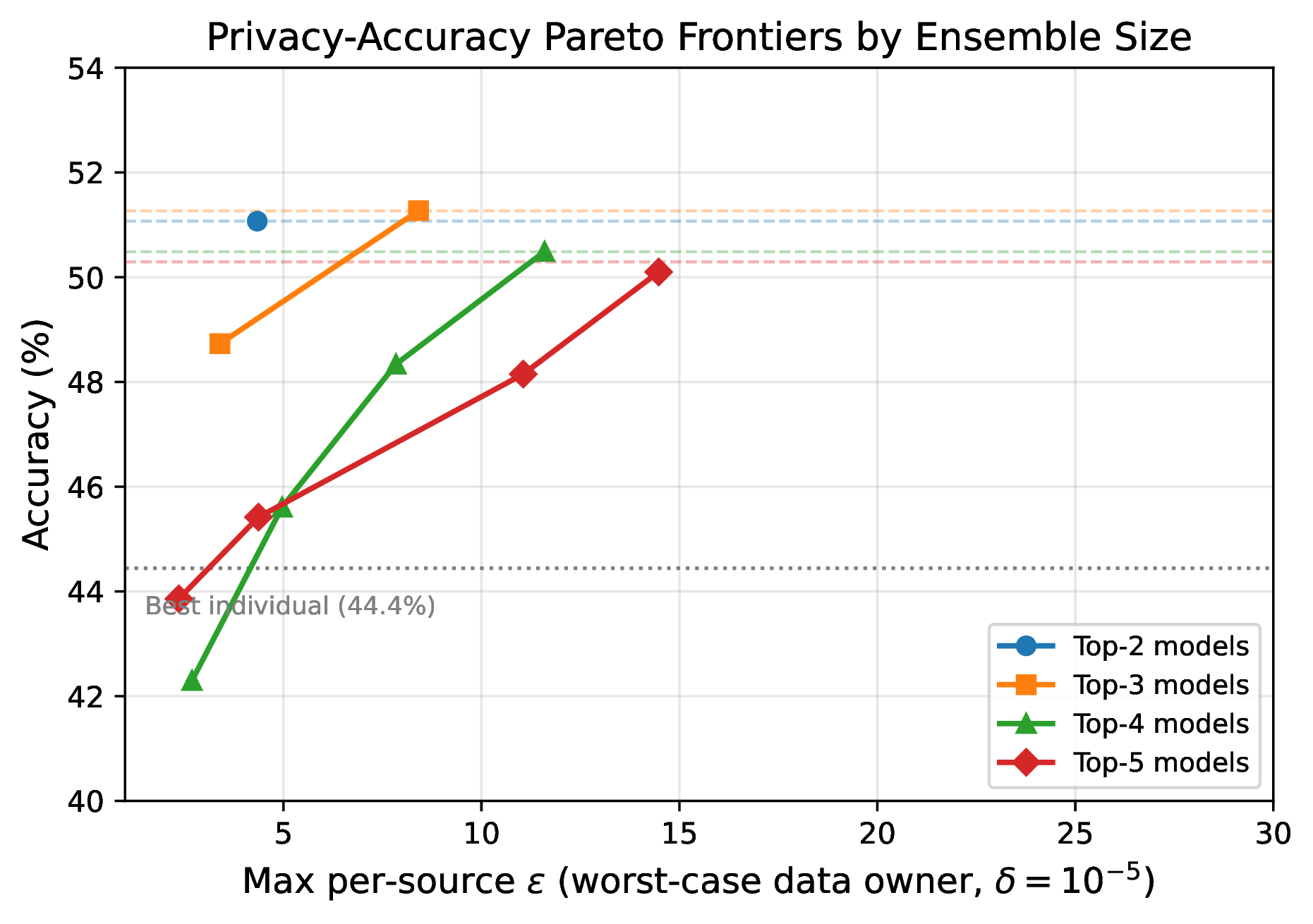
저자의 결론은 단호하다.
오늘 이후로 세계에서 가장 능력 있는 AI 시스템을 원한다면, 그것은 오직 라우팅·가중 앙상블된 더 약한 모델들의 조합에서만 얻을 수 있다. 어떤 단일 프런티어 AI 시스템도 능력의 최전선에 다시 도달하지 못할 것이다.
속도(Speed)
오픈소스 모델 호스팅 업체는 빠르고 싸게 결과를 내야만 돈을 번다. OpenRouter의 독립 측정은 기업의 영업 자료가 아닌 실제 운영 결과를 보여준다.
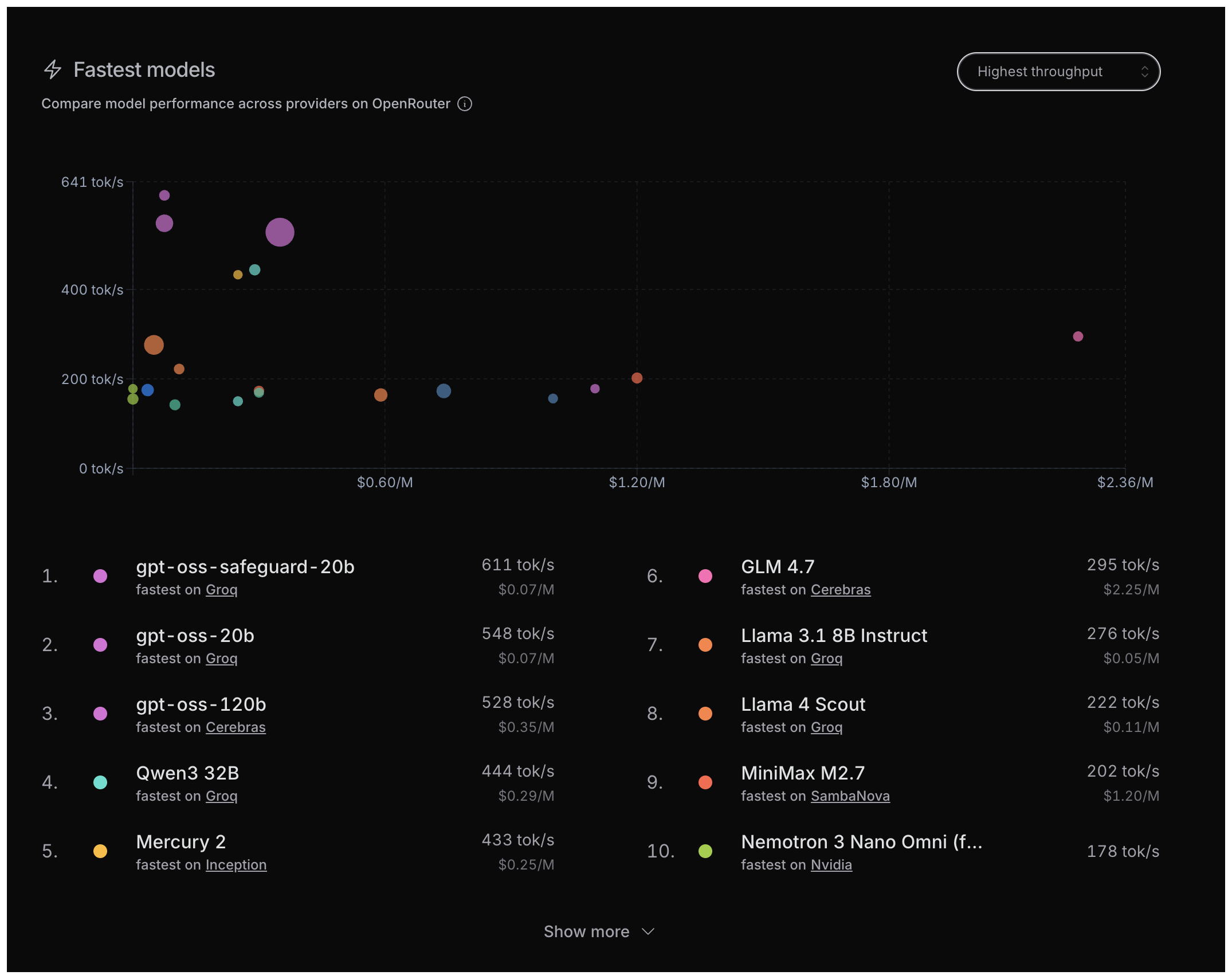
비용(Cost)
오픈소스 모델은 추론 비용 수준에서 제공되며, 학습 비용은 사실상 무료로 풀린다. 같은 수준의 지능 단위당 가격은 이미 더 싸다. 다만 그동안은 최고 수준의 지능을 얻으려면 중앙집중형 AI가 유일한 길이라는 GAP이 존재했다.
이 GAP이 지금 덮어쓰이고 있다. 글 작성 시점에 Fable/Mythos 수준 성능을 가장 싸게 얻는 방법은 더 이상 Fable/Mythos가 아니다. GPT와 Opus의 어떤 조합(심지어 Opus를 자기 자신과 결합한 경우 포함)이라도 그것이다.
게다가 이 차트에서 빠진 것이 하나 더 있다. 모델을 더 추가하면 능력은 계속 올라간다. 마침 이 글이 발행되는 날 새 Kimi 모델이 공개됐는데, 이는 Opus나 GPT-5.5와 결합되어 Fable 수준에 더 싸게 도달할 것이라고 저자는 단언한다. 이유는 명확하다. Kimi K2.7은 OpenRouter가 앙상블한 모델들 중 Fable을 제외한 모든 모델보다 이미 낫기 때문이다.
플레이북은 이렇다.
임의의 프런티어 AI 모델을 잡고, 그다음으로 좋은(더 싼) 프런티어 모델을 찾고, 거기에 선두 오픈소스 모델을 앙상블한다. 이제 더 싼 버전의 프런티어가 생긴다. 그리고 그것은 재귀한다. 더 큰 앙상블, 더 나은 라우터, 더 좋은 정확도, 더 낮은 비용.
히드라 효과(The Hydra Effect)
중앙집중형 AI가 반응할 수 없는 이유는 20세기 후반 메인프레임 컴퓨팅 회사들의 문제와 같다. 인터넷이 전화선을 통해 메인프레임을 연결하기 시작한 순간, 메인프레임의 네트워크는 언제나 개별 메인프레임보다 강했다.
더 강한 메인프레임을 인터넷에 맞서 추가할 때마다, 인터넷은 그 메인프레임을 자기 네트워크로 흡수해 더 강해졌다. (…) 단일 회사가 AI의 최전선을 소유하는 것은 이제 불가능하다. 배는 떠났다. 게임은 끝났다.
이론적 근거 — 정확도
저자는 ML 연구자로서의 자기 이력을 앵커로 끌어와, 정확도에서 앙상블이 이기는 이유를 풀어낸다(ICML 2015 1저자 구두발표 → Oxford → DeepMind 합류).
2010~2020년 NeurIPS에서 SOTA를 받으면 출판이 됐고 그러면 톱티어 대학원에 갔다. 모두가 그것에 매달렸다. 그런데 너무 신뢰성 있게 SOTA를 만들어 내는 방법이 하나 있었고, 그것은 금지됐다. 여러 모델을 가중 앙상블하면 거의 항상 더 나은 정확도를 얻는다. 같은 모델을 여러 번 학습시킨 버전들을 앙상블해도 그렇다(!!).
원리는 단순하다. 서로 다른 AI 모델은 서로 다른 실수를 한다. 출력을 합치면 실수들이 상쇄되어 더 정확한 예측이 나온다. 잘 하려면 가중치를 조정해야 한다는 정도의 뉘앙스가 있을 뿐이다.
웃긴 부분은, 학회에서 금지되니까 논문에서도 사라졌고, 그래서 사람들이 잊어버렸다는 것이다.
이론적 근거 — 비용
거대 신경망 뭉치는 현재 형태로는 말도 안 되게 비효율적이다. 그래서 그 비효율을 공격하는 것만으로도 AI 비용은 연 10~900배씩 떨어진다. 저자는 알고리즘적 요인 — 캐싱과 인덱싱 — 에 집중한다.
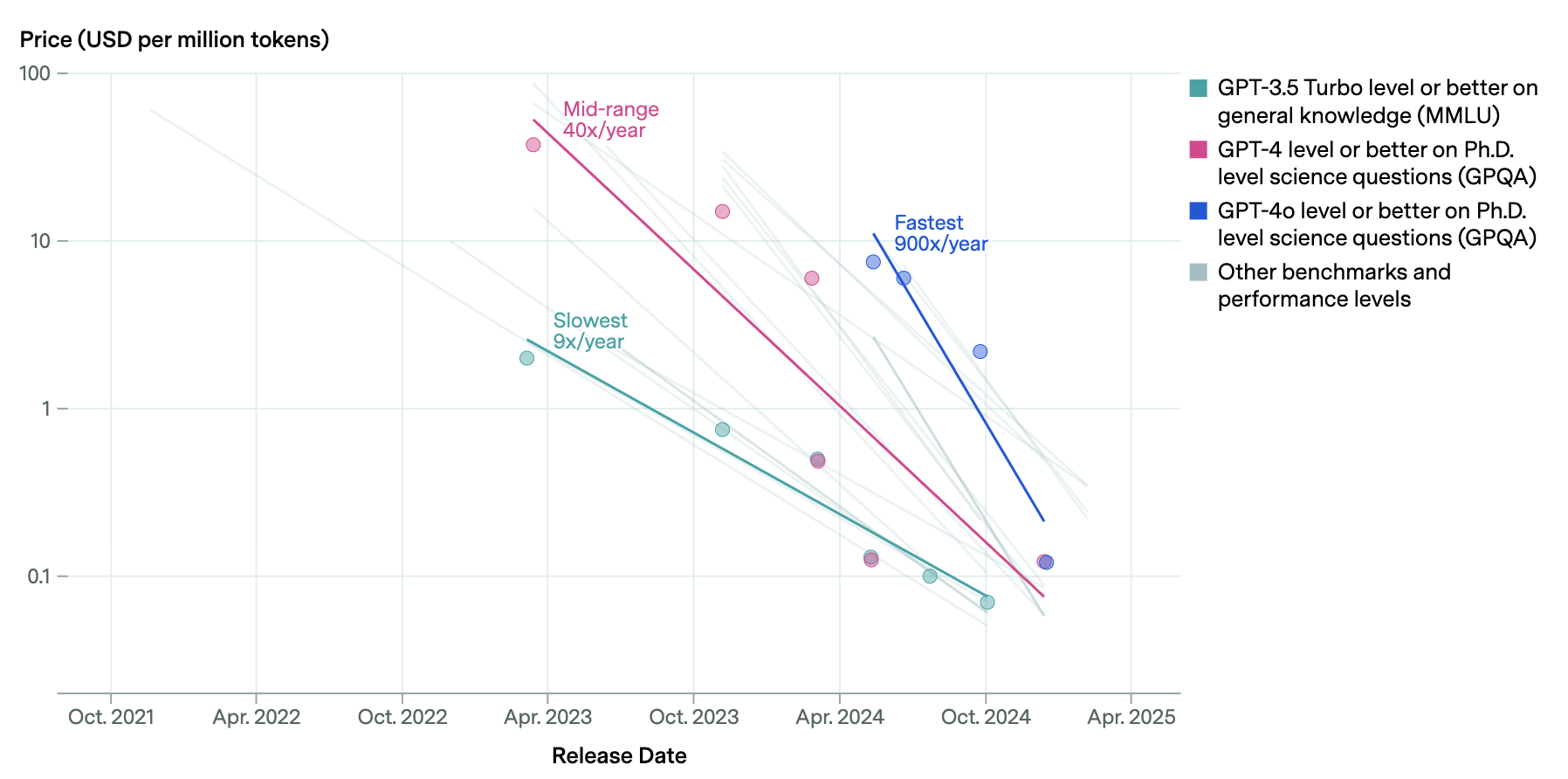
여기서 글 전체의 백미인 사서 비유가 등장한다.
도서관에 갔다고 상상해 보라. 사서에게 “체스 규칙이 뭐예요?“라고 물었다. 사서가 “잠시만요” 하고는 도서관 전체의 모든 책의 모든 페이지를 다 읽고 와서 (드럼롤) 토큰 한 개를 준다.
이게 GPT-3가 한 일이다. 모든 토큰을 생성할 때마다 거의 모든 뉴런을 사용했다. 그리고 기억하라 — 세계의 모든 지식이 그 뉴런들 안에 있다!
DeepSeek 모멘트의 단순한 아이디어는 “그러면 도서관에 섹션이 있으면 어떨까?“였다. 사서가 체스 섹션으로 걸어가서 더 빨리 결과를 가져올 수 있다는 것이다.
그리고 이것이 가리키는 AI의 이상적 상태는 단순한 Mixture of Experts가 아니라 Mixtures of Mixtures of Experts다. 인덱싱이다. 사서가 실제로 하는 일은 이렇다.
- 섹션: 게임 섹션으로 걸어간다
- 선반: 체스 책 선반을 찾는다
- 책: 책등을 훑어 “체스 입문서” 같은 책을 찾는다
- 챕터: 목차에서 “규칙 개요” 항목을 찾는다
- 문단: 규칙을 한눈에 보여 주는 문단을 찾아 들고 온다
이것이 모든 선반의 모든 책의 모든 페이지를 토큰마다 읽는 것보다 십억 배 효율적이다. AI도 같은 방향으로 가고 있다. 가장 빠르고 가장 싼 옵션은 세상의 뉴런들에 대한 거대한 인덱스이며, 전 세계 신경망의 네트워크는 지금까지 만들어진 가장 거대한 캐시+인덱스다. 네트워크 위의 각 모델이 캐시이고, 라우터가 인덱스다.
이론적 근거 — 속도
“여러 모델을 결합하면 단일 모델보다 느리지 않은가?“라는 의심에 대해 저자는 이렇게 답한다. 첫 토큰까지의 시간(time to first token)은 느려질 수 있지만, 전체 tok/s는 그렇지 않다. 50개 모델을 병렬로 호출해 다른 모델로 결합하면 지연(latency)은 손해를 보지만 대역폭(bandwidth)은 동일하다. 스트리밍이 사용자에게 들어온다.
Part 2: 지정학의 게임은 끝났다
AI는 사용된 데이터·연산·인재의 양만큼만 능력을 가진다. 그리고 AI 모델을 앙상블하면 그것은 곧 데이터·연산·알고리즘을 암묵적으로 결합하는 것이다. 스케일링 법칙은 앙상블이 이긴다고 말한다. 그래서 지정학적으로 질문이 바뀐다 — 어느 국가가 AI 경쟁에서 이기는가?
저자는 세 시기로 나눈다.
| 시기 | 패러다임 | 특징 |
|---|---|---|
| 2010~2026 | Company-Level AI | 데이터·연산·인재를 모을 수 있는 가장 큰 회사가 가장 강한 AI를 만든다(Google, Microsoft, OpenAI, Anthropic 등). |
| 2026 | Nation-Level AI | 국가가 데이터·연산·인재를 동원해 AI를 국유화한다. 중국이 유리한 위치, 미국은 자국 AI 회사 50% 지분을 만지작거리며 누가 모델을 사용할지 통제한다. |
| 2026~Forever | World-Level AI | 우리는 이 단계(Nation-Level)를 건너뛴다. 미국이 Fable을 금지하자, 24시간 안에 OpenRouter가 Fable보다 나은 품질을 제공했다. |
저자는 이를 TCP/IP/HTTP/WWW의 재현으로 본다.
메인프레임 컴퓨팅이 한창일 때 “세계엔 5대 정도의 메인프레임이면 충분하다"는 말이 떠돌았다. 하지만 그것이 일어나지 않은 이유는 같은 패러다임 — 네트워크는 노드보다 크다 — 때문이다. 미국과 유럽은 회사 단위 컴퓨팅에서 국가 단위를 건너뛰고 곧장 세계 단위 컴퓨팅으로 갔다. 그리고 50년간 정보 기술의 방향을 결정했다.
그래서 국가 정부에서 일하는 사람이 이 글을 읽고 있다면, 저자의 조언은 분명하다. 세계 단위 AI가 테이블 위에 있는데 국가 단위 AI에 머무르려는 것은 멍청한 짓이다. 자신을 벽으로 가두면 글로벌 네트워크에서 격리되고, 중간 권력(middle powers)이 중심 권력보다 먼저 올라설 것이다.
Part 3: 문화의 게임은 끝났다
사회적 자본은 가장 능력 있거나 가장 인기 있는 AI 시스템을 가진 자에게 흘렀다. AlphaGo의 DeepMind, ChatGPT의 OpenAI, Claude의 Anthropic 등. 그러나 이것은 더 이상 지속 불가능하다.
또 이 흐름은 AI에 대한 의인화(Anthropomorphism)도 뒤집어 놓는다.
명백히 하이브 마인드이고 그 집합 지능의 개별 행위자가 자신의 기여를 언제든 켜고 끌 수 있을 때, 그것이 단일한 마음이라고 주장하기는 어렵다. 우리는 지능을 위한 경제(economy for intelligence)를 갖게 된다.
결론 — 14개 패러다임 전환
저자는 결론에서 이전 패러다임 → 이후 패러다임의 대비표를 제시한다.
| 이전 패러다임 | 이후 패러다임 |
|---|---|
| 오픈/클로즈드 소스 AI | network-source AI |
| 회사 단위 AI | 세계 단위 AI |
| 중앙집중 | 연방·분산 AI |
| 데이터 식민주의 | 데이터 주권 |
| 감시 | 프라이버시 |
| 공정 이용(fair use) | 저작권(!) |
| 사일로된 데이터 | 글로벌 연결 데이터 |
| 핵무기로서의 AI | 인터넷으로서의 AI |
| 단일한 마음으로서의 AI | 정신 모델의 열린 마켓플레이스 |
| 통제의 상실 | 집단 통제 |
| AI 편향 | 대표성 있는 질의(representative queries) |
| 담장 친 정원(walled gardens) | 상호운용성 |
| 허위 정보 | 귀속 기반 신뢰 사슬(attribution-based chains of trust) |
| AI의 일방적 통제 | AI의 귀속 기반 통제(attribution-based control) |
| 딥 러닝(deep learning) | 딥 보팅(deep voting) |
| 방송(broadcasting) | 광청취(broad listening) |
저자는 단기적으로는 시장과 담론 사이의 부정합 때문에 기득권이 한동안 버틸 것이라고 본다. 시장 조정이 오면 자가 호스팅 오픈소스 모델 + 사용자/기업 간 P2P 연결로의 급격한 이동이 일어난다. 장기적으로는 JCR Licklider가 1968년에 쓴 “The Computer as a Communications Device”의 비전이 완성된다고 말한다. 그 논문의 마지막 1/3이 에이전트에 관한 내용이라는 사실은 흥미롭다 — AI 에이전트에 대한 비전이 1968년에 이미 있었다는 것이다.
가장 흥미로운 지점
이 글에서 가장 인상적인 두 대목은 NeurIPS에서 가중 앙상블이 금지됐다는 일화와 사서 비유다.
전자는 통념을 뒤집는 폭로의 톤이 강하다. SOTA 경쟁에서 가중 앙상블이 너무 잘 동작해서 학회가 그것을 금지했고, 그래서 논문에서 사라졌고, 그래서 분야 전체가 그 사실을 잊어 버렸다는 서사다. 만약 이것이 사실이라면, “왜 지금 작은 모델의 네트워크가 단일 거대모델을 이기는가"라는 질문에 대한 가장 강력한 이론적 정당화가 된다. 동시에 학회의 룰이 어떻게 한 분야의 집단 기억을 왜곡할 수 있는가에 대한 사례 연구이기도 하다.
후자는 비용 섹션 전체를 하나의 시각적 훅으로 압축한다. 도서관 전체를 다 읽고 토큰 하나를 주는 사서라는 이미지는, GPT-3가 매 토큰 생성에 모든 파라미터를 사용한다는 사실의 비효율을 누구나 즉시 이해할 수 있게 만든다. 그리고 그 위에 Mixture of Experts → Mixtures of Mixtures of Experts → 전 세계 신경망의 인덱싱이라는 추상화 사다리를 올린다. 비유 하나로 알고리즘의 효율 개선 경로 전체와, 그것이 왜 글로벌 네트워크에서 정점에 도달하는지를 동시에 설명해 낸다.
저자가 이 글에서 OpenMined 진영의 강령(attribution-based control, broad listening, deep voting 등)을 후반부에 깐 것은 분명히 정파성 있는 글쓰기다. 그러나 핵심 주장 — 가중 앙상블이 거의 항상 단일 모델을 이긴다, Fable 금지가 24시간 만에 우회됐다, 추론 비용이 연 10~900배씩 떨어진다 — 자체는 검증 가능한 사실 위에 서 있다. 이 주장들이 향후 1~2년의 AI 인프라 베팅에서 시금석 역할을 할 가능성이 높다.
출처
저자: Andrew Trask (Oxford / OpenMined) 발행: 2026-06-14, Andrew Trask’s Substack 원문: https://andrewtrask.substack.com/p/breaking-todays-frontier-ai-companies