3줄 요약
- Meta FAIR가 트랜스포머의 FFN 레이어 일부를 학습 가능한 key-value 메모리 레이어로 대체하는 Memory Layers at Scale 아키텍처를 제안한다.
- FLOP을 거의 늘리지 않고 파라미터만 128B까지 확장하여, 사실 기반 QA에서 2~4배 컴퓨트 예산의 dense 모델을 능가한다.
- MoE보다 사실 과제에서 압도적이며, 1.3B 베이스 + 128B 메모리가 7B dense와 동급 성능을 달성한다.
핵심 아이디어: 연산 없이 파라미터만 추가한다
LLM은 “서울의 수도는?”, “아인슈타인의 생일은?” 같은 단순 연관(key→value)을 feed-forward network(FFN)의 행렬 곱셈으로 학습한다. 가능은 하지만 효율적이지 않다. 연관 기억(associative memory)이 본래 하는 일을 범용 함수 근사기가 대신하고 있기 때문이다.
메모리 레이어는 이 문제를 정면으로 공략한다. 학습 가능한 key-value 쌍 수백만 개를 배치하고, 입력 토큰과 가장 유사한 top-k 키만 골라서 가중합을 구한다. FFN 레이어 하나를 통째로 대체하는 구조이므로, 파라미터는 수십~수백억 개 늘어나지만 연산량(FLOP)은 거의 그대로다.
아키텍처 설계
Product-key 검색
수백만 개 키에 대한 전수 비교는 비용이 크다. 이 논문은 키를 두 개의 sub-key로 분해하는 product-key 방식을 사용한다. N개 키의 전수 비교(O(N)) 대신 2√N번의 비교로 top-k를 찾는다.
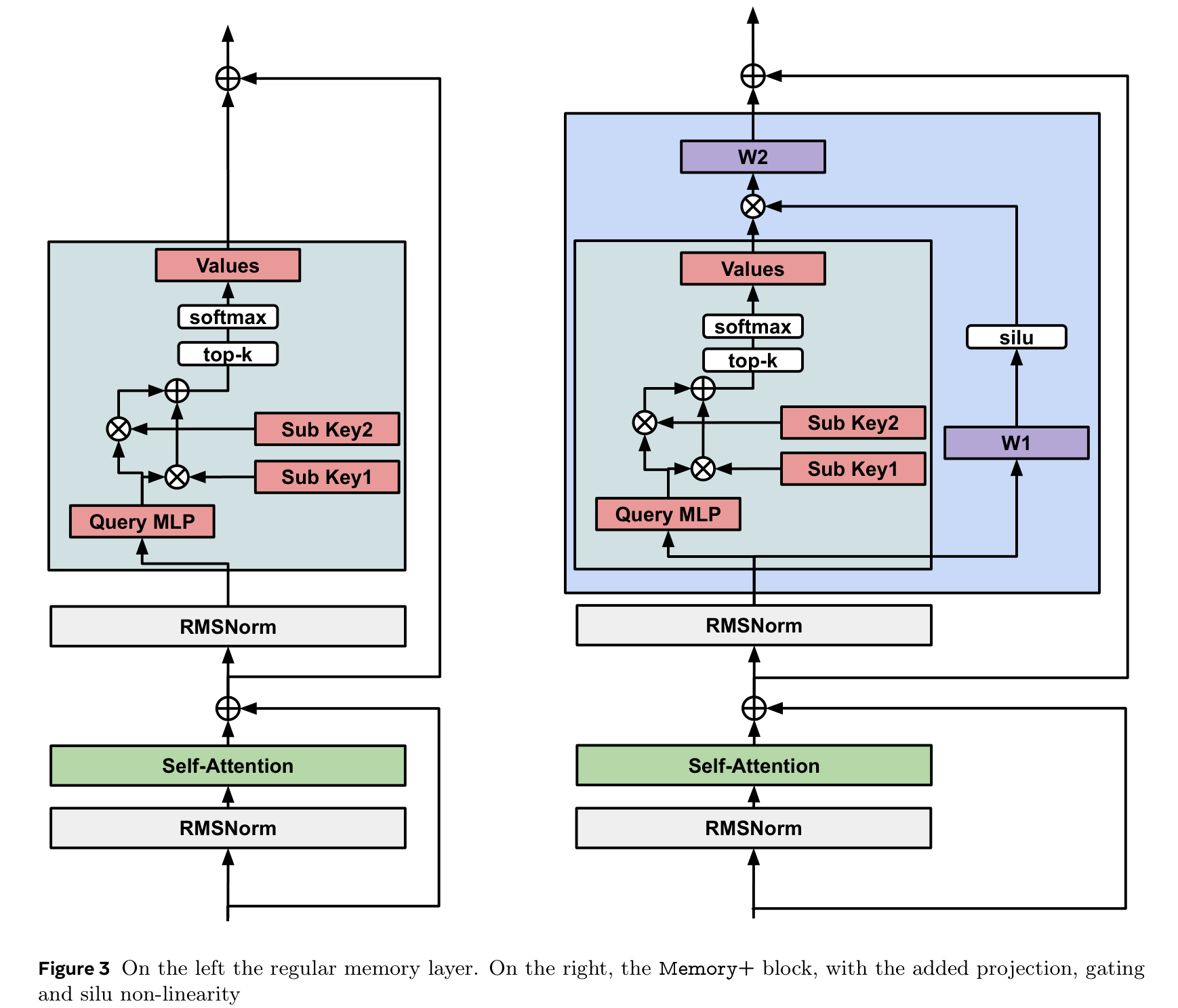
Memory+ 블록
기본 메모리 레이어에 입력 의존적 게이팅과 SiLU 비선형성을 추가한 것이 Memory+ 아키텍처다.
output = (y ⊙ silu(xTW₁))TW₂
메모리 검색 결과(y)를 입력 신호(x)로 게이팅하여, 메모리에서 꺼낸 정보를 현재 맥락에 맞게 조절한다. 대규모 메모리에서 발생하는 학습 불안정성은 qk-normalization으로 해결한다.
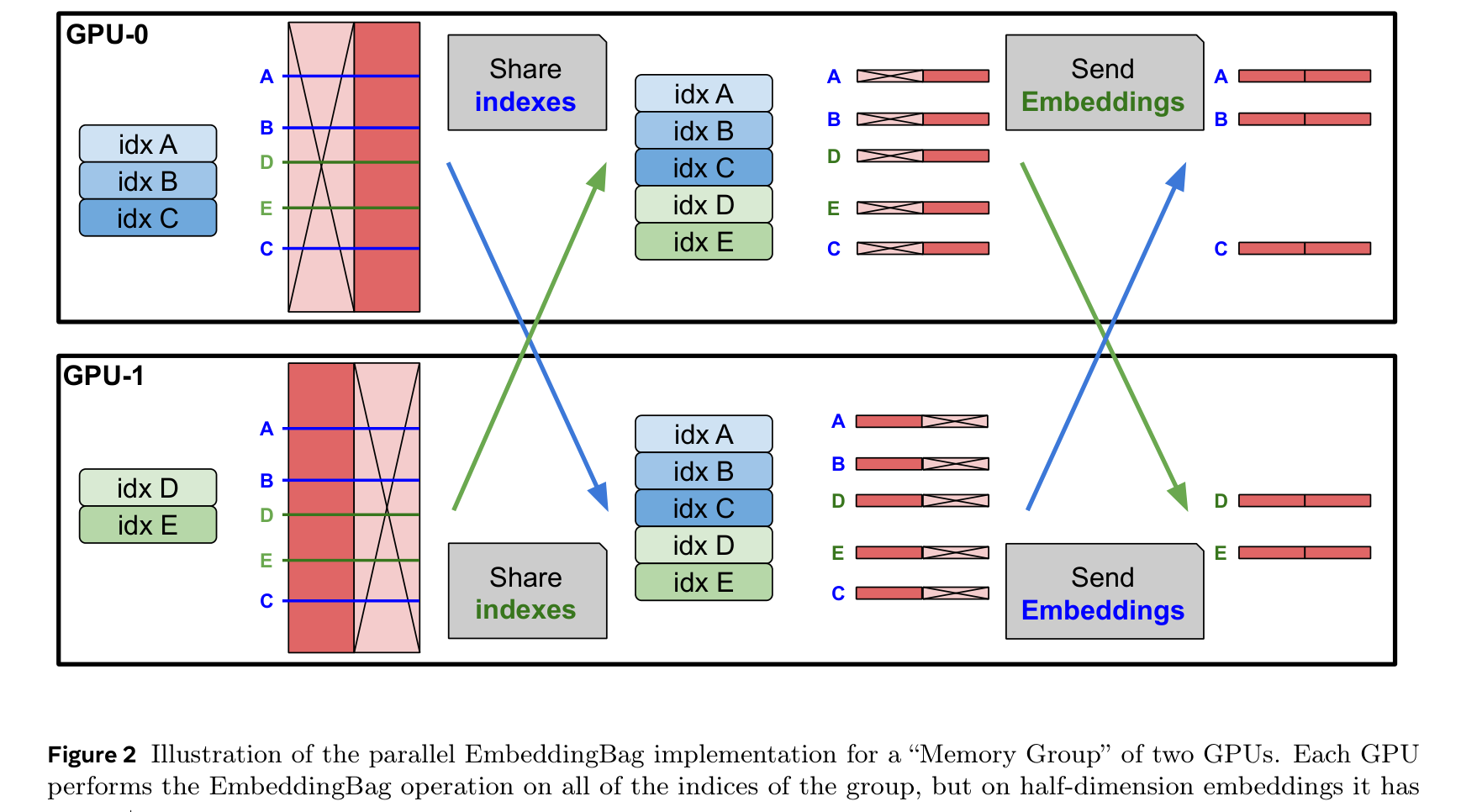
병렬 EmbeddingBag 구현
메모리 레이어의 핵심 연산은 FLOP이 아니라 메모리 대역폭에 병목이 걸린다. 저자들은 커스텀 CUDA 커널을 구현하여 순전파에서 H100의 이론 대역폭(3.35TB/s)에 근접한 3TB/s를 달성했다. PyTorch 기본 EmbeddingBag 대비 6배 빠르다.
공유 메모리 풀
여러 FFN 레이어를 메모리 레이어로 교체할 때, 메모리 파라미터를 공유 풀(shared pool)로 운영한다. 파라미터 수 증가 없이 다층 메모리를 사용할 수 있다. 실험 결과 3개 레이어가 최적이며, 그 이상은 dense 파라미터 손실로 성능이 하락한다. 배치는 모델 중앙에서 넓은 간격으로.
스케일링 결과
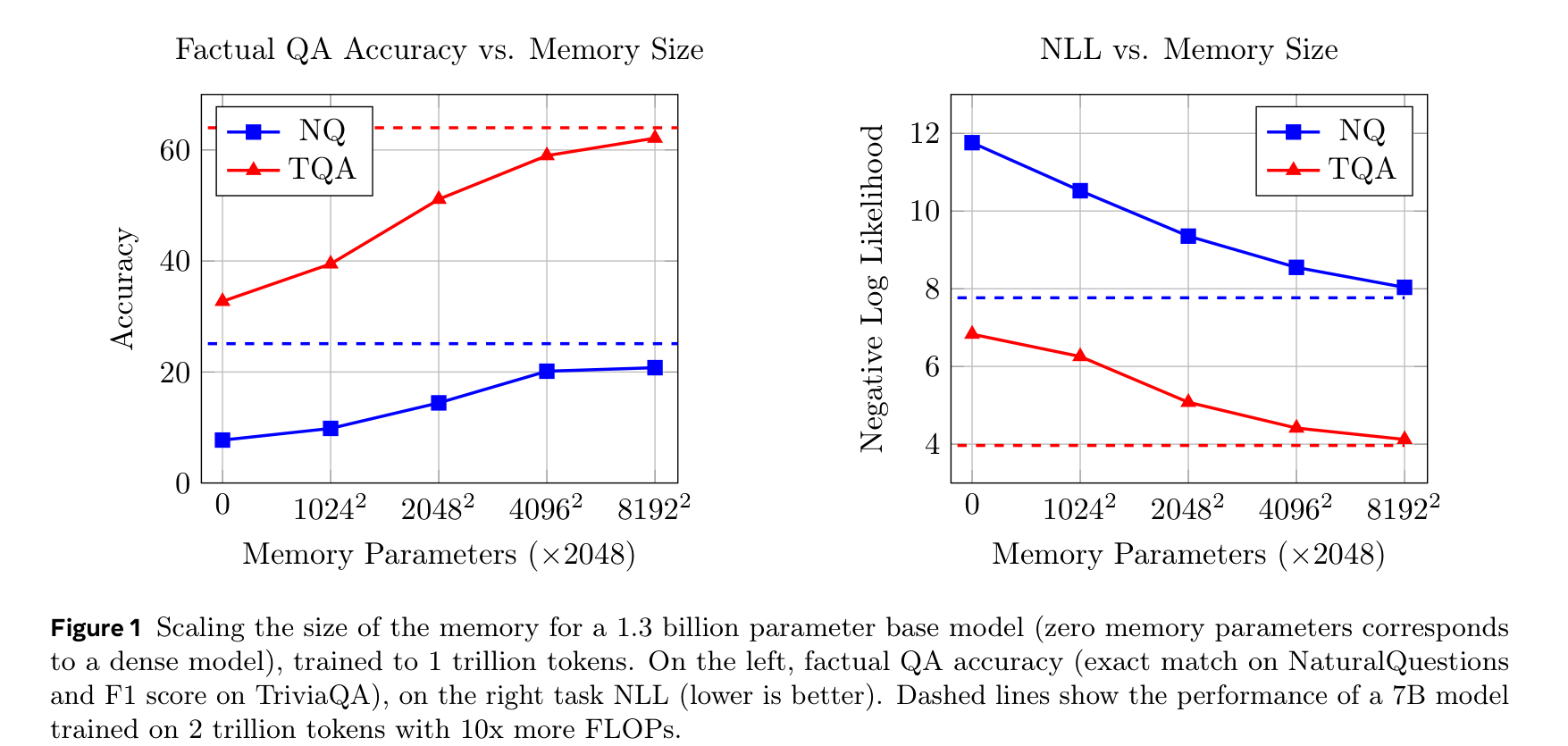
메모리 크기에 따른 성능
1.3B 베이스 모델에서 메모리 크기를 0에서 128B 파라미터까지 키우면, 사실 QA 정확도가 예측 가능한 로그-선형 관계로 꾸준히 상승한다. 64M 키(128B 메모리 파라미터)에서 2T 토큰으로 훈련한 Llama2 7B의 성능에 근접하는데, 이는 10배 적은 FLOP으로 달성한 것이다.
8B 스케일 결과
8B 베이스 + 64B 메모리의 Memory+ 모델은 1T 토큰 훈련만으로 15T 토큰의 Llama3.1 8B에 근접한다.
| 벤치마크 | Llama3.1 8B (15T) | Memory+ 8B (1T) | dense 8B (1T) |
|---|---|---|---|
| MMLU | 66.00 | 63.04 | 59.68 |
| HellaSwag | 60.05 | 60.29 | 58.90 |
| TriviaQA | 70.36 | 68.15 | 63.62 |
| HumanEval | 37.81 | 31.71 | 29.88 |
학습 초기(200B 토큰)에 이점이 더 두드러지는데, 메모리가 사실 학습을 가속한다는 것을 시사한다.
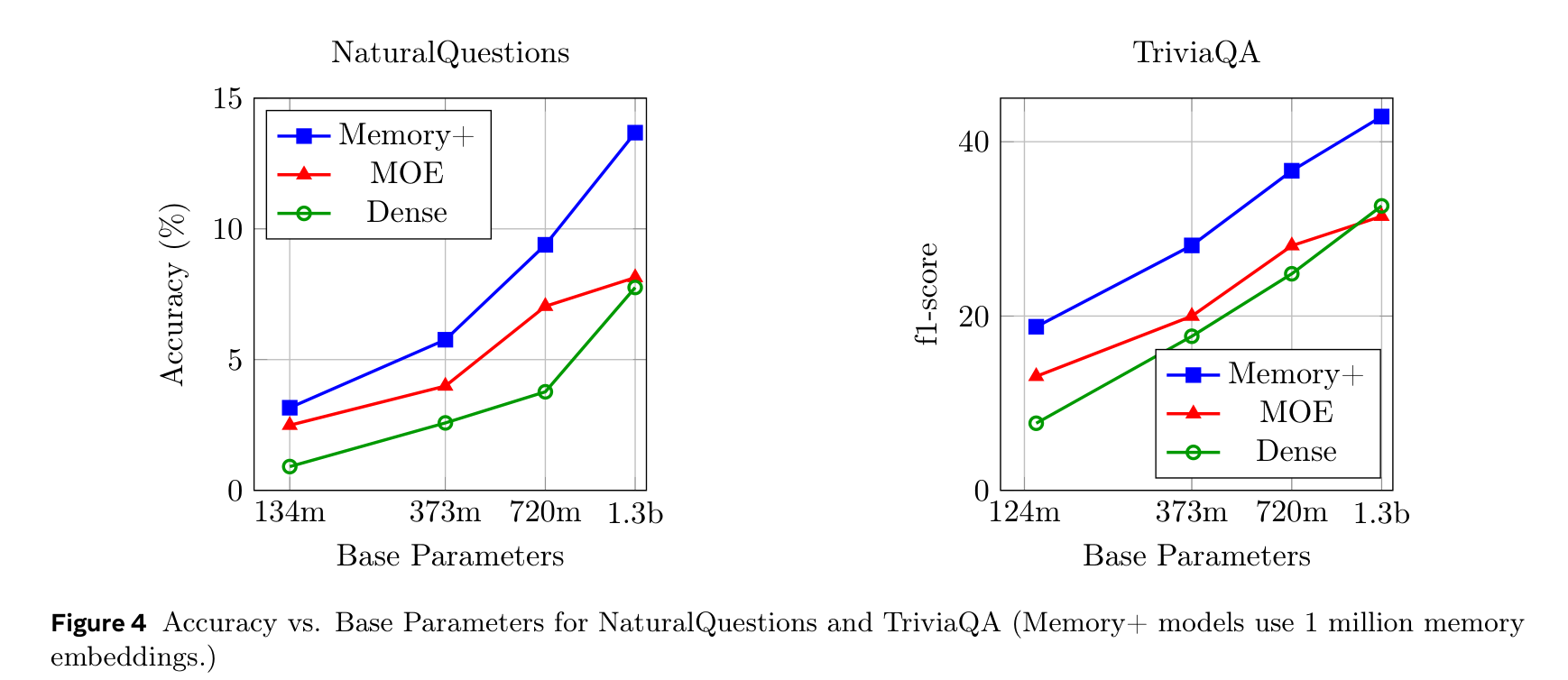
MoE 대비 우위
같은 파라미터·컴퓨트 조건에서 Memory+는 MoE를 모든 벤치마크에서 능가하며, 사실 QA에서 격차가 가장 크다. MoE가 dense FFN의 변형인 반면, 메모리 레이어는 본질적으로 다른 메커니즘(희소 key-value 검색)이기 때문이다.
Dense와 Sparse의 상보성
메모리 레이어가 모든 FFN을 대체할 수는 없다. 3개를 넘기면 성능이 하락한다는 실험 결과는 dense 연산(추론·일반화)과 sparse 검색(사실 저장·회상)이 상보적임을 보여준다. 차세대 아키텍처는 둘을 의도적으로 분리하여 각각에 최적의 자원을 배분해야 한다.
한계
Dense 아키텍처는 수십 년간 GPU에 최적화되어 왔다. 메모리 레이어는 FLOP이 아닌 메모리 대역폭에 병목이 걸리는 근본적으로 다른 워크로드이며, 하드웨어·소프트웨어 양면에서 추가 최적화가 필요하다. 저자들은 원칙적으로 가능하다고 주장하지만, 현재는 미해결 엔지니어링 과제다.
가장 흥미로운 지점
“모든 지식을 행렬 곱셈으로 인코딩하는 것이 최선인가?“라는 질문을 정면으로 던진 논문이다. LLM의 사실 기억 문제를 RAG(외부 검색)가 아닌 아키텍처 내부의 구조적 분리로 접근한 점이 인상적이다. Dense 레이어는 추론에, 메모리 레이어는 사실 저장에 — 이 분업이 인간의 뇌에서 해마와 대뇌피질의 역할 분담을 연상시킨다.
출처
Meta FAIR, Vincent-Pierre Berges, Barlas Oğuz 외 (2024년 11월 26일) 원문: https://github.com/facebookresearch/memory