3줄 요약
- NVIDIA Labs가 공개한 2.6B 오픈소스 비디오 월드 모델 SANA-WM. 이미지 한 장과 카메라 궤적을 입력 받아 단일 H100에서 720p·1분 영상을 생성하며, 64×H100 15일 학습이라는 비교적 작은 비용을 쓴다.
- 핵심 설계는 Hybrid Linear Diffusion Transformer. 총 20개 DiT 블록 중 5개({3, 7, 11, 15, 19})만 softmax 어텐션이고 나머지 15개는 프레임 단위 Gated DeltaNet으로, 모든 레이어가 softmax일 때 60초 지점에서 발생하던 OOM을 회피한다.
- 1분 Hard-Trajectory 벤치마크에서 RotErr 8.34°·CamMC 1.44로 LingBot-World·Matrix-Game 3.0·HY-WorldPlay·Infinite-World를 모두 앞서고, 8×H100 처리량에서는 LingBot-World 대비 36배(22.0 vs 0.6 videos/hour)다. 본 글은 프로젝트 페이지(데모)와 본 논문(method·실험)을 함께 정리한 다이제스트다.
자료의 정체
SANA-WM은 NVIDIA Labs와 외부 공저자(Haoyi Zhu, Haozhe Liu, Yuyang Zhao, Tian Ye, Junsong Chen, Jincheng Yu, Tong He, Song Han, Enze Xie)가 공개한 비디오 월드 모델이다. 풀 제목은 SANA-WM: Efficient Minute-Scale World Modeling with Hybrid Linear Diffusion Transformer.
세 곳에 자료가 흩어져 있다.
- 프로젝트 페이지: https://nvlabs.github.io/Sana/WM/12
- 논문: https://arxiv.org/abs/2605.15178 (2026-05-14, cs.CV, 25페이지)3
- 코드: https://github.com/NVlabs/Sana
- Models: (페이지 헤더에 항목은 있으나 disabled)
프로젝트 페이지는 hero bullet 4줄 + efficiency figure 1장 + 60초 14편·20초 18편·동일 첫 프레임 ABC 비교 8 scene으로 구성된 갤러리가 본체다. 디테일은 모두 논문에 있다.
네 가지 핵심 주장 — 페이지 hero bullet 그대로
페이지가 4줄로 압축해 둔 클레임은 다음과 같다.
1. Hybrid Linear Attention으로 1분 일관성
Hybrid linear attention pairs frame-wise Gated DeltaNet with periodic softmax to hold a coherent world for a full minute.
프레임 단위 Gated DeltaNet 위에 주기적(periodic) softmax 어텐션을 끼워 넣는 하이브리드 백본이다. 모든 레이어를 softmax로 두면 H100 단일 GPU에서 60초 지점에 OOM이 나지만, 선형 어텐션 백본에 softmax를 간헐 삽입하면 메모리와 지연이 시간 길이에 따라 완만히 스케일링한다.
2. 17B 2단계 long-video refiner
A dedicated 17B long-video refiner sharpens texture, motion, and late-window quality on top of the long-rollout backbone.
2.6B 장기 롤아웃 백본 위에 17B 규모의 long-video refiner를 따로 두어 텍스처·모션·후반부(late-window) 품질을 보정한다. 백본보다 refiner가 더 큰 비대칭 구성이 특징이다.
3. 6-DoF 카메라 제어용 이중 분기
A coarse global pose branch and a fine pixel-aligned geometric branch jointly follow metric camera paths with high fidelity.
coarse global pose 분기와 fine pixel-aligned geometric 분기를 함께 두어 미터 단위(metric) 카메라 경로를 추종한다.
4. 64 H100 학습, 단일 H100 추론
15 days on 64 H100s to train; a single H100 generates a one-minute 720p video at inference.
학습 64 H100 × 15일, 추론 단일 H100에서 1분 720p 생성. 모델 크기 2.6B로 비교적 작은 오픈소스라는 점을 명시한다.
논문이 채운 method 디테일
논문(arXiv:2605.15178)이 hero bullet 4줄로 압축한 부분을 실제로 어떻게 푸는지 정리하면 다음과 같다.
Periodic softmax 삽입 주기. 총 20개의 DiT 블록 중 5개({3, 7, 11, 15, 19})만 standard softmax attention이고, 나머지 15개는 frame-wise Gated DeltaNet(GDN)이다. 대략 매 4번째 블록이 softmax. 토큰 단위가 아니라 latent frame 한 장씩 스캔하여 상태 $S \in \mathbb{R}^{D \times D}$를 유지한다.
Spatial Explosion 안정화. 키에 $1/\sqrt{D \cdot S}$ 스케일을 적용해 transition 행렬의 spectral norm이 1을 넘지 않도록 강제한다. 이 스케일링이 없으면 step 1·16에서 NaN으로 학습이 무너진다(Fig.6 안정성 ablation).
Dual-Branch Camera Control.
- Coarse — latent-rate UCPE. ray-local basis로 4×4 homogeneous transform을 만들어 attention head의 geometric 채널엔 카메라 변환을, RoPE 채널엔 RoPE를 block-diagonal로 합성한다. 카메라 분기는 자체 QKV projection을 가지되 GDN gate는 본 분기와 공유하고, zero-init projection으로 main attention output에 더해진다.
- Fine — raw-frame Plücker mixing. VAE 1 stride당 8개 raw frame의 Plücker raymap $\rho = (\mathbf{d}, \mathbf{o} \times \mathbf{d}) \in \mathbb{R}^6$을 48채널 텐서로 묶어 zero-init 3D patch embedder + zero-init per-block projection으로 self-attention output 직후 가산한다.
17B refiner 학습 방식. LTX-2 base model에서 출발해 attention(Q/K/V/O)과 FFN에 rank-384 LoRA + FSDP2로 학습한다. distilled few-step refiner를 직접 finetune하면 불안정해서, multi-step non-distilled LTX-2에서 LoRA를 학습한 뒤 zero-shot으로 distilled few-step model에 merge한다. 추론은 LTX-2 stage-2 distilled sigmas로 3-step Euler만. truncated-σ flow matching($\sigma_{\text{start}} = 0.909375$)으로 stage-1 latent를 노이즈로 섞은 후 high-fidelity target에 매핑한다.
4단계 progressive training. Stage 1(GDN 적응, 5초, 30K step, ~2.75일) → Stage 2(Hybrid, 5초, 30K step, ~2일) → Stage 3(1분 + CamCtrl, 31K step, ~8일) → Stage 4(SFT chunk-causal, 1분, 10K step, ~2.5일). 총 15일/64 H100, AdamW + BF16 + grad clip 0.5.
213K clip 데이터 + 자체 메트릭 포즈 어노테이션. SpatialVID-HQ 158K, DL3DV 5.7K real + 14.9K GS-refined 60초 합성, OmniWorld 1.7K(GT depth), Sekai-Game 3.5K, Sekai Walking-HQ 9.8K, MiraData 19K로 합계 213K clip. 포즈 어노테이션은 VIPE + Pi3X(long-sequence depth) + MoGe-2(metric scale) 조합을 자체 파이프라인으로 구축했다.
Context-Parallel + Fused Triton. 961-frame(60초) 학습을 위해 latent를 P개 GPU로 시간축 sharding. GDN의 affine 성질을 활용해 각 shard가 transition composite와 input composite만 all-gather → exclusive prefix로 정확한 초기 상태를 복원한다. RMSNorm + ReLU + key scaling + UCPE/RoPE + GDN scan을 단일 Triton kernel로 융합해 1.5–2배 가속.
Efficiency Figure (프로젝트 페이지)
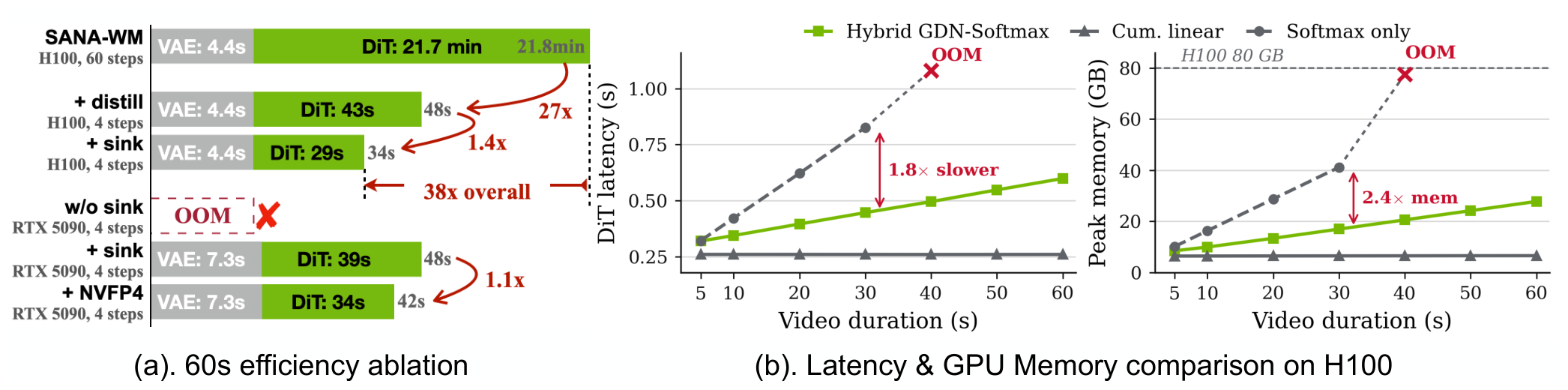
Efficiency ablation and scaling. (a) 60s single-GPU VAE/DiT latency by stage; bars are scaled for readability. (b) H100 latency and memory scaling: recurrent variants grow compactly, while all-softmax OOMs at 60s.
좌측은 60초 영상 단일 GPU 처리에서 60-step → 4-step distillation → attention-sink → NVFP4 양자화로 이어지는 가속 경로별 지연을 비교한다. 우측은 H100 기준 지연과 피크 메모리가 영상 길이에 따라 어떻게 증가하는지의 스케일링 곡선으로, recurrent 변종은 완만히 커지는데 all-softmax는 60초 지점에서 OOM이라는 것이 핵심 메시지다.
벤치마크 결과 — 1분 Hard/Simple-Trajectory (Tab. 2)
Hard-Trajectory split — RotErr(°) ↓ / CamMC ↓ / VBench Overall ↑ / Throughput(videos/hour, 8×H100):
- Infinite-World 1.3B 480p 1GPU: 41.31 / 2.84 / 79.51 / 5.9
- LingBot-World 14B+14B 480p 8GPU: 18.99 / 1.81 / 81.89 / 0.6
- HY-WorldPlay 8B 480p 8GPU: 35.46 / 2.64 / 70.46 / 1.1
- Matrix-Game 3.0 5B 720p 8GPU: 18.79 / 1.82 / 78.79 / 3.1
- SANA-WM 2.6B 720p 1GPU: 10.02 / 1.72 / 79.60 / 24.1
- SANA-WM + refiner 2.6B+17B 720p 1GPU: 8.34 / 1.44 / 81.89 / 22.0
Simple-Trajectory split에서는 refiner 적용 시 RotErr 4.50°·CamMC 1.41로 모든 baseline을 1위로 앞선다. revisit memory(revisit PSNR)에서는 refined 모델이 14.46/14.80 dB로 Simple 2위·Hard 1위, late-window 드리프트 지표 ΔIQ는 stage-1 AR의 3.79/3.09에서 1.17/0.31로 떨어진다(HY-WorldPlay의 23.59/25.88과 대조적). 8×H100 처리량 기준 LingBot-World 대비 36배, 가장 빠른 480p baseline(Infinite-World) 대비 3.7배.
Camera Conditioning Ablation (Tab. 4, OmniWorld)
FVD ↓ / RotErr(°) ↓ / CamMC ↓:
- No control: 348.93 / 16.93 / 0.4937
- Plücker only: 339.45 / 16.02 / 0.4742
- PRoPE: 326.70 / 6.29 / 0.2629
- UCPE only: 314.88 / 7.73 / 0.2453
- UCPE + Plücker (Ours): 320.80 / 6.21 / 0.2047
attention-level UCPE가 FVD를 가장 낮추고, dual-branch(UCPE + Plücker)가 pose 정확도를 최저로 끌어내린다. 둘 중 하나만 쓰는 것이 아니라 둘 다 필요하다는 점이 ablation의 메시지다.
데모 갤러리 구성 (프로젝트 페이지)
페이지의 절반 이상이 갤러리다.
- Hero reel 1편 —
hero_reel_v8.mp4. - Long-form (60s) 14편 —
long-1b,long-8a,long-9c,long-c06,long-c27,long-c29,long-8c,long-6a,long-gs10,long-on01,long-in10,long-on03,long-c10,long-2b. - Short-form (20s) 18편 —
short-6b~short-c13. - Same First Frame, Different Paths 8 scene × 3 variant = 24편 —
scene d4,c23,3b,c17,c18,8b,4b,2b. 같은 첫 프레임에서 카메라 궤적 A/B/C만 바꾼 카메라 제어 데모.
프롬프트가 공개된 영상은 1a~9c 계열 19개뿐이고, 모두 *1인칭 고정 시점 + 환경의 자율 운동(particles, fireflies, mist, swaying branches…)*이라는 동일한 템플릿을 따른다. 카메라가 움직이는 사례는 별도의 ABC 비교 섹션에 모아 둔 것이라, “월드 모델” 컨셉을 가장 깔끔하게 보여주는 구성이다.
한계와 향후 과제 (논문 §6)
- 여전히 scale-limited 모델
- explicit 3D scene memory가 부재 — 명시적 3D 메모리 모듈이 없다
- 동적 장면, 희귀 viewpoint, 더 긴 rollout에서 drift 가능
- 향후 과제: 모델·데이터 스케일 확장, 로봇 액션·포인트 트래킹 컨트롤 도입, persistent scene memory 강화, 실시간·스트리밍 refiner
- 사회적 영향: 시뮬레이션·embodied AI·로보틱스 접근성을 넓힘. 배포 시 provenance·모델 적용 범위·평가 세팅 문서화 권고
가장 흥미로운 지점
세 가지가 인상에 남았다.
백본(2.6B) < refiner(17B)의 비대칭. 보통 다단계 비디오 디퓨전에서 base가 크고 refiner가 작아지는 방향이 일반적인데, SANA-WM은 그 반대다. 1분 일관성은 작은 선형 어텐션 백본으로 만들고, 보는 맛은 별도의 큰 refiner에 분업시킨다. 백본은 메모리·지연이 영상 길이에 따라 완만히 늘어 long-context에 강하고, refiner는 짧은 윈도우 보정만 담당하므로 17B의 비용이 영상 길이에 비례하지 않는다.
non-distilled에서 LoRA 학습 → distilled에 zero-shot merge. distilled few-step refiner를 직접 finetune하면 불안정하다는 발견 자체가 흥미롭다. 우회로 — multi-step non-distilled LTX-2에서 rank-384 LoRA를 학습한 뒤 distilled few-step 모델에 그대로 머지하면 추론은 3-step만 — 가 실용적이다. 큰 모델의 학습 비용을 LoRA로 떨어뜨리고, 추론은 distilled의 적은 step을 쓰는 학습-추론 분리가 깔끔하다.
20개 블록 중 정확히 5개 위치에 softmax. {3, 7, 11, 15, 19}라는 위치 선택이 매 4번째라는 단순 규칙으로 충분하다는 점이 좋다. 더 정교한 학습형 게이팅이 아니라 인덱스를 고정해 두는 정도로 충분한 attention–GDN 혼합이 가능하다는 신호다.
출처
저자: Haoyi Zhu, Haozhe Liu, Yuyang Zhao, Tian Ye, Junsong Chen, Jincheng Yu, Tong He, Song Han, Enze Xie (NVIDIA Labs 외)
프로젝트 페이지: https://nvlabs.github.io/Sana/WM/ ↩︎
논문: https://arxiv.org/abs/2605.15178 (2026-05-14, cs.CV, 25페이지) ↩︎