
3줄 요약
- tapehead.lab은 X·YouTube에서 AI MV를 만드는 일본 크리에이터다. 신곡 「불쌍한 지성(かわいそうな知性)」 MV에 쓴 콜라주 애니메이션 워크플로우를 note.com에 정리해 공개했다.1
- 워크플로는 ① Midjourney로 단편 소재 20장 생성 → ② Runway 노드 환경에서 Seedance2.0에 5장씩 Reference로 넣어 15초 시퀀스 88본(총 22분 넘는 분량) 생성 → ③ 편집한 뒤 영상에 맞춰 음악을 거꾸로 만드는 역순 마감으로 이어진다.
- 두 가지 명제가 핵심이다. 입력 슬롯을 Start Frame이 아니라 Reference로 두면 모델은 이미지의 분위기만 가져가고 동작은 프롬프트가 정한다. 그리고 Seedance2.0은 프롬프트가 전부 — 같은 5장의 레퍼런스라도 프롬프트만 바꾸면 결과가 크게 달라진다.

그리는 사람이 아니라 찍는 사람
이 워크플로의 결을 한 줄로 옮기면 그린다가 아니라 찍는다에 가깝다. 사진가는 한 번도 카메라를 가챠라고 부르지 않는다. 풍경과 조명과 모델은 통제할 수 없는 세계이고, 자기 일은 조건을 세팅하고, 많이 찍고, 추리고, 후처리하는 것이라고 받아들이기 때문이다. tapehead.lab의 단계는 정확히 그 구조다. 모델은 통제할 수 없는 세계이고, 프롬프트와 레퍼런스는 카메라 세팅이며, 22분 분량의 출력은 컨택트 시트이고, 편집은 셀렉트와 라이트룸이다. AI 이미지 생성을 두고 “통제 불능 가챠"라는 한탄이 자주 들리지만, 그건 회화의 패러다임을 기대했을 때 나오는 한탄이다. 사진의 패러다임으로 옮겨두면 같은 작업이 정상 워크플로가 된다.
① Midjourney 단편 소재 모으기
콜라주 영상은 완성된 한 장의 그림이 아니라 분리되고 재조합될 수 있는 단편을 필요로 한다. tapehead.lab은 처음부터 “단편적인 소재를 모은다(断片的な素材を集める)“는 자세로 이미지 풀을 만든다고 적었다. 완성도 높은 그림은 오히려 콜라주 단계에서 결합이 막힌다.

스타일 통일은 두 가지 손잡이로 잡는다. 첫째, Midjourney의 sref(스타일 레퍼런스)를 조합한다. 둘째, 자기 생성물을 다시 스타일 레퍼런스로 넣어 시리즈 전체의 결을 점진적으로 좁힌다. “스타일을 한 번 설정"하는 방식이 아니라 자기 출력을 피드백 루프에 넣어 결을 빚어내는 방식이다.
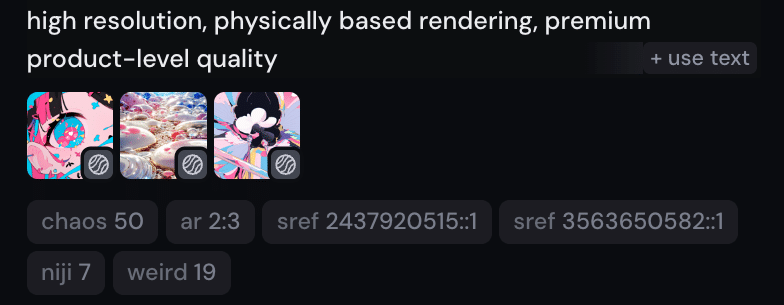
다양성은 chaos 파라미터로 의도적으로 키운다. 수치를 올리면 같은 프롬프트에서도 출력이 흩어진다. 콜라주처럼 비슷한 결의 서로 다른 조각이 필요한 작업에 잘 맞는 손잡이다.
흥미로운 점은, 이 첫 단계의 발상이 LLM 프롬프트 기법과 정확히 짝을 이룬다는 사실이다. LLM에 “평균적인 답이 아니라 90 퍼센타일의 답을 달라"라고 확률 분포를 명시해 중간 답변을 피하는 기법이 있다. Midjourney의 chaos 파라미터도 같은 일을 한다 — 평균 출력을 피하라고 모델에 명시하는 것. 매체는 다르지만, 분포의 중심에서 벗어나라는 단일 지시다.

이미지 고르는 건 감각으로! 인물뿐 아니라 신체 일부나 추상적인 오브젝트까지, 균형 있게 골라간다.
선별 기준은 분명하다. 인물 전신만이 아니라 신체 일부와 추상 오브젝트까지 의도적으로 섞는다. 풀의 카테고리 분포를 균형 있게 잡지 않으면 콜라주 결합이 단조로워지기 때문이다.
② Seedance2.0 + Runway — 통제의 무게중심을 텍스트로
호스트는 Runway. tapehead.lab이 Runway를 고른 이유는 두 가지다.
· 노드 기반 워크플로우가 너무 편하다
· Unlimited 플랜이라 크레딧 걱정 없이 시안을 굴릴 수 있다 (720p까지밖에 안 되고 생성도 느리지만…)
노드 UX는 워크플로우 관리를 쉽게 만들고, Unlimited 플랜은 크레딧 걱정 없이 시안을 굴리게 한다. 720p 상한과 느린 생성 속도라는 단점을 무한히 굴릴 수 있는 운영 방식으로 압도하는 모델이다.

Start Frame이 아니라 Reference로
가장 강한 한 줄은 이것이다.
스타트 프레임이 아니라 레퍼런스 지정으로 넣는다.
Seedance2.0의 Reference 성능이 워낙 좋아서, 이미지가 가진 분위기를 그대로 확장해 영상으로 만들어준다. 그래서 Start Frame으로 넣지 않고 Reference 입력으로 두면 모델은 색·텍스처·분위기만 가져가고 동작은 프롬프트가 정한다. 같은 이미지를 어느 슬롯에 넣느냐가 결과 성격을 완전히 가른다.
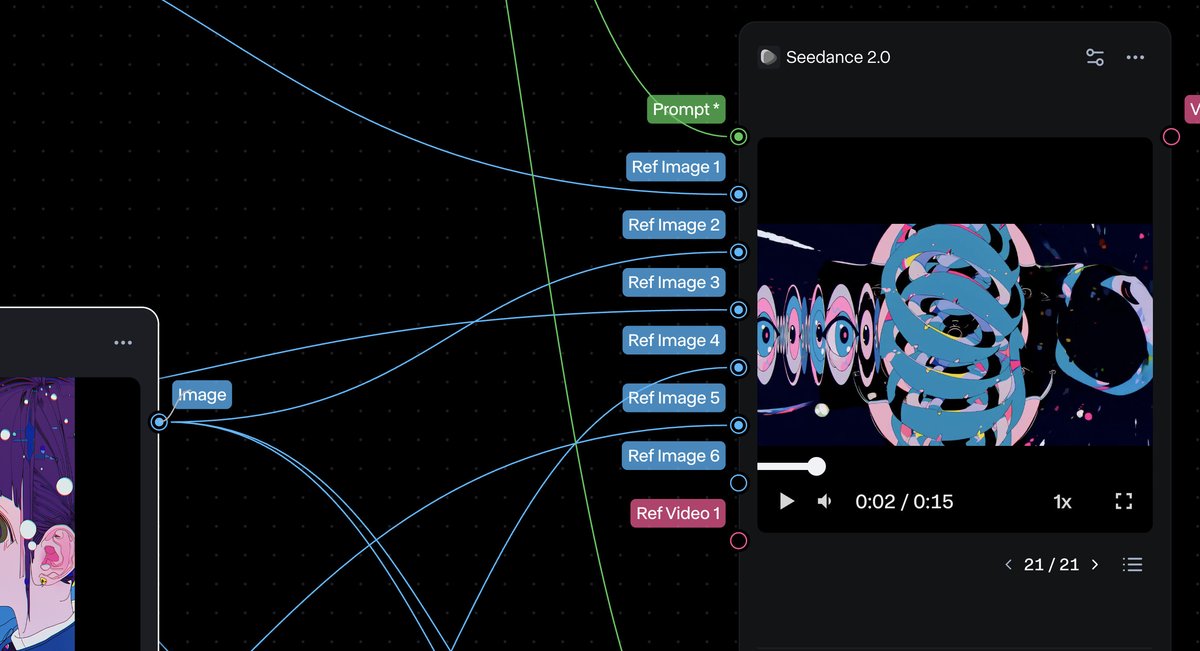
5장 × 4세트 — 풀을 쪼개 운용한다
20장을 한꺼번에 레퍼런스로 넣지 않는다. 5장씩 4세트로 나눠 노드를 4개 구성한다. 레퍼런스가 너무 많으면 모델이 산만해지고, 5장 단위로 묶으면 세트별로 결이 다른 콜라주가 안정적으로 나온다.
프롬프트를 1.5초 10블록으로 쪼갠다
① 레퍼런스 지정 지시 ② 전체 스타일과 분위기, 방향성 지시 ③ 컷별 구체적인 움직임 지시
15초 시퀀스 한 컷의 프롬프트는 사실상 시간표다. 0-1.5초, 1.5-3초, … 식으로 10블록으로 쪼개 블록마다 무엇이 어떻게 변형되는가를 구체적인 동사로 지정한다. 원문에 공개된 영문 프롬프트의 한 블록을 옮기면 이런 식이다.
0-1.5s
A figure's silhouette fills with a new color seeping inward
while its outline detaches and drifts upward.
The background inverts to a complementary color.
The surface texture flows downward against the direction of the color seep.
블록은 10단계까지 이어지고 마지막 13.5-15초 블록에서는 앞선 모든 변형을 동시에 일으켜 누적 카오스를 만든다. 영상 모델에 던지는 프롬프트가 어디까지 정교해질 수 있는지 보여주는 사례다.

프롬프트에 따라 다양한 움직임으로 콜라주가 가능하다. (Seedance2.0은 무조건 프롬프트다. 프롬프트에 따라 출력이 크게 달라진다.)
여기서 Seedance2.0은 프롬프트가 전부라는 명제가 나온다. 같은 5장의 레퍼런스라도 프롬프트만 바꾸면 결과가 크게 달라진다. 모델 통제력의 무게중심이 이미지가 아니라 텍스트 쪽에 있다는 진단이다.


③ 즐거운 편집 — 폐기 전제와 역순 마감
이번에 만든 소재의 양은 “15초 × 88본”, 합계 20분이 넘는 분량.
본편보다 훨씬 많은 양을 만들고 편집에서 추린다. 15초×88본이면 22분이 넘는 분량이다. 자원 제약이 큰 전통 영상에서는 불가능했던 대량 생성 → 대량 폐기가 AI 영상의 기본 운영 방식으로 자리 잡는다. 사진가가 컨택트 시트를 펴놓고 셀렉트하는 결과 정확히 같다.
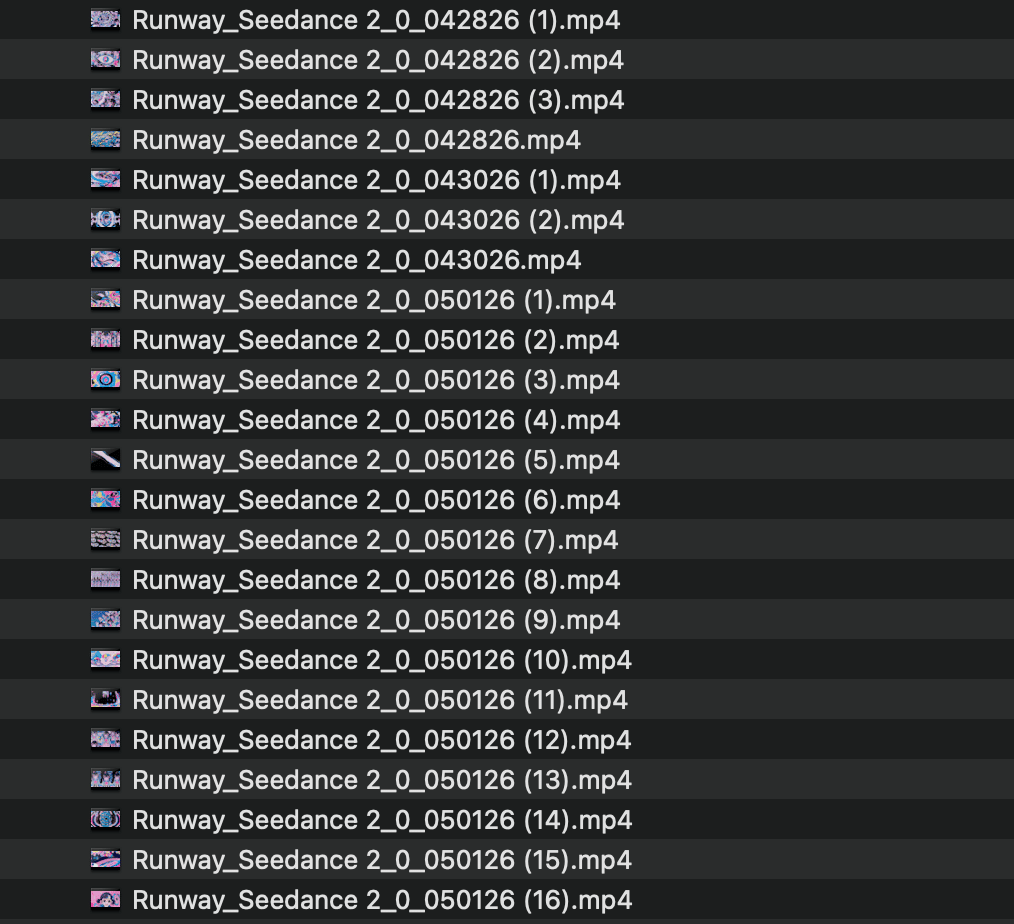
보통은 이렇게 사치스러운 애니메이션 운용은 못 한다. AI라서 가능한 짓!
그리고 더 흥미로운 지점은 영상을 먼저 만들고 음악을 나중에 작곡했다는 사실이다. 보통 MV는 곡이 먼저 있고 영상이 따라오는데, 이번에는 순서가 뒤집혔다.
이 콜라주 애니메이션을 견뎌낼 수 있는 음악이 아니면 작품이 성립하지 않을 거라고 생각했다.
콜라주에 견딜 수 있는 음악을 거꾸로 맞춘 셈이다. 더 나아가 일부 가사는 영상에서 역으로 끌어낸다. 무작위에 가까운 콜라주 영상에 의미를 부여하기 위해 가사를 영상에 맞춰 짜는 후공정이다. 시청자가 “의미가 있다"고 느끼게 만드는 장치 — AI로 영상을 양산할 수 있을 때 가능한 의도된 순서 뒤집기다.
가장 흥미로운 지점
기법 자체는 분명하지만, 가장 흥미로운 것은 이 워크플로가 사진가의 일과 거의 동형이라는 사실이다.
- 모델 ≒ 통제할 수 없는 세계
- 프롬프트와 레퍼런스 ≒ 카메라 세팅과 조명, 모델 디렉팅
- 시안 라운드 ≒ 다컷 촬영
- 88본 22분의 출력 ≒ 컨택트 시트
- 채택 ≒ 셀렉트
- 마이너 수정과 후공정 ≒ 라이트룸
사진가는 자기 실력을 몇 번째 셔터에 좋은 컷이 걸리는가로 가늠하지, 한 컷을 의도대로 잡아냈는가로 가늠하지 않는다. AI 이미지·영상 작업자의 일도 같은 결이다. tapehead.lab의 22분 컨택트 시트는 그 극단 사례일 뿐, 발상 자체는 새롭지 않다 — 단지 회화의 패러다임에서 사진의 패러다임으로 옮긴 사람들에게만 자연스럽다.
19세기에 사진이 등장하자 회화는 재현·복제·노동량을 사진에 내주고 추상·표현·붓 자국 그 자체로 옮겨갔다. AI 이미지·영상이 같은 자리에 서 있다면, 사진은 현장성·증거성·시간의 흔적으로 더 좁혀질지도 모른다. 매체끼리 영역을 재분배하는 역사적 패턴이 한 번 더 반복되는 셈이다.
그래서 이 글은 “Seedance2.0 사용법"이라기보다 AI 시대의 영상 작업은 사진가의 일에 가깝다는 사례 보고에 가깝다. 도구가 풀린 그날 새 표현이 자동으로 따라오지 않는다. 패러다임을 같이 옮긴 사람부터 새 표현을 일상적으로 만들어낸다.
출처
- 저자: tapehead.lab (@tapehead_Lab)
- 매체: note.com, 2026년 5월 18일
- 관련 작품: 「불쌍한 지성(かわいそうな知性)」 MV (2026-05-13 공개)
- 원문: https://note.com/tapehead/n/n94eaf79a519b
저자: tapehead.lab (@tapehead_Lab) ↩︎