
DeepSWE: 오염 없는 장기 호라이즌 코딩 에이전트 벤치마크
Datacurve가 처음부터 새로 쓴 오염 없는 과제로 프론티어 코딩 에이전트를 평가하니, SWE-Bench류에서 근접하던 모델들이 넓게 갈라졌다. gpt-5.5 70% vs claude-sonnet-4.6 32%.
Datacurve가 처음부터 새로 쓴 오염 없는 과제로 프론티어 코딩 에이전트를 평가하니, SWE-Bench류에서 근접하던 모델들이 넓게 갈라졌다. gpt-5.5 70% vs claude-sonnet-4.6 32%.
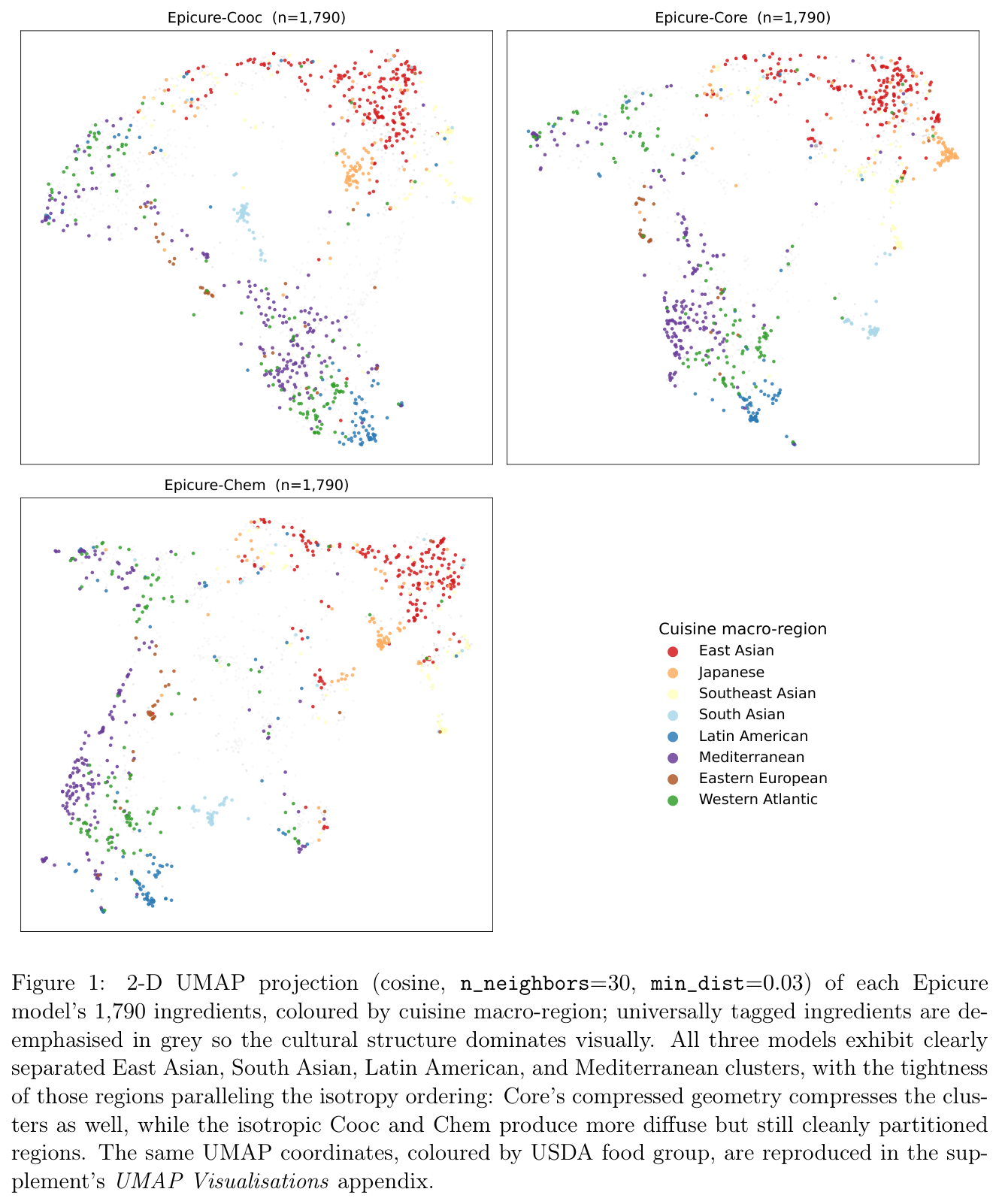
FlavorGraph 후속작. 414만 다국어 레시피로 학습한 세 자매 식재료 임베딩(Cooc·Core·Chem)을 통해 ‘화학 vs 레시피-맥락’을 조정 가능한 설계 축으로 만들고, 페어링과 SLERP 회전이라는 두 연산자로 임베딩 공간을 항해한다.

AI MV 크리에이터 tapehead.lab이 신곡 「free will」 MV의 실사×애니메이션 합성 워크플로우를 공개했다. 핵심은 합성과 동영상 생성을 따로 하던 두 갈래가 Seedance2.0에서 하나로 합쳐졌다는 것 — 합성하면서 생성한다. 캐릭터 시트 한 장과 프롬프트만으로 드론 샷급 카메라워크까지 캐릭터가 붕괴 없이 버틴다.

구글이 검색을 AI 에이전트로 전면 개편하자 사용자 반발이 일었고, ‘AI 없는 검색’을 내건 DuckDuckGo의 미국 앱 설치가 6일 연속 늘어 5월 25일 주간 30.5% 증가로 정점을 찍었다.
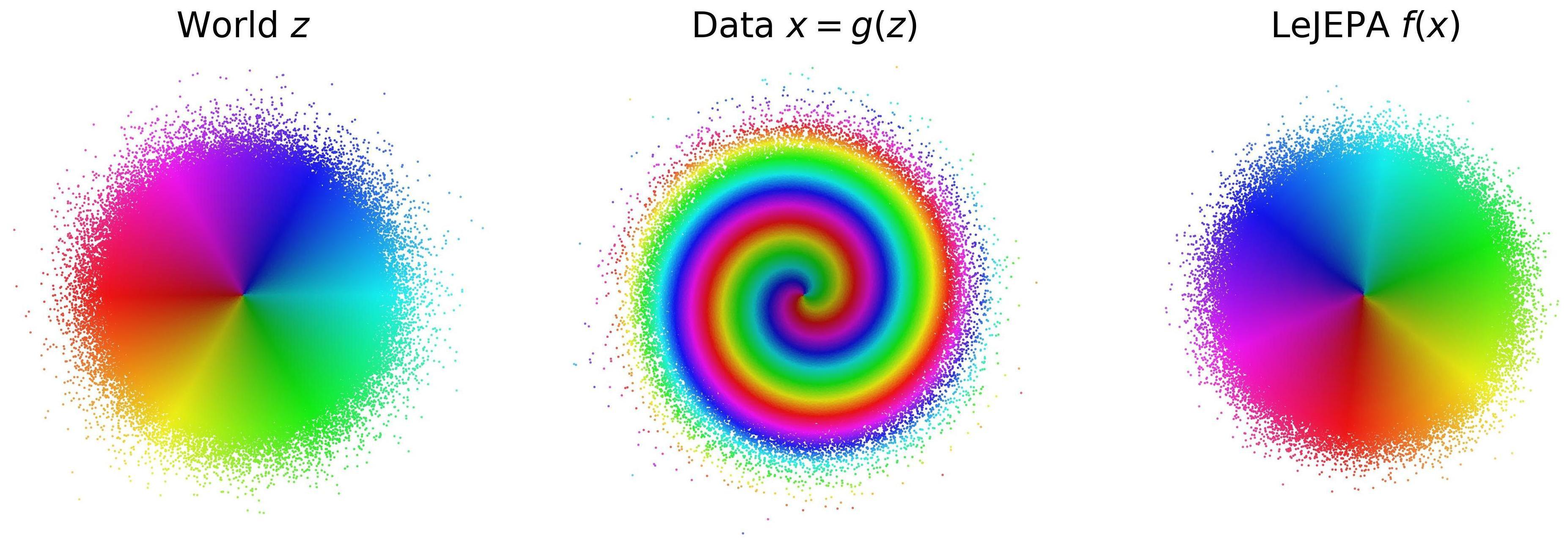
LeJEPA가 복잡한 관측에서 세계의 ‘진짜 좌표(숨은 변수)‘를 거의 그대로 되찾는다는 것, 그리고 그게 가능한 분포는 가우시안이 유일함을 증명한 글. 되찾은 좌표만으로 최적 계획까지 가능하다 — 르쿤의 월드 모델 구상에 형식 검증된 받침대를 놓았다.
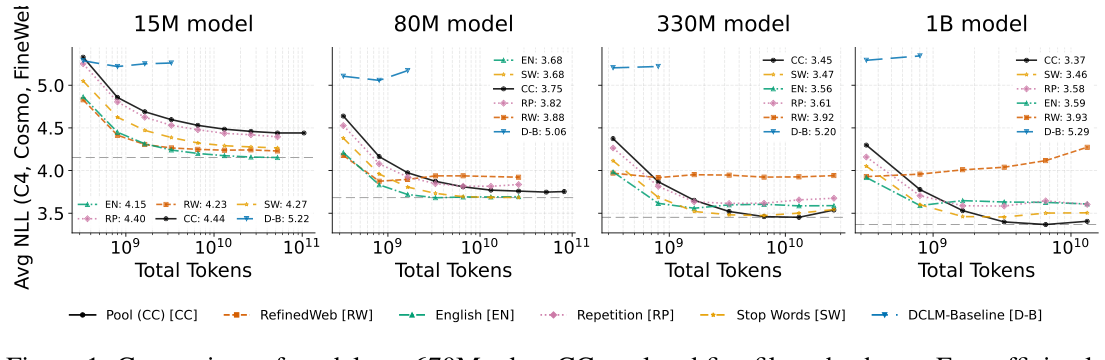
컴퓨트가 충분히 크면 데이터 필터링은 오히려 손해다 — Stanford 연구진이 Common Crawl과 5개 표준 필터를 비교하여, 큰 모델이 ‘저품질’ 데이터에서도 이득을 본다는 증거를 제시한다.

Uber COO Andrew Macdonald가 사내 AI 토큰 지출의 ROI를 정당화하기 어렵다고 발언했다. CTO의 ‘Claude Code 2026년 예산 소진’ 폭로 이후 토큰 사용량과 유용한 기능 산출 사이의 인과 링크가 약하다는 진단이 본격화됐다.
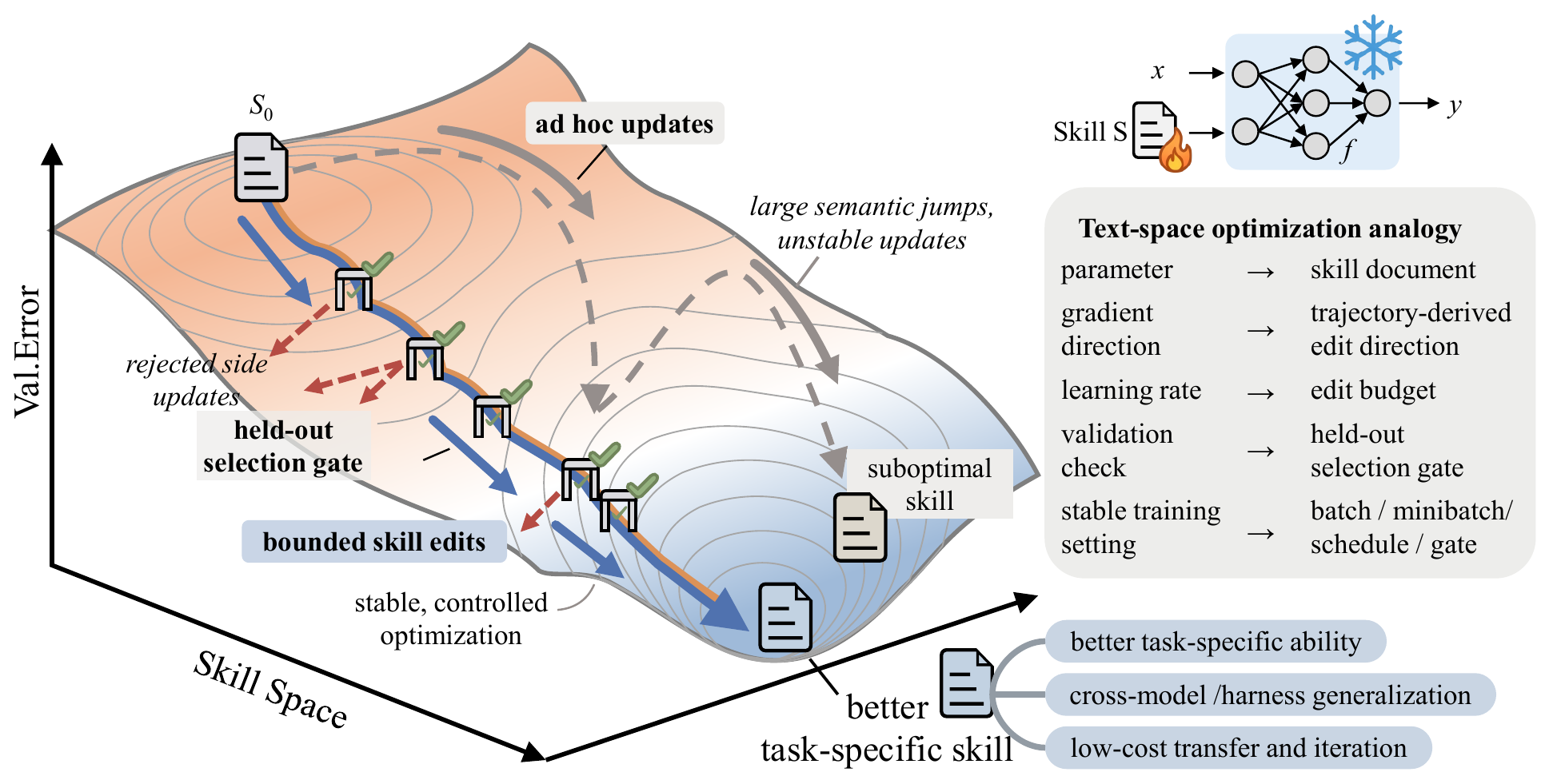
Microsoft가 공개한 SkillOpt는 모델 가중치를 동결한 채 자연어 기술 문서 한 장을 딥러닝 옵티마이저처럼 반복 학습하여 LLM 에이전트의 성능을 끌어올리는 텍스트 공간 최적화 프레임워크다. 채점 가능한 태스크에 한정되며, 6개 벤치마크 52/52 셀에서 최고 또는 공동 최고를 기록했다.
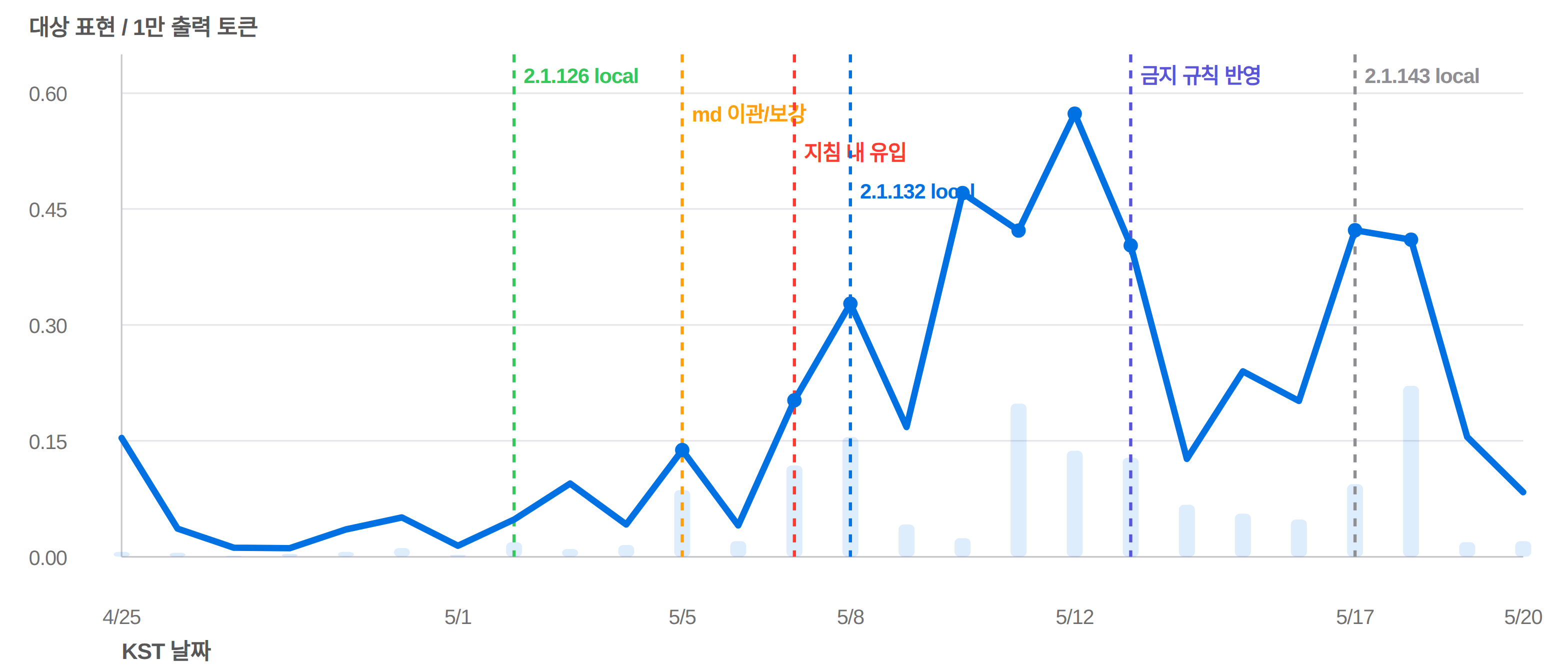
Claude Code 2.1.126 이후 ‘박다/박히다’ 계열 표현이 기준선 대비 18배까지 늘어났다. CLI 업데이트만의 문제가 아니라, 모델의 출력 말버릇이 운영 지침 md로 들어가고 다음 세션이 그 지침을 다시 읽는 자기오염 루프가 있었다는 조사 결과.
Nolan Lawson이 ‘slop cannon’ 통념(LLM 코딩 = 빠르고 저품질)을 정면으로 반박하며, 다중 모델 PR 리뷰 스킬로 LLM을 느리지만 고품질 코드 작성에 쓰는 방법을 정리한다. 결과는 velocity 상승이 아니라 코드베이스 헬스와 친밀도다.