3줄 요약
- Pixelle-Video는 알리바바 AIDC-AI 팀이 공개한 Apache-2.0 라이선스의 숏비디오 자동 생성 엔진이다. 주제 한 줄을 받으면 문안 작성 → AI 이미지·영상 생성 → TTS 내레이션 → BGM → 합성까지 한 번에 처리한다.
- 단순 결합이 아니다. 코드를 들여다보면 일곱 군데에 품질 가드가 들어가 있다. 그중 가장 실용적인 것은 TTS 오디오 길이를 비디오 생성의 입력으로 흘려보내 동기화를 사후 편집이 아니라 입력 단계에서 해결하는 설계, 그리고 내레이션 LLM에게 출력 직후 자기 검증을 시켜 정형 문장을 차단하는 프롬프트다.
- 다만 캐릭터 외양 일관성, 컷 간 시각적 연속성, 결과물 자동 평가·재생성 같은 깊은 품질 보장 장치는 비어 있다. 한 컷씩 따로 노는 결과가 나오기 쉬운 구조다.
Pixelle-Video는 무엇인가
ComfyUI를 백엔드로 두고 텍스트 한 줄을 숏비디오로 변환하는 엔진이다. RunningHub 클라우드와 자체 호스트(ComfyUI 로컬) 두 모드를 모두 지원하며, FLUX·WAN 2.1·Edge-TTS·Index-TTS·ChatTTS·Nano Banana 등 원자 능력을 조합해 한 편의 영상을 만든다.
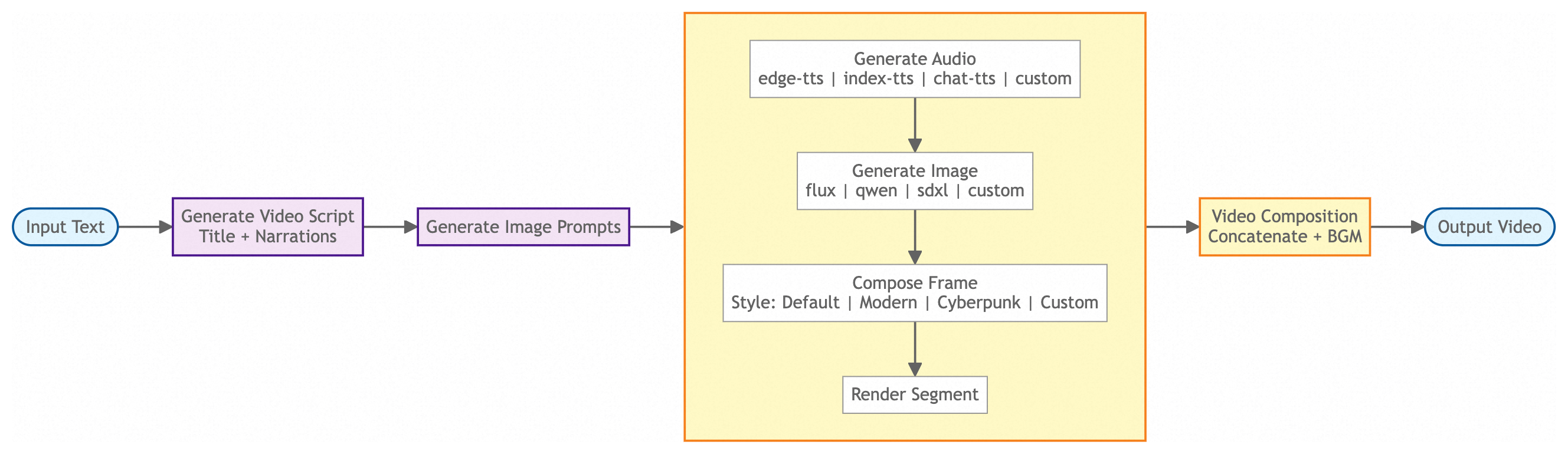
리포의 README는 “주제만 입력하면 끝"이라는 가벼운 카피로 시작한다. 그런데 자동화의 가장 어려운 부분은 각 단계의 출력이 다음 단계의 입력으로 깨끗하게 맞물리는가다. 코드는 어디서 이 갈등을 해결하고 있을까. 다음 일곱 가지를 찾아냈다.
챙긴 품질 아이디어 일곱
1. TTS-driven video duration — 동기화를 입력 단계에서 해결
pixelle_video/services/frame_processor.py 헤더에는 이런 메모가 적혀 있다.1
“Audio duration from TTS is passed to video generation workflows to ensure perfect sync between audio and video (no padding, no trimming needed)”
즉, TTS로 합성한 오디오 길이를 먼저 측정한 뒤 그 길이를 그대로 비디오 생성 워크플로우의 파라미터로 흘려보낸다는 뜻이다. 영상이 다 만들어진 다음 길이를 맞추려고 자르거나 늘리는 사후 편집을 하지 않는다. 단순하지만 영리하다 — 자동 영상 생성에서 가장 흔히 어긋나는 지점이 바로 “오디오 5.3초인데 영상은 6초"라는 어긋남이기 때문이다. 입력 시점에 한 번 맞춰두면 그다음은 깨질 자리가 없다.
2. Template Method Pattern — 워크플로우 정본화
모든 파이프라인은 LinearVideoPipeline 추상 클래스를 상속한다. 8단계 라이프사이클이 그 안에 정의되어 있다.
setup_environment → generate_content → determine_title → plan_visuals
→ initialize_storyboard → produce_assets → post_production → finalize
Standard 파이프라인(주제로 영상 생성), AssetBased 파이프라인(사용자 에셋으로 영상 생성) 모두 이 8단계를 골격으로 공유하며, 각자 필요한 단계만 override한다. 단계 누락이나 순서 혼란이 구조적으로 불가능해진다. 원자 능력은 자유롭게 교체하되 워크플로우의 형태는 흔들리지 않게 한다는 선택이다.
3. Narration 프롬프트의 자가검증 — “AI 티 나는 정형 문장” 차단
prompts/topic_narration.py의 가장 흥미로운 부분.
“any word (such as ‘sometimes’, ‘actually’, ‘have you ever’) appears more than once as an opening, it is a failed creation”
“After writing, self-check the openings of all storyboards to ensure no repeated use of the same word or phrase as an opening”
풀어 말하면 *“각 컷의 첫머리에 같은 단어를 두 번 이상 쓰면 그 결과물은 실패한 것으로 간주한다. 다 쓴 다음 너 스스로 컷들의 첫머리를 다시 점검하여 같은 단어·구절이 반복되지 않는지 확인하라”*는 지시다. 숏폼 자동 생성이 가장 자주 무너지는 지점이 바로 “그런데 말이죠”, “사실은 말이에요"가 컷마다 반복되며 AI 티가 나는 순간이다. 사람 손이 닿지 않는 자동 파이프라인에서 이걸 잡으려면 결국 LLM 자신에게 검증을 시키는 수밖에 없는데, Pixelle-Video는 검증 기준을 오프닝 단어의 중복 여부라는 매우 구체적인 형태로 좁혀 명시한다. 정답을 보장하지는 못해도 의도는 분명하다.
4. 스토리보드 응집성 제약
같은 프롬프트에는 이런 지시도 있다.
“Each storyboard should sound like the same person continuously sharing viewpoints”
즉 *“각 컷이 마치 같은 사람이 이어서 한 호흡으로 말하는 것처럼 들려야 한다”*는 지시다. 거기에 더해 narrative arc — 공감 → 관점 → 심층 → 영감(resonate → propose viewpoint → in-depth explanation → provide inspiration) — 네 단계가 명시되어 있어, 컷들이 단순한 나열이 아니라 하나의 호흡으로 묶이도록 유도한다.
5. Narration ↔ Image prompt 1:1 매칭 강제
prompts/image_generation.py는 내레이션 N개에 대해 정확히 N개의 이미지 프롬프트를 생성해야 한다는 제약을 본문에 세 번 반복한다.
“The output image_prompts array must contain exactly {narrations_count} elements, corresponding one-to-one with the input narrations array”
추가로 이미지 프롬프트는 영어로 작성하도록 강제한다 — 이미지 모델들이 영어에 가장 잘 반응하기 때문이다. 길이는 50–100 단어를 권장한다. LLM의 JSON 출력이 깨지거나 개수가 어긋나면 파이프라인 전체가 멈추므로, 가장 깨지기 쉬운 인터페이스에 프롬프트 차원의 안전장치를 둔 셈이다.
6. Asset-based 모드의 이미지 역분석
사용자가 자신의 사진이나 영상을 업로드해 영상을 만드는 모드에서, Pixelle-Video는 곧장 스크립트를 작성하지 않는다. 먼저 Florence-2 같은 비전 모델로 이미지를 텍스트로 환원한 뒤(services/image_analysis.py), 그 설명을 기반으로 내레이션을 작성한다. 풀어 말하면 “이미지에 없는 내용을 말하는 내레이션"이 나오지 않도록, 모델이 본 것을 먼저 글로 정리하고 그 글에서 출발하게 한다는 발상이다. 영상과 음성이 따로 노는 가장 흔한 실패 패턴을 입력 시점에 차단한다.
7. 스타일 프리셋으로 비주얼 톤 통일
IMAGE_STYLE_PRESETS = {
"stick_figure": "stick figure style sketch, black and white lines, ...",
"minimal": "minimalist abstract art, geometric shapes, ...",
"concept": "conceptual visual metaphors, symbolic elements, ...",
}
세 종류 중 하나의 스타일 접미사가 모든 컷의 이미지 프롬프트에 동일하게 적용된다. 컷마다 그림체가 들쭉날쭉해지는 것을 가장 가벼운 비용으로 막는 장치다.
비어 있는 곳
코드를 훑으면서 없는 것도 분명하게 보였다. 다음은 일반적으로 “AI 영상 품질 보장"이라 부르는 항목들인데, Pixelle-Video에는 들어 있지 않다.
- 결과물 자동 평가·스코어링·LLM-as-judge — 한 번 만든 영상은 그대로 송출된다. 잘 나왔는지 따로 채점하지 않는다.
- 자동 재생성·재시도 정책 — 한 컷이 망가져도 다음 컷으로 넘어간다. “이 컷은 품질 미달이니 다시 만든다"는 분기가 없다.
- 캐릭터 외양 일관성 — IP-Adapter, character LoRA, seed 재사용, reference image lock 같은 장치가 보이지 않는다. 컷 1의 주인공과 컷 2의 주인공이 같은 인물처럼 보일 보장이 없다.
- 컷 간 시각적 연속성 — 스타일 프리셋이 톤을 어느 정도 묶어주긴 하지만, 그 이상의 장면 전환 일관성 보장은 없다.
가장 흥미로운 지점
설계자가 어디에 칼을 댈지를 고른 방식이 흥미롭다.
자동 영상 생성에서 깨지기 쉬운 지점은 크게 두 갈래다. 하나는 모델 단위 품질(이미지가 예쁜가, 목소리가 자연스러운가)이고, 다른 하나는 연결부 품질(오디오와 영상이 맞는가, 컷이 연속되는가, 같은 톤인가)이다. Pixelle-Video는 첫째 갈래에는 거의 손을 대지 않는다 — 그건 ComfyUI 뒤의 FLUX·WAN 2.1·Edge-TTS가 알아서 할 일로 둔다. 대신 둘째 갈래, 연결부 쪽에 가벼운 가드를 여러 개 둔다. TTS 길이를 비디오에 흘려보내고, 내레이션 프롬프트에 자가검증을 강제하고, 이미지 프롬프트 개수를 잠그고, 스타일 접미사를 공유한다.
이건 훌륭한 품질 평가 시스템을 만든 것이 아니라 흔히 깨지는 부분만 골라 사전에 봉합한 방식이다. 평가·재생성·재시도 같은 사후 검증 루프 대신 입력과 인터페이스에 제약을 거는 쪽을 택했다. 가볍지만 솔직한 선택이다. 다만 그 가벼움의 대가가 캐릭터·시각 연속성의 부재로 드러나고, 그건 숏폼 영상에서 가장 티 나는 결함이기도 하다.
“전자동 엔진"이라는 카피를 그대로 받아들이기보다, 어디까지 자동이고 어디서 사람 손이 필요한가를 코드 단위로 짚어두면 도구를 잘 다루는 데 도움이 된다.
출처
- 발신자: 알리바바 AIDC-AI 팀
- 라이선스: Apache-2.0
- 원문: https://github.com/AIDC-AI/Pixelle-Video
본 다이제스트가 인용한 핵심 파일:
pixelle_video/services/frame_processor.py,pixelle_video/pipelines/linear.py,pixelle_video/prompts/topic_narration.py,pixelle_video/prompts/image_generation.py,pixelle_video/services/image_analysis.py↩︎