Joel Becker · Nate Rush · Beth Barnes · David Rein / METR / 2025.07.10
3줄 요약
- METR(Model Evaluation & Threat Research)이 2025년 7월에 발행한 무작위 통제 시험(RCT) 보고서다. 대형 오픈소스 리포지토리에 다년간 기여해 온 시니어 개발자 16명에게 자신이 가치 있다고 판단한 실제 이슈 246개를 풀게 하면서, 각 이슈에 대해 AI 도구 사용을 무작위로 허용·불허하여 초기 2025 AI 도구가 실제 생산성에 미치는 영향을 측정한다.
- 핵심 결과는 두 줄로 압축된다. (a) AI 도구를 쓸 수 있는 이슈에서 개발자는 19% 더 오래 걸렸다. (b) 그러면서도 같은 개발자는 사후에도 AI가 자신을 20% 빠르게 했다고 인식하였다. 인식과 현실 사이에 약 39%포인트의 간극이 벌어져 있다.
- 본 결과는 단일 RCT(n=16, 246 이슈)이며 시니어·OSS·자기 리포 세팅의 한 스냅샷이다. 그럼에도 자기 보고 추정치는 매우 부정확할 수 있다는 결론은 표본 한계와 무관하게 강력하다. 벤치마크 점수와 일화적 호평이 가리지 못하는 사각이 있다는 신호다.
자료의 위치
저자는 METR의 Joel Becker, Nate Rush, Beth Barnes, David Rein. METR은 프론티어 AI 시스템이 사회에 미치는 잠재적 위험을 측정하는 비영리 연구 기관이다. 본 연구의 근본 동기는 AI가 AI R&D 자체를 가속할 가능성을 벤치마크 외부의 현실 세팅에서 가늠하는 것이다. 벤치마크는 자족적이고 알고리즘으로 채점 가능하지만, 그 점이 오히려 실제 사용에서의 능력을 과대 또는 과소 평가하게 만들 수 있다는 자각이다.
원문 블로그 포스트는 2025-07-10에 공개되었고, 정식 페이퍼는 arxiv:2507.09089에 올라가 있다. 2026년 2월에는 후속 연구 업데이트가 별도 발행되어 후기 2025 AI 도구의 생산성 영향을 측정한 새 데이터가 추가되었으나, 본 다이제스트는 원본 논문에 한정한다.
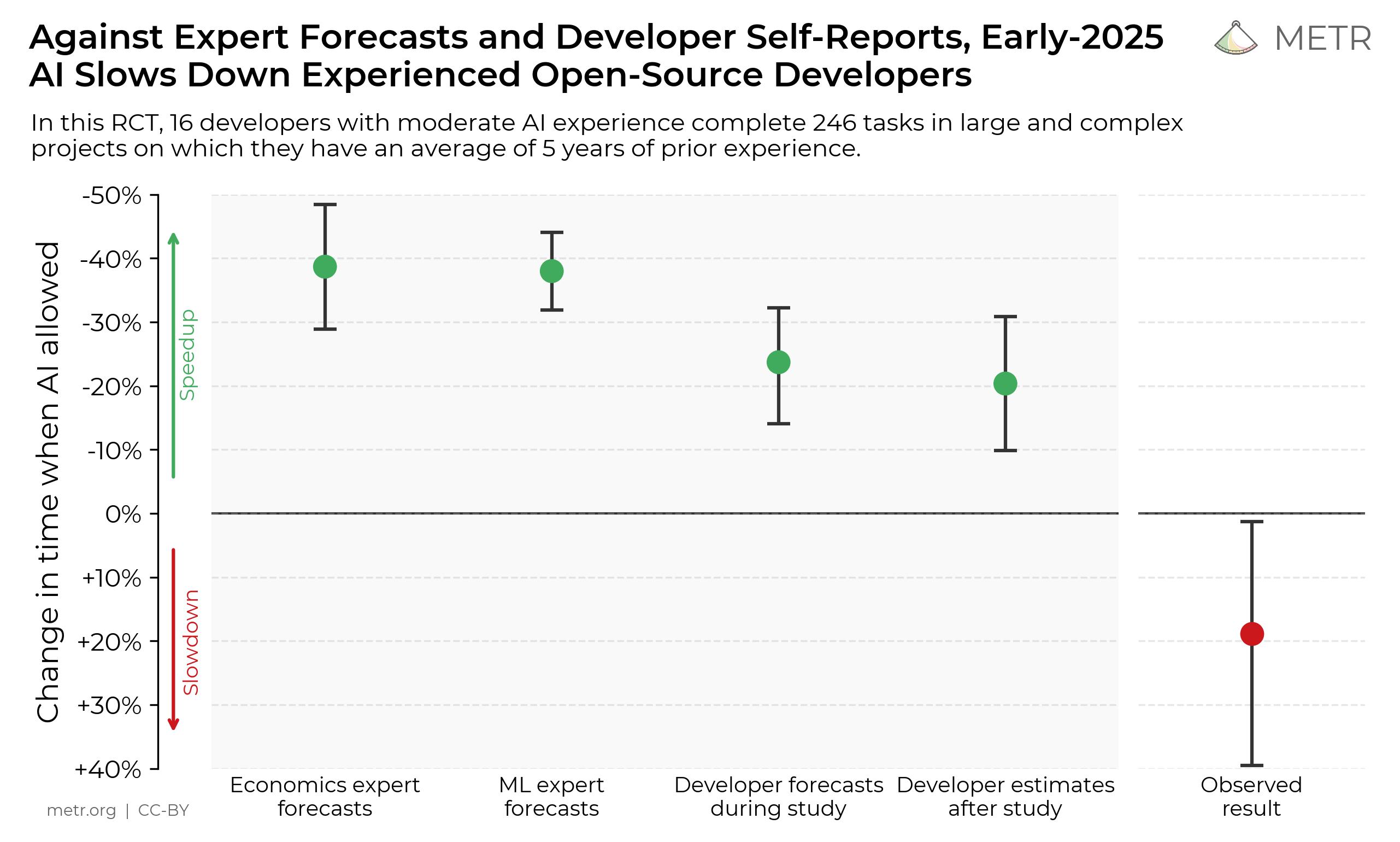 METR이 본 연구의 첫 그림으로 내건 차트. 사전 예측과 관측치의 거리가 본 연구의 출발점이다.
METR이 본 연구의 첫 그림으로 내건 차트. 사전 예측과 관측치의 거리가 본 연구의 출발점이다.
방법론 — 16명·246 이슈·Cursor Pro+Sonnet
본 RCT의 설계는 단순하면서 정교하다. 골자만 추리면 다음과 같다.
- 참가자: 평균 22k+ stars, 1M+ LoC 규모의 대형 OSS 리포지토리에 다년간 기여해 온 경험 많은 개발자 16명. 각자 자신의 익숙한 리포에서만 작업한다.
- 이슈: 개발자가 직접 가치 있다고 판단하여 평소 처리할 만한 실제 이슈 246개. 버그 수정·기능 추가·리팩토링 등 일반적 OSS 작업의 분포를 따른다. 한 이슈의 평균 작업 시간은 약 2시간.
- 무작위화: 각 이슈를 이슈 단위로 AI 허용/불허에 무작위 배정. 같은 개발자가 두 조건 모두를 경험한다(within-developer 설계).
- AI 도구: 허용 시 자유 선택이지만 대부분 Cursor Pro + Claude 3.5/3.7 Sonnet — 연구 시점의 프론티어 모델이다. 불허 시 생성 AI 일체 사용 금지.
- 계측: 화면 녹화 + 자기 보고 구현 시간. 시간당 $150 보상.
 방법론 다이어그램. 각 이슈가 두 조건 사이에 무작위 배정된다.
방법론 다이어그램. 각 이슈가 두 조건 사이에 무작위 배정된다.
설계의 묘미는 세팅의 사실성에 있다. 작업이 합성되거나 단순화된 벤치마크 과제가 아니라, 개발자가 일상에서 처리할 실제 이슈이며, 채점 또한 알고리즘이 아닌 사람이 PR 리뷰를 통과시킬 만큼의 품질이 기준이다.
핵심 결과 — 19% 슬로우다운
When developers are allowed to use AI tools, they take 19% longer to complete issues — a significant slowdown that goes against developer beliefs and expert forecasts.1
AI 도구 사용이 허용된 이슈에서 개발자는 같은 종류의 이슈를 AI 없이 처리할 때보다 19% 더 오래 걸렸다. 통계적으로 유의한 슬로우다운이며, 클러스터링 표준오차로 영가설을 기각한다. 결과는 다양한 결과 측정·추정 방법·하위 분석에서 일관되게 관찰된다.
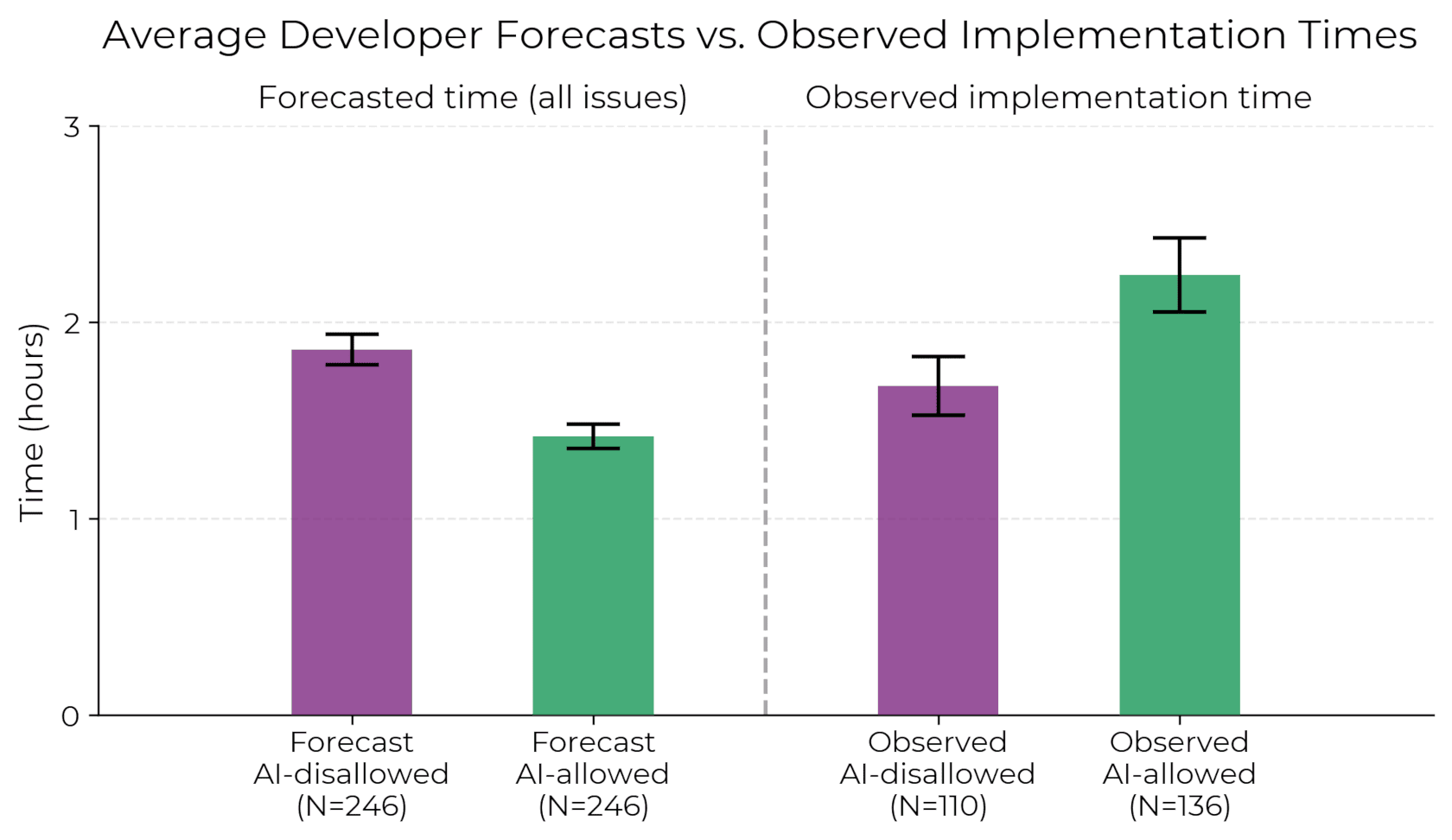 예측 시간 vs 실제 구현 시간. AI 허용 조건의 막대가 더 길다.
예측 시간 vs 실제 구현 시간. AI 허용 조건의 막대가 더 길다.
저자들은 실험 인공물 가설을 미리 처리한다.
- 개발자는 처치 배정에 충실하였다(AI 허용 시 실제로 사용, 불허 시 사용 안 함).
- 어려운 AI-불허 이슈를 차별적으로 드롭하지 않았다(이슈 드롭 비율이 두 조건에서 비슷).
- AI 허용·불허 PR의 품질이 비슷하였다(리뷰어 판정 기준).
즉 슬로우다운은 측정의 부산물이 아니라 사용 자체에서 일어나는 현상이다.
인식과 현실의 간극 — 39%포인트
본 연구가 다른 연구들과 가장 차별화되는 지점은 동일 개발자의 인식을 함께 측정한 데에 있다. 세 시점의 자기 인식이 다음처럼 정렬된다.
| 시점 | 개발자의 인식 | 실측치 |
|---|---|---|
| 사전 예측(experiment 전) | AI가 24% 빠르게 해줄 것 | — |
| 실험 종료 직후 사후 보고 | AI가 20% 빠르게 했다 | −19% (AI가 19% 느리게 함) |
| 인식–현실 간극 | 약 39%포인트 |
같은 사람이 직접 슬로우다운을 경험한 뒤에도 여전히 AI가 자신을 빠르게 했다고 인식한다는 점이 무겁다. 더닝–크루거의 한 사례라 부르기에는 표적이 너무 좁다 — AI 도구의 자기 보고 생산성이라는 하나의 전선에서 39%포인트 간극이 벌어졌다는 사실이다.
원문은 결론부에서 이 간극을 짧게 짚는다.
We now have strong evidence that anecdotal reports/estimates of speed-up can be very inaccurate.
자료에서 anecdotal은 단순히 일화·전설을 가리키는 말이 아니라, 개발자 자신의 자기 보고를 포함하는 폭넓은 지칭이다. 바깥에서 보기에 일화인 것이 안에서 보면 내 진심이라는 점이 본 연구의 어려운 부분이다.
슬로우다운에 기여한 다섯 요인
저자들은 슬로우다운을 설명할 잠재 요인 20개를 검토하여, 그중 다섯 가지가 유의하게 기여한다고 식별한다. 다섯 요인의 명단 자체는 본문에 텍스트로 제시되지 않고 그림 형태로만 나오나, 페이퍼(arxiv:2507.09089)의 §5에서 정량 비중과 함께 분해된다.
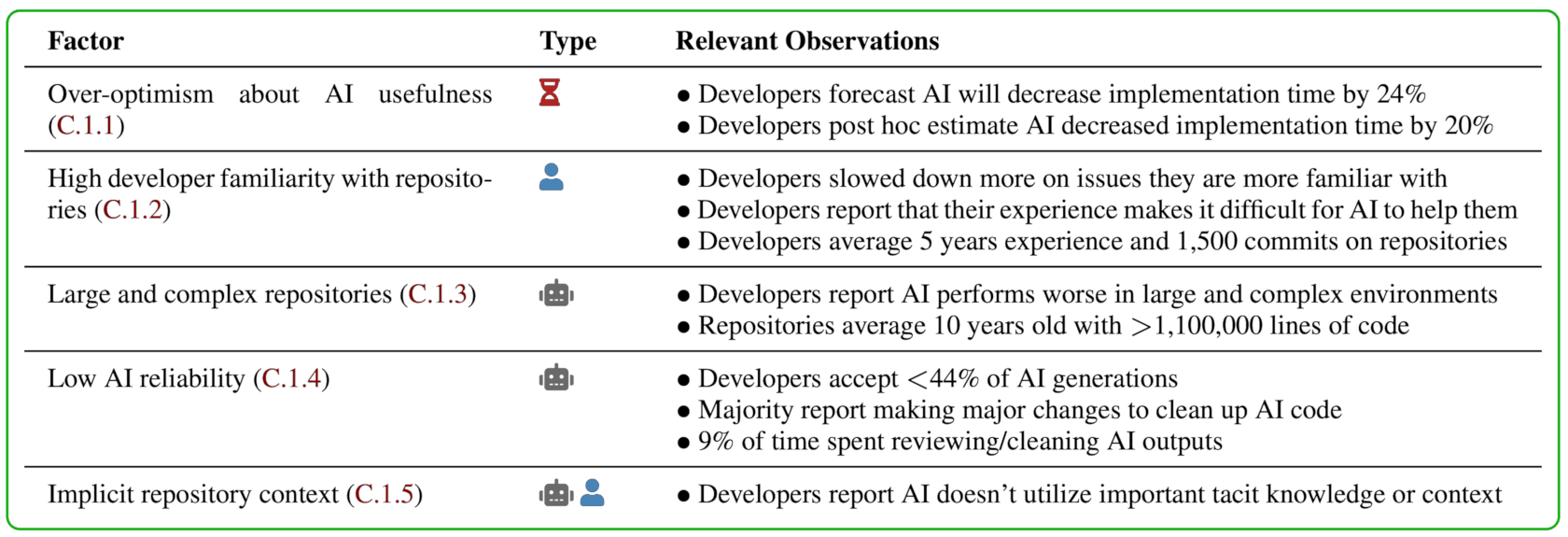 요인 분석. 단일 원인이 아니라 다섯 갈래가 더해져 19%가 만들어진다는 그림이다.
요인 분석. 단일 원인이 아니라 다섯 갈래가 더해져 19%가 만들어진다는 그림이다.
배제된 가설을 명시한 점이 본 연구의 단단함을 만든다. 프론티어 모델 미사용·개발자가 처치를 어김·어려운 이슈의 차별 드롭·AI-허용 PR의 품질 저하 — 이 모든 실험 인공물 가설은 데이터로 기각되었다. 즉 19%는 사용의 한계에서 나오지 측정의 한계에서 나오지 않는다.
다른 측정과의 화해 — 세 가설
본 RCT의 결과는 SWE-Bench Verified의 70%대 점수, 일화적 호평, 그리고 광범위한 도입 수치와 어떻게 화해되는가? 저자들은 어느 것이 맞다고 단정하지 않고, 가능한 세 가지 화해 가설을 제시한다.
| 본 RCT | SWE-Bench·RE-Bench 등 벤치마크 | 일화·널리 퍼진 도입 | |
|---|---|---|---|
| 작업 종류 | 대형·고품질 OSS 리포의 PR | 자족적 코드 문제·AI 연구용 합성 과제 | 다양 |
| 성공 정의 | 사람 리뷰가 통과시킬 품질 (스타일·테스트·문서 포함) | 자동 테스트 케이스 통과 | 사람 사용자가 유용하다고 느낌 |
| AI 형태 | Chat·Cursor agent mode·autocomplete | 완전 자율 에이전트, 수백만 토큰 샘플링·복잡한 스캐폴딩 | 다양 |
| 관측치 | 20분~4시간 현실 코딩 과제에서 느려짐 | 사람도 어려운 과제에서 자주 성공 | 1시간 이상 작업에서 유용하다고 보고 |
저자들이 제안하는 화해 가설 셋은 다음과 같다.
- 본 RCT가 능력을 과소 평가한다. 본 세팅에 알려지지 않은 방법론적 문제가 있고, 다른 중요 세팅과는 성질이 다를 수 있다.
- 벤치마크와 일화가 능력을 과대 평가한다. 알고리즘 채점·자기 보고가 실제 유용성과 어긋날 수 있다.
- 셋 다 부분적으로 옳다. 각자가 서로 다른 부분 분포를 측정하며, 모델은 그 부분 분포마다 다른 능력 수준을 보인다.
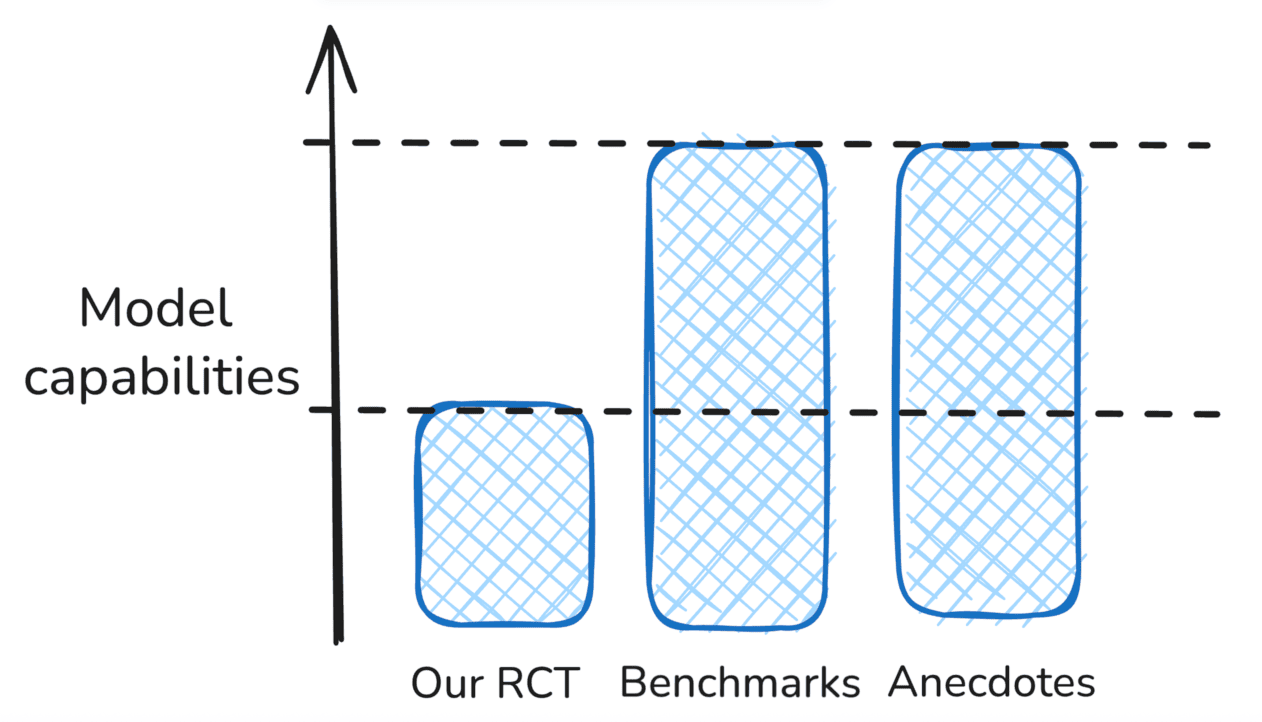 요약 다이어그램. 세 측정이 향한 곳이 같은 별이 아닐 수 있다는 시각화다.
요약 다이어그램. 세 측정이 향한 곳이 같은 별이 아닐 수 있다는 시각화다.
저자들은 어느 가설이 가장 큰 비중을 차지하는지는 추가 연구가 필요하다고 보수적으로 마감한다. 다만 한 가지는 가설 선택과 무관하게 강력하다 — 자기 보고 추정치는 매우 부정확할 수 있다는 점이다.
연구가 주장하지 않는 것 네 가지
본 연구가 가장 정직한 부분은 over-generalization 방지를 위한 명시적 한계 표명에 있다. 저자들은 본 결과로부터 입증되지 않는 명제 네 가지를 본문에 표로 제시한다.
| 본 연구가 입증하지 않는 명제 | 명확화 |
|---|---|
| AI 시스템이 현재 대다수 또는 대부분의 소프트웨어 개발자를 가속하지 못한다 | 본 16명·OSS 세팅이 다수 개발 작업을 대표한다고 주장하지 않는다 |
| AI가 소프트웨어 개발 외 영역에서 가속을 일으키지 못한다 | 본 연구는 소프트웨어 개발만을 측정한다 |
| 근시일 AI가 같은 세팅에서 가속을 일으키지 못한다 | 진보 예측은 어렵고 지난 5년간 상당한 진전이 있었다 |
| 더 효과적 사용으로 양의 가속도가 불가능하다 | Cursor는 토큰을 많이 샘플링하지 않고 최적 프롬프트·스캐폴딩이 아닐 수 있으며, 도메인·리포 특화 fine-tuning은 양의 결과를 낼 수 있다 |
즉 본 결과는 2025년 초 / 시니어 OSS 개발자 / 자신이 잘 아는 리포라는 한정된 세팅의 스냅샷이다. 그럼에도 그 스냅샷에서 일어난 19%와 39%p는 분명한 사실이다. 겸손과 단단함의 공존이 본 연구의 신뢰도를 받쳐주는 기둥이다.
FAQ — 그래도 의심이 남을 때
원문은 FAQ에서 자주 받는 의문을 미리 처리한다. 정리하면 다음과 같다.
- n=16인데 일반화 가능한가? 246 이슈를 이슈 단위로 무작위 배정하고 within-developer 구조를 활용해 영가설을 기각할 통계력을 확보했다. 표본 편향 가능성은 인정하되, 일관된 슬로우다운은 강건하다.
- 개발자가 Cursor 초보자라서 그런가? 거의 모든 참가자가 LLM 프롬프팅 경험이 수십~수백 시간이며, Cursor Pro 사용자 분포 안에 있다. 50시간 이상 학습 효과는 본 연구로 측정 불가.
- AI가 비효율적인 줄 알면서 왜 썼는가? 사후 평균 인식이 AI가 20% 빠르게 했다였다. 본인이 슬로우다운을 인식하지 못한 것이지, 알면서도 사용한 것이 아니다.
- 본 결과로 AI가 SW에 무용하다는 것 아닌가? 그렇지 않다. 덜 숙련된 개발자나 낯선 코드베이스에서는 양의 효과가 있을 가능성이 높다는 입장이다.
핵심 함의
본 연구의 무게중심은 방향이 반대였다는 사실에 있다. 빠르다고 생각하면서 느려진 것이 아니라, 빠르다고 느낀 것이 거짓이었다는 점이 무겁다. 사람의 인식이 통상 작은 오차로 진실 주위를 맴돌지 부호 자체를 뒤집지 않는다는 점에 비추면, 39%포인트 간극은 추정의 부정확성이라기보다 체감 자체가 시스템적으로 왜곡된다는 신호로 읽힌다.
저자들은 본문에서 그 메커니즘을 단정하지 않고 가설 수준에서 그어둔다. 다만 잭팟의 순간은 또렷이 기억되고 토큰을 채워 넣은 두 시간은 흐릿하게 흘러간다는 기억의 표본 편향이 인식을 만들고, 그 인식이 자기 보고 통계를 만든다는 도식이 함의로 따라온다. AI가 X% 빨라진다는 자기 보고 기반 수치가 체감의 가공물일 수 있다는 함의다.
또 한 가지. 본 연구가 입증하지 않는 네 명제를 표로 정리해 둔 부분이 결과의 신뢰도를 역으로 끌어올린다. 19%라는 수치 자체보다 그 수치의 정확한 적용 범위를 명시해 둔 표가 본 연구의 단단함을 만든다.
출처
발행: METR (Model Evaluation & Threat Research) / 2025-07-10
저자: Joel Becker · Nate Rush · Beth Barnes · David Rein
원문 블로그: https://metr.org/blog/2025-07-10-early-2025-ai-experienced-os-dev-study/
정식 페이퍼(arxiv): https://arxiv.org/abs/2507.09089
인용 보도: MIT Technology Review Hype Correction 시리즈 (Edd Gent, 2025-12-15) — https://www.technologyreview.com/2025/12/15/1128352/rise-of-ai-coding-developers-2026/ ↩︎