3줄 요약
- SkillOpt는 Microsoft가 2026년 5월 공개한 자연어 기술 문서 옵티마이저다. 모델 가중치는 그대로 두고,
skill.md한 장을 딥러닝 학습 루프처럼 반복 갱신하여 LLM 에이전트의 능력을 키운다.1 - 동작 전제는 태스크가 자동으로 채점 가능해야 한다는 것이다. 6개 채점 가능한 벤치마크에서 7개 모델 × 3개 실행 환경의 52/52 셀 모두에서 최고 또는 공동 최고를 기록했고, 학습된 스킬은 다른 모델·환경·벤치마크로 재학습 없이 전이된다.
- 추론 시점에는 옵티마이저가 사라지고
best_skill.md한 장만 남기 때문에 배포 후 추가 비용은 0이다. 학습은 만만치 않다 — 한 벤치마크당 20만~2억 토큰 정도가 소요된다.
무엇을 푸는가
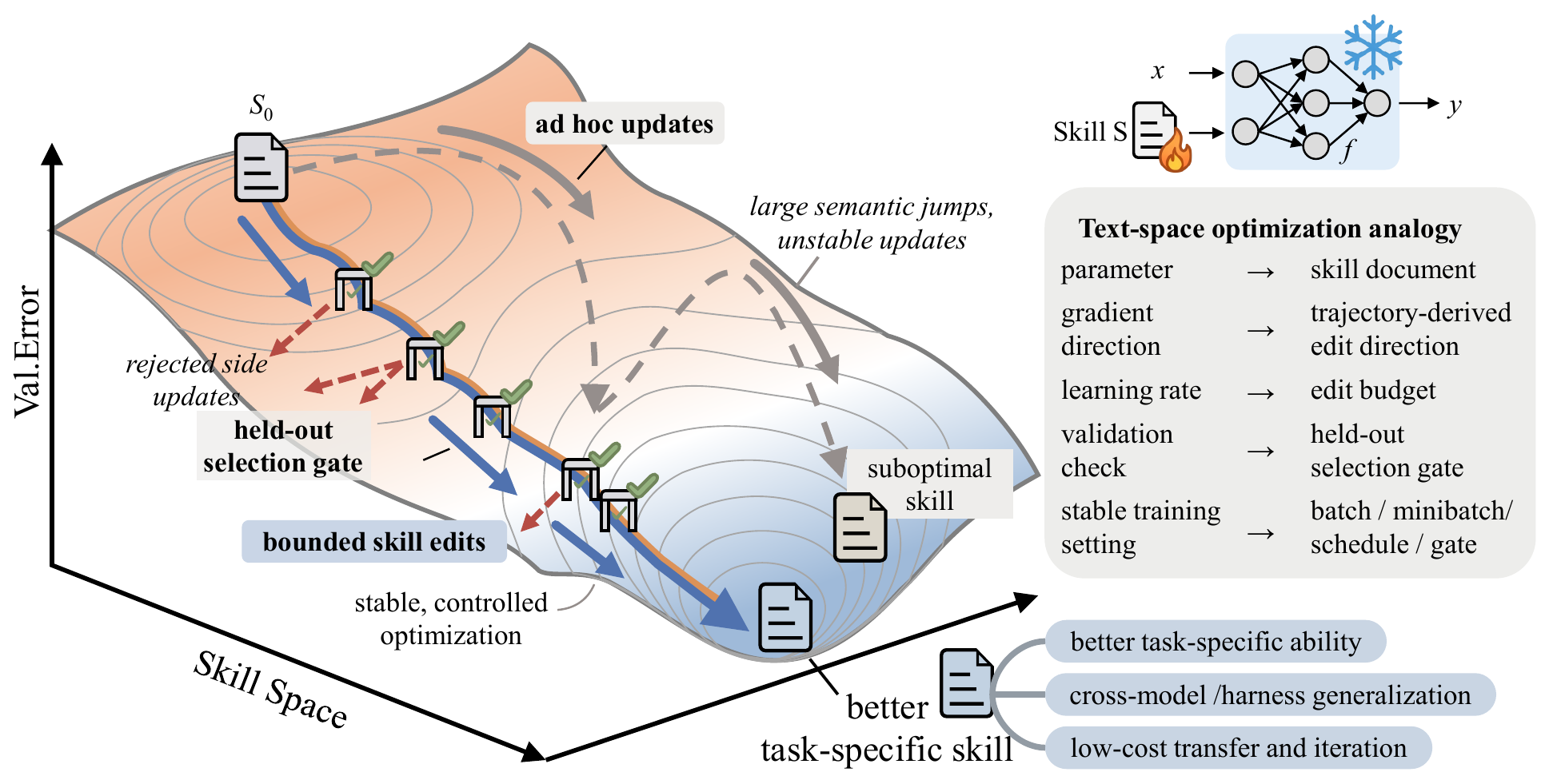
LLM 에이전트의 성능을 끌어올리는 길은 보통 둘이다. 하나는 모델 자체를 미세조정하는 길, 다른 하나는 프롬프트를 다듬는 길이다. SkillOpt는 후자에 속하면서도 결이 다르다. 재사용 가능한 자연어 기술 문서 한 장을 학습 대상으로 삼는다. 공식 소개문은 이렇다.
A text-space optimizer that trains reusable natural-language skills for frozen LLM agents through trajectory-driven edits, validation-gated updates, and deployable
best_skill.mdartifacts.
핵심 아이디어를 한 줄로 풀면 마크다운 문서를 모델 파라미터처럼 다룬다는 것이다. 학습이 끝나면 옵티마이저는 사라지고 best_skill.md 한 장만 배포 아티팩트로 남는다. 추론 시점에는 옵티마이저 호출이 일어나지 않아 추론 비용이 정확히 0이다.

저자들은 기존 접근(수작업 스킬, one-shot LLM 작성, Trace2Skill, TextGrad, GEPA, EvoSkill)이 딥러닝 옵티마이저처럼 재현 가능하게 수렴하지 않는다고 진단한다. SkillOpt는 이 문제를 체계적으로 다룬 첫 시도라고 주장한다.
발신 주체
- 저자(15인): Yifan Yang, Ziyang Gong, Weiquan Huang, Qihao Yang, Ziwei Zhou, Zisu Huang, Yan Li, Xuemei Gao, Qi Dai, Bei Liu, Kai Qiu, Yuqing Yang, Dongdong Chen, Xue Yang, Chong Luo
- 소속: Microsoft
- 공개 시점: arXiv 2026-05-22(v1) / 2026-05-25(v2). GitHub 리포는 2026-05-08 생성, 2026-05-27 기준 Stars 562·Forks 49.2
- 라이선스: MIT
- 동반 프로젝트: SkillLens3
어디서 동작하고 어디서는 동작하지 않는가
SkillOpt의 한계는 시작 지점에서부터 분명하다. 학습 목표는 다음과 같이 정의된다.
$$s^*_{\text{sel}} = \arg\max_{s \in \mathcal{C}(D_{\text{tr}})} \sum_{x \in D_{\text{sel}}} r(s)$$$\mathcal{C}(D_{\text{tr}})$는 훈련 분할에서 생성된 후보 스킬 집합, $D_{\text{sel}}$은 검증 분할, $r(s) \in [0, 1]$은 태스크 보상이다. 즉 학습이 돌려면 태스크마다 점수가 자동으로 매겨져야 한다.
논문 Appendix B에 한계가 명시되어 있다.
the optimization loop relies on scored trajectories and a held-out selection split, so it is most directly applicable when the target task has automatic verifiers, exact-match metrics, executable checks, or otherwise reliable feedback signals.
쉽게 말하면 이렇다.
- 잘 동작하는 영역: 정답이 명확한 QA, 코드가 돌아가는지 확인 가능한 생성 태스크, 시뮬레이터가 점수를 돌려주는 에이전트, 정답 라벨이 있는 문서 시각 QA. 논문이 다룬 6종 벤치마크가 모두 이 영역에 속한다.
- 회색 영역: 보상이 모델 기반 판정(LLM-as-judge)이나 사람 평가에 의존하는 영역. 가능은 하지만 검증 게이트의 신뢰성이 평가자의 품질에 묶인다.
- 거의 불가능한 영역: 자유 글쓰기, 자유 대화, 창작처럼 성공의 정의가 주관적이거나 다차원인 영역. 보상을 정의할 수 없으면 SkillOpt 루프는 시작 자체가 불가능하다.
부수 가정도 짚어 둔다. 옵티마이저 모델이 의미 있는 편집을 생성할 정도의 능력을 갖추어야 한다. 훈련 분포에서 학습된 스킬이 도메인 휴리스틱을 담을 수 있으므로 분포가 크게 다른 태스크에는 그대로 옮기지 말아야 한다고 논문이 직접 경고한다.
알고리즘 — 한 스텝 안에서 일어나는 일
논문 Appendix C.1의 Algorithm 1을 풀어 쓰면 다음과 같다.
입력: 현재 스킬 s_cur, 검증 최고 스킬 s_best, 거부 편집 버퍼 B,
옵티마이저 메모리 m_meta, 학습률 스케줄 L_t
for step in 1..steps_per_epoch:
# 1) Rollout — 동결된 대상 모델 M이 현재 스킬로 배치 실행
trajectories, rewards = M.run(batch=40, skill=s_cur)
# 2) Reflect — 옵티마이저 모델 O가 실패/성공 궤적을 분석
failures, successes = split_by_reward(trajectories, rewards)
failure_patches = [O.analyze_error(mb) for mb in minibatch(failures, 8)]
success_patches = [O.analyze_success(mb) for mb in minibatch(successes, 8)]
# 3) Aggregate — 패치들을 충돌 없이 통합
merged = O.merge(failure_patches, success_patches, buffer=B)
# 4) Edit Selection — 텍스트 학습률 L_t개만 선택 (gradient clipping)
top_edits = O.rank_and_pick(merged, top_k=L_t)
# 5) Apply — 후보 스킬 생성. SLOW_UPDATE 보호 구역은 건드리지 않음
s_tilde = apply_atomic_ops(s_cur, top_edits) # append/insert_after/replace/delete
# 6) Validation Gate — 엄격 개선만 수락
if score(s_tilde, D_sel) > score(s_cur, D_sel):
s_cur = s_tilde
if score(s_tilde, D_sel) > score(s_best, D_sel):
s_best = s_tilde
else:
B.append(top_edits) # 거부된 편집은 다음 스텝의 reflect에 참조됨
# 에폭 경계 — Slow Update + Meta Skill
delta = compare_on_fixed_set(s_prev_epoch, s_cur, n=20)
protected_block = O.write_slow_update(delta)
if score(s_cur_with(protected_block), D_sel) > score(s_cur, D_sel):
s_cur = s_cur_with(protected_block)
m_meta = O.update_meta(edit_history, m_meta) # 배포본에는 포함되지 않음

각 단계가 딥러닝 훈련 루프에서 무엇에 대응하는지 정리하면 다음과 같다.
| 단계 | 딥러닝 대응 | 내용 |
|---|---|---|
| Rollout | Forward Pass | 동결된 대상 모델이 현재 스킬로 훈련 배치(기본 40개)를 실행하고 궤적·보상을 수집한다. |
| Reflect | Backward Pass | 옵티마이저 모델이 실패·성공 궤적을 미니배치(기본 8)로 나눠 분석하고 add / delete / replace / insert_after 편집 패치를 JSON으로 돌려준다. analyst worker 16개가 병렬로 돌린다. |
| Edit Selection | Gradient Clipping | 후보가 K개일 때 옵티마이저가 중요도 순위를 매기고 상위 $L_t$개만 채택한다. |
| Validation Gate | Early Stopping | 후보 스킬을 검증 분할에서 평가한다. 엄격한 부등호로 평균 점수가 올랐을 때만 수락한다. 동점은 거부다. |
에폭 단위 메커니즘
- Slow Update (Momentum): 에폭 경계에서 이전 에폭 스킬과 현재 스킬로 같은 20개 태스크를 풀어 어떤 케이스에서 좋아졌고 어떤 케이스에서 나빠졌는지 분류한다. 그 결과를 마크다운 안의
<!-- SLOW_UPDATE_START -->~<!-- SLOW_UPDATE_END -->보호 구역에 적어 둔다. 스텝 단위 편집은 이 보호 구역을 수정할 수 없다. - Meta Skill (Meta-Learning): 에폭 사이의 옵티마이저 전략 메모리. 어떤 편집 방향이 통했고 어떤 방향이 통하지 않았는가를 옵티마이저 측에 저장한다. 배포 아티팩트인
best_skill.md에는 포함되지 않는다. - Rejected-Edit Buffer: 거부된 편집 패턴을 같은 에폭 내 이후 reflect 단계에 참조시켜 같은 실수를 반복하지 않게 한다.
학습률 스케줄 4종
| 스케줄 | 동작 |
|---|---|
| constant | 매 스텝 max_lr 고정. |
| linear | $L_t = \text{round}(\text{max\_lr} + (\text{min\_lr} - \text{max\_lr}) \cdot t / T)$. |
| cosine | $L_t = \text{round}(\text{min\_lr} + 0.5 \cdot (\text{max\_lr} - \text{min\_lr}) \cdot (1 + \cos(\pi t / T)))$. |
| autonomous | 옵티마이저가 현재 점수와 후보 편집을 보고 “몇 개를 적용할지” 매 스텝 직접 결정. |
기본값은 max_lr=4, min_lr=2, cosine 감쇠다.
주요 하이퍼파라미터
| 파라미터 | 기본값 | 비고 |
|---|---|---|
| epochs | 4 | 4 에폭 고정 실행이 기본. |
| rollout batch | 40 | 한 스텝의 훈련 배치 크기. |
| reflect minibatch | 8 | 실패·성공을 나눠 분석하는 단위. |
| analyst workers | 16 | reflect 병렬도. |
| max_analyst_rounds | 3 | 패치 생성 재시도 한도. |
| slow update samples | 20 | 에폭 경계에서 비교할 태스크 수. |
| 데이터 분할 (train:sel:test) | 2:1:7 | 일부 실험은 4:1:5. |
| 최소 훈련 예시 | 1 | Table 2(a)에서 1개로도 유의미한 개선 확인. |
실험 결과
벤치마크 6종
| 벤치마크 | 유형 | 채점 방식 |
|---|---|---|
| SearchQA | 문서 기반 QA | exact match |
| ALFWorld | 체화 에이전트 | 시뮬레이터 |
| DocVQA | 문서 시각 QA | exact match |
| LiveMathematicianBench | 수학 | exact match |
| SpreadsheetBench | 코드 생성 | 실행 결과 비교 |
| OfficeQA | 도구 증강 QA | rubric |
여섯 가지 모두 자동 채점 가능한 태스크다. 비교 베이스라인은 수작업 스킬, one-shot LLM, Trace2Skill, TextGrad, GEPA, EvoSkill이다.
GPT-5.5 Direct Chat — 스킬 없음 대비 개선
| 벤치마크 | No-Skill | SkillOpt | 개선 |
|---|---|---|---|
| SearchQA | 77.7 | 87.3 | +9.6 |
| SpreadsheetBench | 41.8 | 80.7 | +38.9 |
| OfficeQA | 33.1 | 72.1 | +39.0 |
| DocVQA | 78.8 | 91.2 | +12.4 |
| LiveMathematicianBench | 37.6 | 66.9 | +29.3 |
| ALFWorld | 83.6 | 95.5 | +11.9 |
| 평균 | +23.5 |
셀별 최강 베이스라인과 비교해도 평균 +5.4포인트 우위다.
세 가지 실행 환경
| 환경 | 평균 개선 (vs 스킬 없음) | 비고 |
|---|---|---|
| Direct Chat | +23.5 | |
| Codex agentic loop | +24.8 | EvoSkill 대비 +14.0 |
| Claude Code | +19.1 | EvoSkill 대비 +3.2 |
에폭별 성능 트렌드

전이 학습
- 크로스 모델 (SpreadsheetBench 스킬): GPT-5.4 → GPT-5.4-mini +9.4, GPT-5.4-nano +3.0.
- 크로스 환경: Codex에서 학습한 스킬을 Claude Code로 옮길 때 +59.7(22.1 → 81.8).
- 크로스 벤치마크: OlympiadBench 스킬 → Omni-MATH 전이에서 GPT-5.4 +3.7, mini +1.8, nano +1.3.
논문이 보고한 모든 전이 셀에서 양의 전이만 관찰되었고, 음의 전이는 없었다. 다만 같은 환경끼리의 전이가 더 크고, 분포가 멀어질수록 격차가 줄어든다.
어블레이션 주요 수치
- 학습률(LR) 제거 시 3개 벤치마크에서 87.1 / 77.5 / 61.3 → 84.6 / 75.7 / 57.3 으로 저하.
- Slow / meta update 제거 시 SpreadsheetBench -22.5포인트.
- Rejected-edit buffer 제거 시 -1.6~-4.6포인트.
옵티마이저 모델의 강도
옵티마이저 모델과 대상 모델은 같아도 되고 달라도 된다. Table 5는 대상 모델이 옵티마이저를 겸할 때 강한 옵티마이저 대비 효과의 56~74% 정도를 회수한다고 보고한다. 학습 비용이 부담된다면 약한 옵티마이저로도 절반 이상의 개선을 얻을 수 있다는 뜻이다. 배포 비용은 둘 다 0이다.
비용과 문서 크기
- 최종 스킬 문서 규모: 379~1,995 토큰 (중앙값 약 920 토큰).
- 학습 토큰: 벤치마크에 따라 20.8M~213.8M. 가장 무거운 쪽은 SearchQA·DocVQA, 가장 가벼운 쪽은 SpreadsheetBench·OfficeQA·LiveMath.
- 최종 스킬에 도달하기까지 수락된 편집 수: 1~4개, 중앙값 2.5. LiveMath의 +29.3포인트는 단 1회 편집에서 비롯되었다.
- 달러 비용은 논문에 명시되지 않았다.
학습된 스킬은 어떻게 생겼나
논문 Figure 4가 최종 best_skill.md의 일부를 공개한다. 분량은 절차적 지침 2~4개. 톤은 인간 실무자가 며칠 써본 뒤 동료에게 남길 법한 조건-행동 형식이다. 예를 들면 이렇다.
SearchQA: Infer the expected answer type from clue wording, then choose the shortest canonical entity supported by co-occurring distinctive evidence.
SpreadsheetBench: Inspect workbook structure and formulas, then write evaluated static values across the full requested target range instead of relying on Excel recalculation.
ALFWorld: Keep a horizon-aware visited/frontier ledger, diversify search after repeated same-type failures, and avoid revisiting the destination until holding the target.
특정 태스크 인스턴스를 외우지 않고, 일반화된 절차 형태로 정착하는 것이 특징이다. 1~3문장짜리 규칙 2~4개가 전부지만, 그 안에 모델이 반복해서 놓치던 실수를 메꾸는 단서가 들어 있다.
제약과 실패 모드 — 정리
논문이 명시한 제약을 한 번에 모아 둔다.
- 자동 채점 가능성 필수. 보상 함수가 없으면 검증 게이트가 작동하지 않는다. 창작·자유 글쓰기·자유 대화에는 그대로 옮기지 못한다.
- 분포 휴리스틱 유입 가능. 훈련 분포의 특수성이 스킬에 그대로 자리 잡는다. 분포가 크게 다른 태스크로 옮기기 전에 검증이 필요하다.
- 수렴 보장 없음. 검증 게이트가 퇴보를 막아 줄 뿐 수학적 수렴 증명은 없다. Slow update / meta update를 제거하면 SpreadsheetBench에서 -22.5포인트가 빠지는 불안정도 관찰된다.
- 옵티마이저 능력 요구. 약한 옵티마이저로도 절반 이상의 효과를 얻지만, 매우 약한 모델이라면 모든 편집이 게이트에서 거부되어 학습이 진행되지 않을 수 있다.
- 명시적 실패 케이스 부재. 논문은 성공 케이스 두 건(ALFWorld, SpreadsheetBench)의 정성 분석만 싣는다. 어떤 경우에 실패하는가에 대한 case study가 없다는 점은 한계로 남는다.
리포 구조와 사용법
SkillOpt/
├── skillopt/
│ ├── engine/trainer.py # 훈련 루프 메인
│ ├── optimizer/ # LR·스케줄러·슬로우/메타 업데이트·rewrite
│ ├── gradient/ # Reflect (역전파 대응)
│ ├── evaluation/gate.py # 검증 게이트
│ ├── envs/ # alfworld, docvqa, searchqa, spreadsheetbench, ...
│ ├── model/ # azure_openai, claude, codex, qwen
│ └── prompts/ # 옵티마이저·반성 프롬프트 .md 모음
├── scripts/train.py # 훈련 진입점
├── scripts/eval_only.py # 평가 전용 진입점
├── configs/ # 벤치마크별 YAML 설정
├── skillopt_webui/app.py # Gradio 모니터링 대시보드
└── docs/guide/ # dl-analogy.md, training-loop.md
지원 백엔드는 Azure OpenAI, OpenAI, Anthropic Claude, Qwen(로컬 vLLM)이다.
설치와 최소 학습 명령:
git clone https://github.com/microsoft/SkillOpt.git[^microsoft-github][^github-microsoft]
pip install -e .
python scripts/train.py \
--config configs/searchqa/default.yaml \
--split_dir /path/to/split \
--optimizer_model gpt-5.5 \
--target_model gpt-5.5
출력물은 outputs/<run>/best_skill.md(배포 아티팩트), history.json, 그리고 skills/skill_vXXXX.md 스냅샷 체인이다.
가장 흥미로운 지점
가장 먼저 눈에 띄는 것은 편집 경제성이다. 벤치마크 전반에서 단 1~4회의 수락된 편집만으로 최대 +39포인트 개선이 나왔고, LiveMathematicianBench의 +29.3포인트는 단 한 번의 편집에서 비롯되었다. 잘 쓰인 자연어 한 단락이 가중치 미세조정의 상당 부분을 대체할 수 있다는 신호다.
크로스 환경 전이의 비대칭도 흥미롭다. Codex에서 학습한 스킬을 Claude Code로 옮길 때 +59.7포인트라는 큰 도약이 나타났는데, 정작 Claude Code 환경 자체에서의 SkillOpt 개선 폭(+19.1)은 Direct Chat(+23.5)보다 작다. 실행 환경 간 스킬 호환성이 균일하지 않다는 뜻이며, “어디에서 학습해서 어디로 옮길 것인가"라는 스킬 분업 설계 문제를 새로 연다.
Slow update가 가중치 공간의 모멘텀을 그대로 모사한다는 점도 깔끔하다. 이전·현재 스킬을 같은 태스크에 적용해 비교하는 방식이 단순한데, 이를 제거하면 SpreadsheetBench에서 -22.5포인트가 빠진다. 텍스트 공간에서도 과거 상태를 명시적으로 보존하고 비교하는 메커니즘이 그만큼 중요하다는 증거다.
마지막으로 짚고 싶은 것은 어디까지가 SkillOpt의 영역인가다. 채점 가능한 6종 벤치마크에서의 완승은 분명한 성과지만, “성공의 정의가 명확한” 영역에 한정된다는 점은 잊지 말아야 한다. LLM 평가가 아직 풀지 못한 영역(창의·자유 작문·다차원 평가)은 여전히 모델 미세조정과 사람의 손에 남아 있다.
출처
- 저자: Yifan Yang 외 14인 (Microsoft)
- 공개: arXiv 2026-05-22(v1) / 2026-05-25(v2)
데모 영상: https://youtu.be/JUBMDTCiM0M ↩︎
동반 프로젝트(SkillLens): https://microsoft.github.io/SkillLens/ ↩︎