3줄 요약
- Netflix 기술 블로그가 사내 도구 Service Topology를 공개했다. 수천 개의 마이크로서비스가 실제로 어떻게 호출하는지를 실시간으로 보여주는 살아 있는 의존성 맵이다.
- 4년치 엔지니어 지원 요청을 분석한 결과, 사람들이 반복해서 물은 것은 세 가지다 — 내 위·아래에 누가 있는가, 내가 멈추면 어디까지 흔들리는가, 지금 보이는 장애가 내 책임인가 위에서 내려온 것인가.
- 답은 단일 소스가 아니라 세 개의 독립 그래프 — eBPF 네트워크 흐름, IPC 메트릭, 분산 트레이스 — 를 각각의 저장소에 따로 두고, 사용자가 통합 뷰를 요청할 때 병렬 쿼리로 합치는 구조였다.
자료 정보
- 발신자: Netflix Technology Blog
- 저자: Parth Jain, Rakesh Sukumar, Yingwu Zhao, Renzo Sanchez-Silva, Nathan Fisher
- 발행일: 2026-05-29
- 유형: 사내 인프라 회고 (시리즈 1편)
- 분량: 약 12분 분량
이 글은 시리즈의 첫 편이다. 다음 편에서는 Kafka 컨슈머 lag, GC, 리액티브 스트림 디버깅 같은 엔지니어링 디테일을 다룰 예정이라고 밝혔다.
문제: “새벽 3시의 의존성 추적”
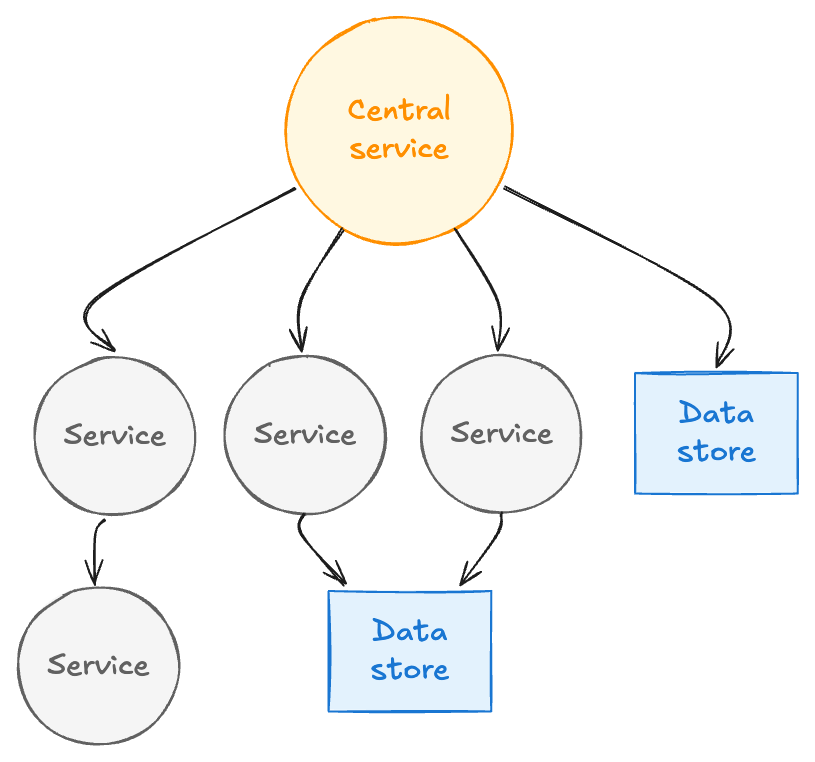
Netflix는 수천 개의 마이크로서비스로 돌아간다. 시청자가 재생 버튼을 누르는 한 번의 동작이 인증·추천·인코딩 선택·재생 최적화로 이어지는 호출 사슬을 만든다. 이 구조는 팀별 독립성을 보장하지만, 장애가 났을 때 관찰가능성에는 근본적인 빈틈을 남긴다.
저자들은 4년간 사내 지원 요청을 분석했다. 반복된 질문은 다음과 같다.
- 내 업스트림·다운스트림 의존성은 무엇인가?
- 이 장애가 내 서비스인가, 내가 의존하는 다른 서비스인가?
- 이 서비스를 점검으로 내리면 어디까지 영향이 가는가?
- 내 메트릭에 Unknown으로 잡힌 호출자가 누구인가?
- 최근 내 호출 경로에서 무엇이 바뀌었는가?
기존 관찰가능성 도구들은 조각만 보여준다 — 메트릭은 증상, 로그는 개별 서비스의 동작, 트레이스는 단일 요청의 경로를 보여준다. 그러나 정상 상태의 토폴로지, 즉 평소에 누가 누구를 부르는지를 보여주는 도구는 없었다. 새벽 3시의 엔지니어가 머릿속에서 이걸 짜맞춰야 한다는 점이 문제였다.
학습한 다섯 가지 원칙
저자들은 그동안 외부 그래프 DB, 벤더 플랫폼, 내부 프로토타입을 반복해서 시도하면서 다음을 배웠다고 정리한다.
| 원칙 | 의미 |
|---|---|
| 실시간성 | 하루에도 여러 번 배포되는 환경에서 몇 시간 묵은 의존성 맵은 쓸모가 없다 |
| 확장성 | 모범적인 외부 도구도 Netflix 규모에서는 벽에 부딪힌다 |
| 통합성 | 엔지니어가 새 도구를 배우게 만들면 안 된다. 기존 워크플로우 안에 들어와야 한다 |
| 데이터 품질 | 불완전·부정확한 의존성 정보는 없는 것보다 나쁘다 — 사고 중 오판으로 이어진다 |
| 다중 관점 | 단일 소스로는 전체 그림이 안 나온다. 네트워크 연결성은 앱 컨텍스트가 없고, 앱 메트릭은 계측된 서비스만 보인다 |
핵심 통찰: 세 개의 진실 소스

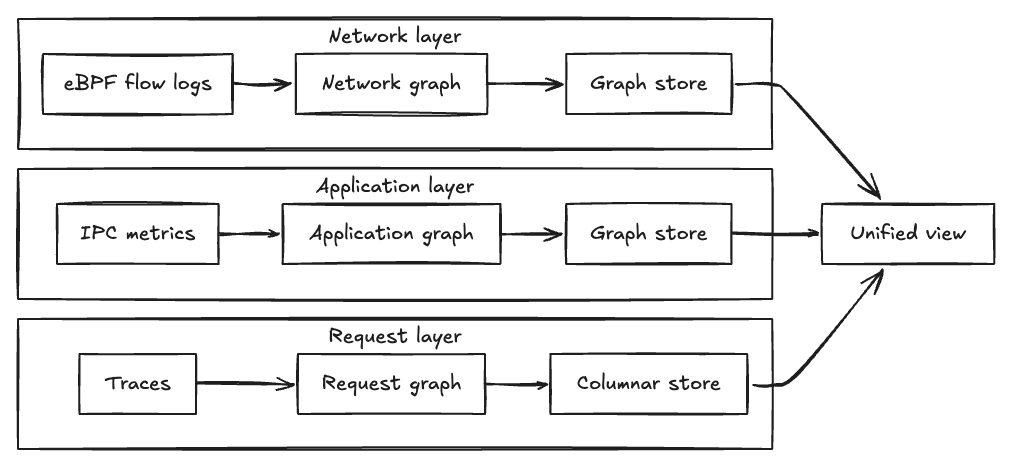
이 글의 가장 핵심적인 설계 선택은 단일 통합 그래프를 만들지 않은 것이다. 대신 세 가지 소스마다 독립된 그래프를 만들고, 사용자가 통합 뷰를 요청할 때만 병렬 쿼리로 합친다.
1. eBPF 네트워크 흐름 (네트워크 레이어)
커널 레벨에서 eBPF로 네트워크 흐름 레코드를 잡는다. 어느 서비스가 어느 서비스의 IP·프로토콜로 연결했는가를 ground truth로 갖는다.
- 장점: 완전성. 계측 여부와 상관없이 모든 서비스가 잡힌다.
- 한계: 앱 컨텍스트가 없다.
/api/v1/users인지/api/v1/orders인지는 모른다.
2. IPC 메트릭 (애플리케이션 레이어)
계측된 서비스가 gRPC·GraphQL·REST 호출을 할 때 내보내는 메트릭을 모은다.
- 장점: 풍부한 앱 컨텍스트 — 어떤 엔드포인트가 호출됐는지, 에러율·레이턴시·프로토콜 디테일을 본다.
- 한계: 계측되지 않은 서비스는 빠진다.
3. 분산 트레이싱 (요청 레이어)
개별 요청이 실제로 흐른 경로를 추적한다. 집계해서 토폴로지로 만들지만, 엔지니어는 개별 트레이스를 토폴로지 위에 오버레이해서 볼 수도 있다.
- 장점: Service A가 Service B를 호출할 수 있다가 아니라, 이 멤버 요청을 처리하면서 실제로 호출했다를 보여준다. 조건 분기·피처 플래그까지 반영된다.
- 한계: 샘플링. 모든 요청을 추적할 수 없으므로 드물게 사용되는 코드 경로는 집계 뷰에서 누락될 수 있다.
셋을 따로 두는 이유
각 소스는 물리적으로 분리된 저장소에 들어간다. 네트워크 그래프는 그래프 DB의 한 파티션, IPC는 다른 파티션, 트레이싱은 분석 쿼리에 최적화된 컬럼 저장소다. 이 분리가 가능하게 하는 것은 다음이다.
- 각 레이어가 독립적으로 진화할 수 있다.
- 통합 뷰가 필요하면 병렬 traversal로 합쳐서 서브초 응답을 낸다.
- 서로의 한계를 보완한다 — 네트워크가 완전성을, IPC가 방법과 무엇을, 트레이싱이 실제 동작을 책임진다.
아키텍처: Kafka → 3단계 집계 → 그래프 DB → gRPC

[다중 리전 Kafka 흐름 로그]
↓
[Apache Pekko Streams 분산 처리]
↓
[Stage 1: 초기 집계]
↓
[Stage 2: 중간자 해소(LB·NAT·API Gateway)]
↓
[Stage 3: 최종 집계 + health 통합]
↓
[Netflix 그래프 DB (소스별 파티션)]
↓
[gRPC API — 다중 홉 traversal, 가용성 tier·도메인 필터, 페이지네이션]
Stage 2가 푸는 문제
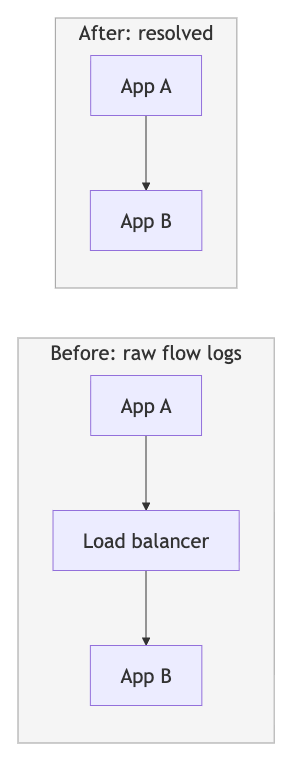
가장 흥미로운 부분이 Stage 2 — 중간자 해소 다. 네트워크 흐름 로그는 개별 네트워크 홉만 기록한다.
원시 로그:
App A → Load Balancer → App B필요한 정보:App A → App B
Stage 2는 로드 밸런서, NAT 게이트웨이, API 게이트웨이, 프록시 같은 중간자를 식별하고, 들어오는 흐름과 나가는 흐름을 매칭해서 직접적인 앱-투-앱 관계를 복원한다. 이 단계별 분산 처리가 핫스팟 도 같이 해결한다 — 트래픽이 100배 몰리는 특정 앱이나 중간자가 있어도 부하가 여러 지점에 분산된다.
그래프 저장소
Netflix의 자체 그래프 DB에 토폴로지를 영속화한다. 분산 키-값 인프라 위에 얹은 추상화 레이어이고, Netflix 규모의 고처리량·다중 홉 traversal에 맞춰져 있다.1
엔지니어가 지금 할 수 있는 것
| 기능 | 의미 |
|---|---|
| 의존성 시각화 | 가용성 tier(0/1…), 비즈니스 도메인으로 필터링. 통합/네트워크-only/IPC-only/트레이스-only 뷰 선택 |
| 디테일로 점프 | 토폴로지의 임의 서비스에서 로그·트레이스·메트릭 도구로 한 번에 이동. 서비스명·시간 윈도우를 손으로 찾지 않아도 된다 |
| 블래스트 반경 | 점검 전에 영향 받을 서비스·통보할 팀을 미리 본다 |
| Health 오버레이 | 호출 경로의 어느 서비스가 아픈지 색으로 본다. 내 문제가 다른 곳에서 시작됐다를 빠르게 가른다 |
| 프로그래매틱 쿼리 | gRPC로 자동화 시스템에 연결. Platform Modernization 팀은 Live 서비스의 가용성 tier가 의존 체인 전체에서 올바르게 분류됐는지 검증하는 데 쓴다 |
| 시간 여행 | 특정 시점의 토폴로지로 되감기. 사고 시작 시점에 무엇이 바뀌었는지 본다. 모든 시간 슬라이스를 따로 저장하지 않고, 레이어별 윈도우 집계기가 시간 구간에 걸쳐 데이터를 누적해서 역사적 뷰를 효율적으로 재구성한다 |
“살아 있는 맵” 이라는 표현
저자들은 이 도구를 반복해서 living map이라 부른다. 디자인 문서에 그려진 정적 다이어그램이 발행되는 순간 outdated가 되는 것과 대조한다.
- 새 서비스가 API를 부르기 시작하면 거의 실시간으로 그래프에 노드가 생긴다
- 호출이 끊긴 의존성은 엣지가 사라진다
- 배포로 동작이 바뀌면 토폴로지가 따라간다
- 사고가 health에 영향을 주면 상태 오버레이가 실시간으로 갱신된다
이 살아 있음이 핵심이다. 엔지니어가 보이는 것을 믿을 수 있어야 도구로서 의미가 있다는 입장이다.
다음 행보: Automated RCA를 향한 지식 그래프
글의 마지막에서 저자들은 좀 더 큰 그림을 던진다.
“토폴로지 그래프를 지속적으로 크롤링하면서 의존성 전반의 실패를 상호 참조하고, 역사적 패턴을 이해하고, 가장 가능성 높은 근본 원인을 자동으로 surface하는 지능형 에이전트를 상상해 보라. Service Topology는 그런 지능형 자동화의 지식 그래프 토대가 된다.”
가까운 단기에는 Change Event Overlay(배포·설정 변경을 토폴로지 위에 겹쳐 보기)와 Richer Context(엔드포인트·프로토콜·네트워크 경로 디테일 확장)를 만들고 있다고 했다.
가장 흥미로운 지점
세 개의 그래프를 물리적으로 분리해 두고 사용자가 요청할 때만 병렬로 합치는 결정이 이 글에서 가장 배울 만한 대목이라 생각한다. 통합된 단일 그래프를 빌드 시점에 미리 만들어 두는 쪽이 직관적이지만, 그 길은 각 소스의 갱신 주기·스키마·실패 양식을 묶어 버린다. 그래서 한 소스가 흔들리면 통합 그래프 전체가 흔들린다.
분리해 두면 — 네트워크 레이어는 항상 모든 것 을 보고, IPC는 계측된 것의 디테일 을 보고, 트레이싱은 샘플링된 실제 호출 을 본다 — 각자의 한계를 사용자가 명시적으로 인지하면서 사용한다. 통합 뷰는 마지막에 합쳐지므로, 어떤 노드가 어떤 소스에서 왔는지가 끝까지 보존된다. 완전성과 디테일을 한 그릇에 끓이지 않고 따로 둔 채 끝물에 섞는 이 결정 이, 4년치 사내 데이터로 학습한 결론이라는 점이 흥미롭다.
또 하나는 블래스트 반경이라는 개념을 일상 도구의 1급 기능으로 끌어올린 점이다. 점검을 실행하기 전에 영향 받는 서비스와 통보할 팀을 자동으로 산출하는 것은, 사고 후 복기보다 사고 전 보호로 관찰가능성의 무게중심을 옮기는 일이다. 이쪽은 아직 업계 표준이 아니다 — 많은 팀이 여전히 경험 많은 시니어의 머릿속에 의존하고 있다.
출처
- 발행 기관: Netflix Technology Blog (Medium)
- 저자: Parth Jain, Rakesh Sukumar, Yingwu Zhao, Renzo Sanchez-Silva, Nathan Fisher
- 발행일: 2026-05-29
- 원문: https://netflixtechblog.com/from-silos-to-service-topology-why-netflix-built-a-real-time-service-map-0165ba13a7bc
본문 도식 4장은 원문(Netflix Technology Blog, Medium)에서 인용했다.