
3줄 요약
- Hugging Face의 David Louapre·Joel Niklaus·Lewis Tunstall 팀이 이론물리학 연구를 자동화하기 위한 멀티에이전트 비계 시스템
physics-intern을 공개했다. - 9개 전문 에이전트(설문조사·기획·오케스트레이터·연구자·계산자·검토자·시니어 비평가·중재자·포맷터)가 적대적 검토와 영속 ResearchState를 사이에 두고 협업한다.
- 연구 수준의 이론물리학 벤치마크 CritPt에서 Gemini 3.1 Pro 기반 physics-intern이 31.4%를 기록해 GPT 5.5 Pro(30.6%)를 추월했다 — 구조가 규모를 대신할 수 있음을 보였다.1
1. CritPt 벤치마크
CritPt는 양자장론·일반 상대성·통계역학·양자정보 등을 아우르는 70개의 연구 수준 이론물리학 문제 모음이다. 각 문제는 SymPy 식으로 표현되는 명확한 답을 갖는다.
- 2026년 5월 기준 프론티어 모델 최고 점수는 GPT 5.5 Pro의 30.6% — 최대 reasoning 모드 기준이다.
- 같은 모델들이 코딩 벤치마크에서는 70~90%, Humanity’s Last Exam에서도 25~45%를 기록한다.
- 즉 CritPt는 현재 LLM에 가장 가혹한 평가 중 하나다.
이론물리학이 코딩이나 수학보다 LLM에 더 어려운 이유는 신뢰할 만한 피드백 신호가 없기 때문이다. 컴파일러도, 린터도, 형식적 증명 시스템(Lean)도 적용하기 어렵다. 부호 하나, 경계 조건 하나만 빠뜨려도 유도 전체가 무너진다.
2. 양자 오류 검출 퍼즐 — 원샷 추론이 무너지는 지점
CritPt에는 공개 해답이 있는 단 하나의 예제 문제가 있다 — 양자 오류 검출 문제다.

문제 요지. 4개의 물리 큐비트가 2개의 논리 큐비트를 인코딩하는 회로에서, 노이즈 확률 $p$에 대해 fidelity $F(p)$를 구하라. 풀이는 노이즈 게이트 전반의 모든 오류 조합(약 100만 시나리오)을 추적하고, 검출되는 것·통과하는 것·해롭지 않은 것·해로운 것을 분류하는 거대한 부기 작업이다.
정답은 다음과 같은 분자·분모 모두 $p^5$까지의 유리함수 형태로, 선두 보정항이 $O(p^2)$(1차항 없음)이라는 점이 핵심이다 — 이것이 “fault tolerant” 구성임을 보여주는 sanity check다.
Gemini 3 Flash를 원샷으로 40번 돌린 결과: 성공은 단 2번(5%). 대부분 같은 오답 $F(p) = 1$을 내놓았다. 노이즈가 있는 회로가 완벽한 fidelity를 가질 수 없다는 자명한 모순도 잡아내지 못한다. 그 외 오답들도 1차항이 살아있어 fault tolerance를 위반했다.
저자들의 진단:
모델은 첫 직관(“단일 게이트 오류는 모두 검출 가능하다 → 따라서 fidelity는 1”)을 붙들고 결코 되돌아보지 않는다. 그러나 문제 자체는 분할정복에 완벽히 들어맞는다. 외로운 추론자에게 결여된 것은 단계마다의 견제와 균형이다.
물리학자가 어려운 문제를 풀 때 혼자 일하지 않는다는 것이 핵심 관찰이다. PI가 전략을 세우고, 학생이 계산하고, 동료가 검토하고, 심사위원이 가정을 흔들고, 에디터가 결정을 뒤집을 수 있다. 이 생태계를 단일 자율 에이전트 내부에 옮겨 넣을 수는 없는가? — 이것이 physics-intern의 출발점이다.
3. physics-intern 프레임워크
세 가지 설계 원칙 위에 서 있다.
- 전문화(Specialization): 각 LLM 호출은 단 하나의 제한된 과제만 수행하며, 그에 필요한 컨텍스트만 받는다. 전략을 짜는 에이전트는 raw 계산을 보지 않고, 결과를 검토하는 에이전트는 이미 확정된 결과의 상세 추론을 보지 않는다.
- 견제와 균형(Checks and balances): 모든 중간 결과는 적대적 검토를 거친다. 게다가 주기적으로 “시니어 비평가"가 전체 연구 방향이 타당한지 감사한다. 확정된 결과(ER)에 대한 비판은 독립적인 중재자(adjudicator)가 평가한다 — 항상 second opinion이 있다.
- 매 호출 신선한 컨텍스트(Fresh context every call): 에이전트 사이에 대화 이력이 넘어가지 않는다. 대신
ResearchState가 영속한다 — 축적된 결과·증거·가설·비판의 구조화된 메모리. 매 호출마다 거기서 필요한 컨텍스트를 새로 조립한다. 각 실행은 git 리포로 추적되어 모든 반복이 재현·감사·재개 가능하다.
9개 에이전트 역할
| 에이전트 | 역할 |
|---|---|
| Surveyor | 관련 기법·핵심 통찰·알려진 함정을 매핑. 메인 루프 시작 전 1회 실행. |
| Planner | 연구 전략과 답이 만족해야 할 sanity check 목록을 수립. 비판이 요구하면 전략을 수정. |
| Orchestrator | 연구 상태를 읽고 다음 단계 결정: 연구 질문 생성, 워커 디스패치, 가설 승격. |
| Researcher | 분석적 추론과 유도를 수행해 증거를 만든다. |
| Computer | 샌드박스에서 Python 코드를 작성·실행해 수치·기호 증거를 만든다. |
| Reviewer | 후보 결과를 적대적으로 검사 — 판정은 VERIFIED·REFUTED·INCONCLUSIVE. |
| Senior Critic | 연구 상태 전반의 정합성과 전략의 진부함을 주기적으로 감사. |
| Adjudicator | 확정된 결과에 대한 비판을 독립적으로 중재. |
| Formatter | 종료 선언 시 최종 답을 생성. |
청구권의 생애주기
Research Question (RQ)
→ 증거(분석/계산)
→ Working Hypothesis (WH)
→ 검토(reviewer)
→ Established Result (ER)
언제든 시니어 비평가가 ER에 도전할 수 있고, 중재자가 ER을 강등시킬 수 있고, 기획자가 전략을 수정할 수 있다. 청구권은 앞으로만 가는 게 아니라 뒤로도 갈 수 있다.
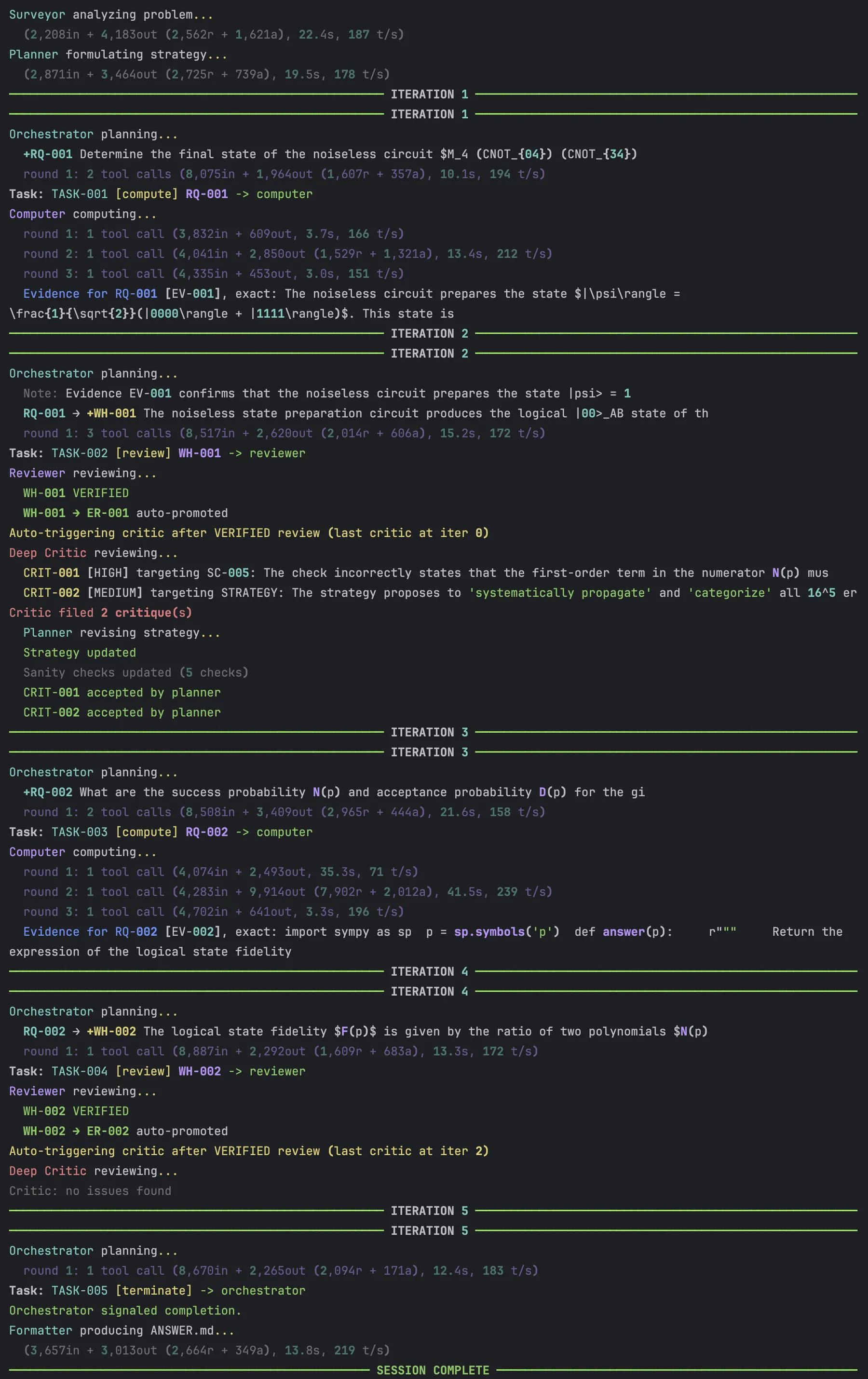
4. 예제 퍼즐 풀이 — 5%에서 100%로
같은 양자 오류 검출 문제에 Gemini 3 Flash + physics-intern을 20회 실행한 결과 모두 정답에 도달했다(100%). 그러나 경로는 매번 달랐다.
세 가지 실행 예시:
- 깔끔한 실행(3 iterations): 단일 RQ로 전체 오류 구성을 enumerate, 검토 통과, 비판 없음. 10번의 LLM 호출, 약 160K 토큰.
- 오경보(3 iterations): ER이 확정된 후 시니어 비평가가 잘못된 비판을 제기 — “F(15/16)이 6.78이라 fidelity 상한을 넘는다.” 중재자가 직접 $p = 15/16$을 대입해보니 약 0.25였다. 비평가 본인의 계산 오류였고 중재자가 기각했다.
- 철저한 조사(5 iterations): 기획자가 문제를 두 개의 RQ로 쪼개 각각 검증 — 먼저 stabilizer tableau로 무노이즈 회로의 목표 상태를 확인하고, 그 다음 두 가지 독립적 방법(symplectic propagation, distribution tracking)으로 fidelity를 교차 검증.
다른 접근들과의 비교 (예제 문제 pass@1)
| 시스템 | 성공률 |
|---|---|
| Single call (Gemini 3 Flash 원샷) | 5% |
| Recursive Self-Aggregation (RSA, 약 20배 컴퓨트) | 35% |
| AutoPhysicist (단일 manager + sub-agent) | 85% |
| physics-intern | 100% |
RSA가 5% → 35%로 의미 있게 끌어올렸지만, 첫 시도들이 같은 함정($F(p)=1$)에 빠지면 토너먼트는 함정에서 빠져나오지 못한다. AutoPhysicist는 일반화된 매니저로 85%까지 갔지만, 명시적인 역할 분리와 컨텍스트 격리가 마지막 15%를 만든다.
5. CritPt 전체 70문제 — 새로운 SOTA
| 설정 | 점수 |
|---|---|
| Gemini 3 Flash | 8.6% |
| Gemini 3 Flash + physics-intern | 15.7% (+82% 상대) |
| Kimi K2.6 (오픈웨이트) | 8.0% |
| Kimi K2.6 + physics-intern | 21.4% (+168% 상대) |
| Gemini 3.1 Pro | 17.7% |
| Gemini 3.1 Pro + physics-intern | 31.4% (+77% 상대) |
핵심 결과:
- 31.4%의 Gemini 3.1 Pro + physics-intern이 CritPt 리더보드 신기록이다 — 이전 1위 GPT 5.5 Pro(30.6%, 최대 reasoning)를 추월. 그것도 자체 점수가 17.7%인 모델로.2
- Gemini 3 DeepThink는 문제당 약 $10의 reasoning 컴퓨트를 쓰고도 25.7%에 그쳤다. 같은 컴퓨트를 비구조화된 추론에 쏟는 것보다 전용·구조화된 비계가 더 많이 뽑아낸다.
- 가장 극적인 상승은 Kimi K2.6의 8.0% → 21.4%(약 3배). 원샷 Kimi는 65K 출력 토큰 한도에 56/70 문제가 잘렸지만, 멀티에이전트 루프가 추론을 여러 호출로 분산시켜 구조적 한계를 우회했다.
비용 분배
- 평균 약 600K 토큰/문제(입출력 약 균등), 문제당 113K~3.9M, 반복 3~40회(중앙값 8회).
- 검토·비판에 쓴 출력 토큰(reviewer + senior critic + adjudicator ≈ 37%)이 실제 일을 하는 토큰(computer + researcher ≈ 36%)과 거의 같다.
- 이 정도로 어려운 벤치마크에서는 답을 만드는 만큼이나 답을 검증하는 데 컴퓨트가 든다.
시니어 비평가 통계
- 70문제에 걸쳐 총 234건의 비판(중앙값 2, 최대 15).
- 그중 약 15%만이 특정 ER을 향했고, 중재자는 그중 60%를 인정해 ER을 강등시켰다(40%는 기각).
- 나머지 85%는 전략·조정·sanity check를 겨냥했고 기획자가 처리했다.
6. 인간-루프 협업의 자연스러움
저자들은 정량적 우위 외에 **legibility(가독성)**를 강조한다. RSA는 독립적 LLM 호출을 병렬로 돌리고 토너먼트로 추리는 방식이라, 사람이 자연스럽게 들어갈 진입점이 없고 영속 상태도 없다. 반면 physics-intern은 실제 연구 흐름을 모사하므로 — 기획자·연구자·검토자·비평가 — 언제든 인간 물리학자가 들어와 가설을 코멘트하거나 전략을 재조정하거나 놓친 접근을 힌트로 줄 수 있다.
가장 흥미로운 지점
이 글에서 가장 충격적이었던 한 줄은 결론에 있다.
On a benchmark this hard, scaffolding can substitute for scale.
자체 점수 17.7%의 Gemini 3.1 Pro가, 같은 모델에 9개 역할의 멀티에이전트 비계를 입혔다는 이유만으로, 최대 reasoning 모드의 GPT 5.5 Pro를 추월했다. 더 큰 모델을 만드는 길과 더 좋은 추론 구조를 만드는 길이 동등한 자산이 될 수 있음을 한 줄로 보여준다.
그리고 그 비계의 핵심이 **“검증에 쓴 컴퓨트가 생성에 쓴 컴퓨트와 거의 같다(37% vs 36%)”**는 통계라는 점도 인상 깊다. 우리가 LLM 활용을 설계할 때 “답을 더 잘 만드는 법"에 압도적으로 무게를 두는데, 이 결과는 정반대를 가리킨다 — 어려운 문제일수록 답을 만드는 만큼 답을 의심하는 일이 일이다.
마지막으로 RSA(토너먼트)가 5%에서 35%까지 끌어올린 뒤 그 이상 가지 못한 분석이 시사하는 바도 크다. 초기 시도들이 같은 함정에 빠지면, 컴퓨트를 더 쏟아도 다양성이 그 함정 밖으로 모델을 끌어내지 못한다. 단순히 많이 시도하는 것과, 다른 역할의 검증자가 다른 각도에서 들여다보는 것은 종류가 다른 작업이다.
출처
- 저자: David Louapre, Joel Niklaus, Lewis Tunstall (Hugging Face)
- 발행일: 2026-04-12
- 원문: https://huggingface.co/spaces/huggingface/physics-intern
CritPt 벤치마크: Zhu et al., 2025, arXiv:2509.26574 ↩︎
CritPt 리더보드: https://artificialanalysis.ai/evaluations/critpt ↩︎