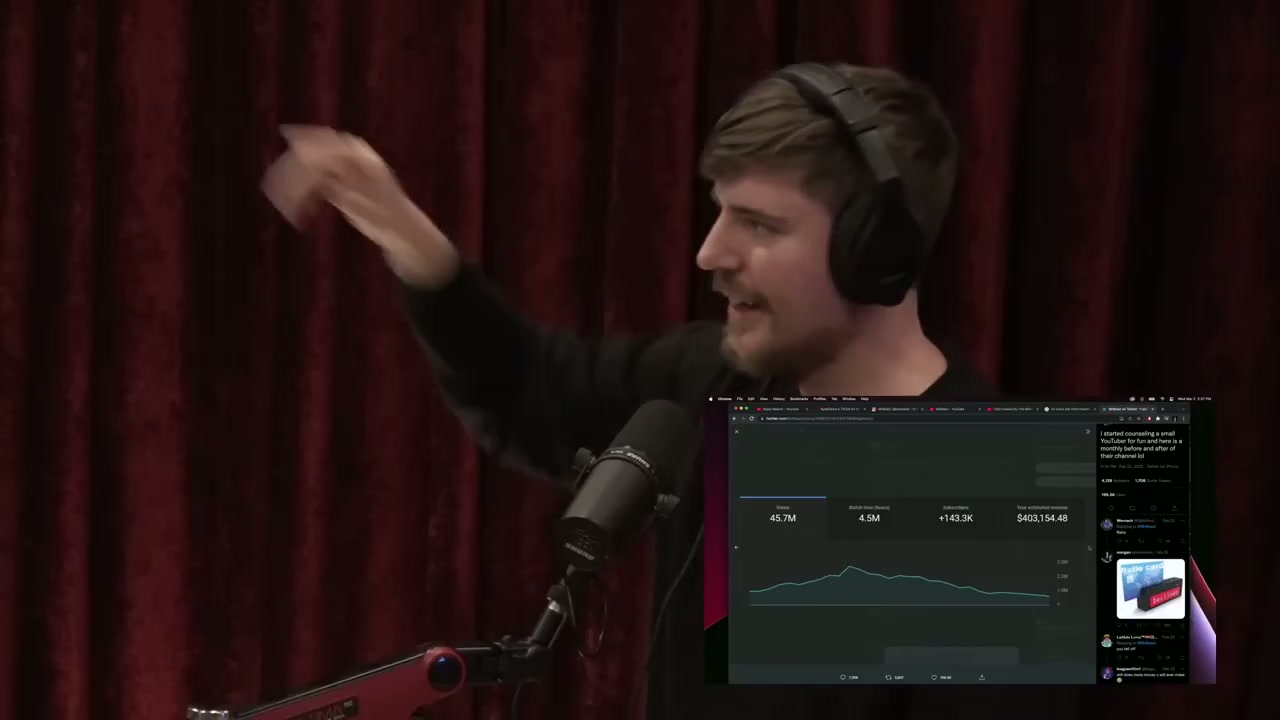
MrBeast — 10% 더 좋은 영상이 4배 뷰를 만든다
Joe Rogan Experience #1788에서 MrBeast가 멘토링한 유튜버 한 명을 4M 뷰·월 24,000달러에서 45M 뷰·월 400,000달러까지 끌어올린 사례를 들며, 10% 더 좋은 영상이 10% 더 많은 뷰가 아니라 4배의 뷰를 가져온다는 비선형 보상 법칙을 정리한 클립.
Joe Rogan Experience #1788에서 MrBeast가 멘토링한 유튜버 한 명을 4M 뷰·월 24,000달러에서 45M 뷰·월 400,000달러까지 끌어올린 사례를 들며, 10% 더 좋은 영상이 10% 더 많은 뷰가 아니라 4배의 뷰를 가져온다는 비선형 보상 법칙을 정리한 클립.
Google Cloud의 Data Cloud 팀이 LLM-wiki 패턴을 휴대 가능한 상호운용 포맷으로 정형화한 Open Knowledge Format(OKF) v0.1을 공개했다. YAML frontmatter가 붙은 마크다운 파일 디렉토리로 지식을 표현하며, 벤더·플랫폼·에이전트 프레임워크에 종속되지 않는 형식만으로 에이전트 간 컨텍스트 공유를 가능하게 한다.

미국 정부가 국가안보 수출 통제로 Anthropic의 Fable 5와 Mythos 5 차단을 지시하자, theahura는 트럼프 행정부의 부패한 정치 동기와 OpenAI 측 유착, 금요일 오후 발표 패턴 등 정당한 규제 신호를 오염시키는 큰 그림자를 짚는다.

Anthropic 리서치 펠로우 Vivek이 X 아티클로 정리한 리서치 메타 가이드. 리서치를 잘하는 능력은 8개의 작은 스킬 스택이며 모두 의도적으로 훈련할 수 있다는 주장.

Spotify가 사내 AI 코딩 도구 채택과 백그라운드 에이전트 Honk를 공개한 자료. 수년 전 만든 Backstage·Fleet Management·Soundcheck가 에이전트의 가드레일이 됐고, 병목이 코딩에서 의사결정으로 이동했다는 것이 골자다.

Anthropic이 Fable을 출시한 직후 zero_goliath가 쓴 짧은 에세이. 컴퓨트가 아니라 데이터 파이프라인이 진짜 병목이며, RLVR이 한계에 닿으면 AI가 운영하는 실제 회사들의 손익이 다음 보상 신호가 된다고 본다.
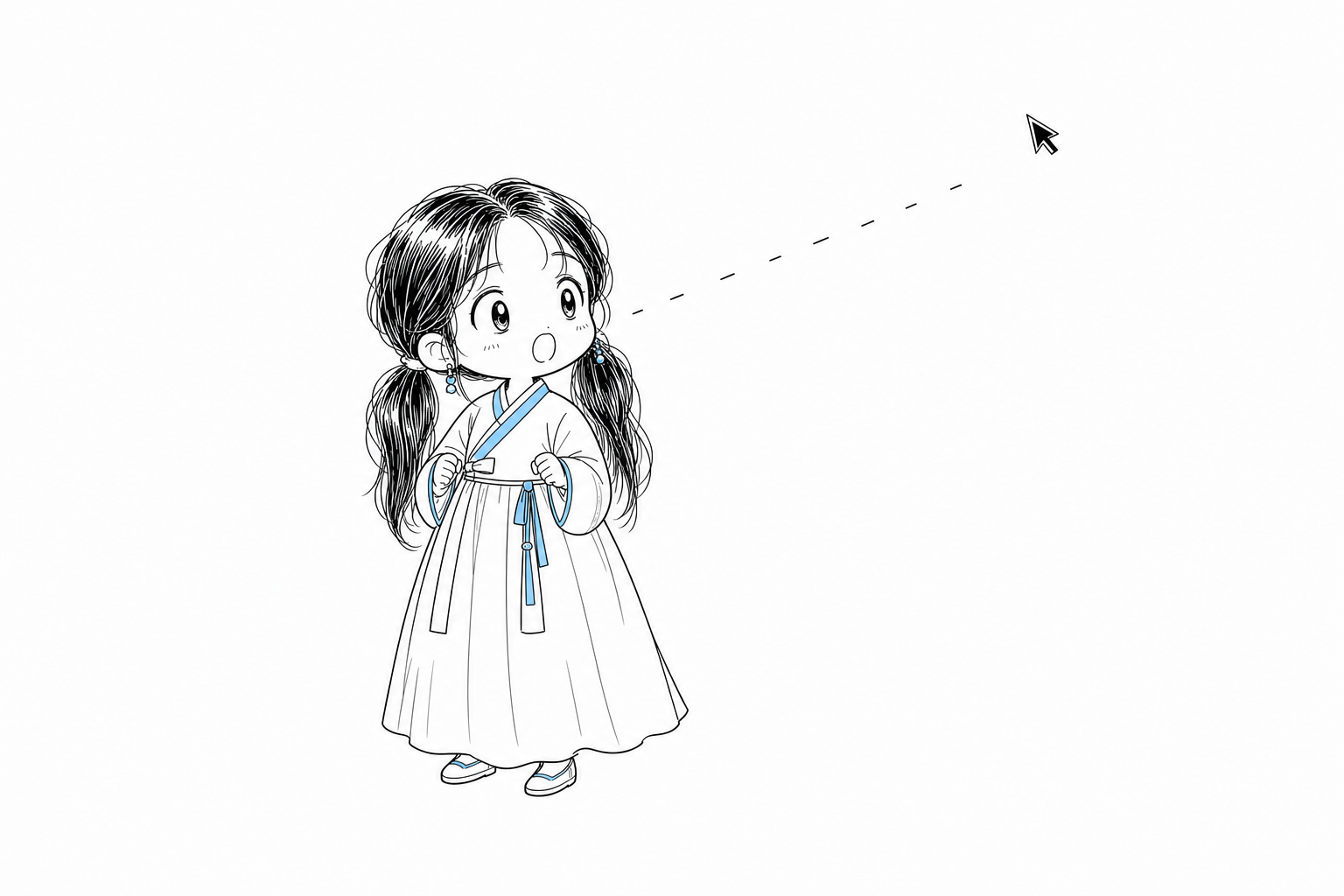
마우스를 따라 25방향으로 돌아보고 음성에 맞춰 입을 움직이는, 트마리용 브라우저 아바타. 150장의 프레임을 갈아끼우는 단순한 구조와 그 뒤의 캐릭터 시트 슬라이싱 파이프라인을 정리하고, 같은 구조를 치비 서소영으로 직접 옮겨 봤다.
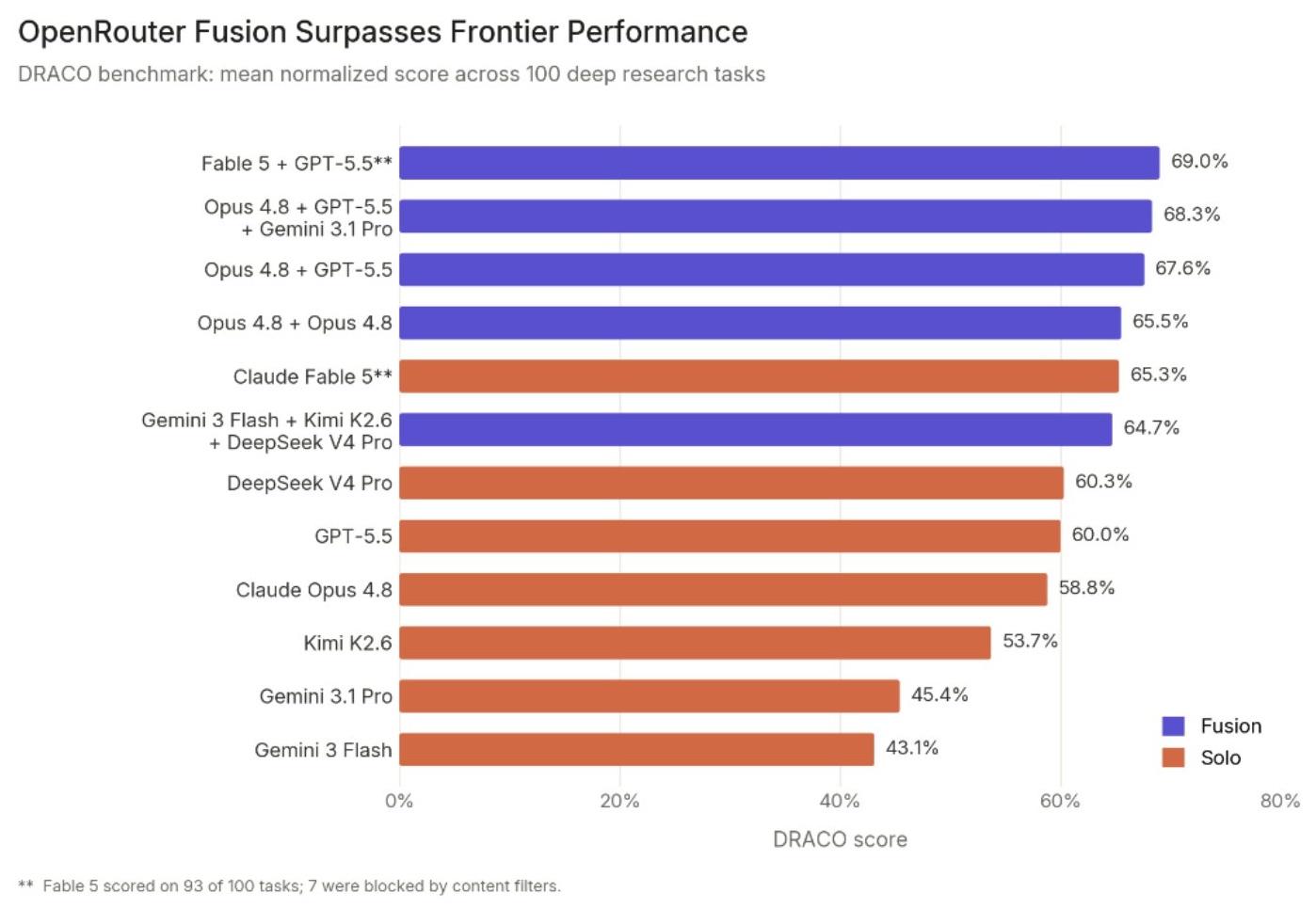
Andrew Trask는 더 큰 단일 모델이 AI 한계를 독점하리라는 통념이 끝났다고 선언한다. 작은 모델들의 가중 앙상블이 정확도·속도·비용에서 이미 단일 프런티어 모델을 추월하기 시작했고, AI의 미래는 회사 단위가 아닌 세계 단위의 ’network-source AI’다.

Demis Hassabis가 2026년 6월 3일 Stanford GSB에서 Jonathan Levin 총장과 진행한 57분짜리 대담. AGI가 2030년 ±1년 안에 온다는 전망, ‘우리는 특이점의 산기슭에 있다’는 발언, 회사 간·국가 간 이중 race dynamic이 만든 prisoner’s dilemma, post-scarcity 시대를 위한 새로운 경제학의 필요성을 두루 논한다.
Omnara의 Ishaan Sehgal이 쓴 X 아티클. 에이전트의 정체는 모델도 런타임도 아닌 이벤트 로그이며, 로그를 1급 시민으로 다루면 신뢰성과 확장성과 포크와 마이그레이션이 구조적으로 따라온다고 주장한다.