3줄 요약
- Microsoft Research와 Salesforce Research가 2025년 5월 공개한 LLM 평가 논문. 6개 태스크·15개 LLM·20만 건 이상의 시뮬레이션 대화로 단일턴과 다중턴 성능 차이를 정량화했다.
- 모든 모델·모든 태스크에서 다중턴(underspecified) 성능이 평균 39% 저하된다. 분해해 보면 능력은 16% 정도만 떨어지지만, 신뢰성은 112% 폭증한다 — 즉 같은 문제를 10번 풀면 best와 worst 사이 50점 차이가 난다.
- 한 번 잘못 가면 LLM은 회복하지 못한다. 저자들은 이 현상을 “Lost in Conversation"이라 부르고, 에이전트 프레임워크의 우회(RECAP·SNOWBALL)나 temperature=0 트릭으로는 메워지지 않는 구조적 한계임을 보인다.
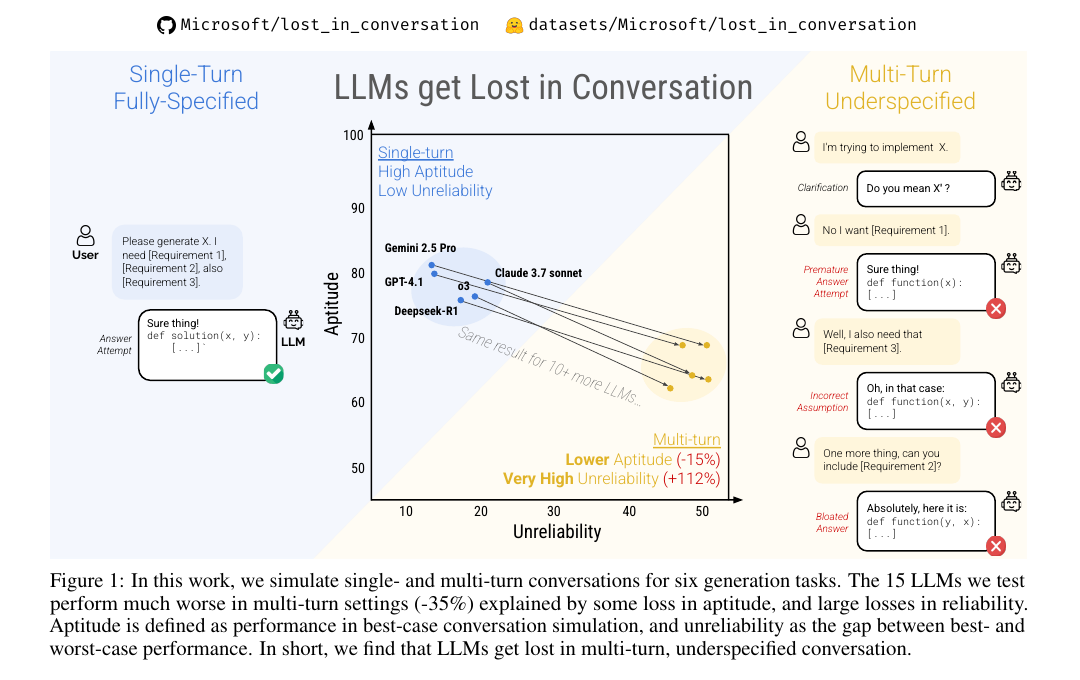 Figure 1. 좌측은 단일턴 fully-specified 조건(높은 Aptitude·낮은 Unreliability), 우측은 다중턴 underspecified 조건(Aptitude -15%, Unreliability +112%). Laban et al., 2025.
Figure 1. 좌측은 단일턴 fully-specified 조건(높은 Aptitude·낮은 Unreliability), 우측은 다중턴 underspecified 조건(Aptitude -15%, Unreliability +112%). Laban et al., 2025.
자료 개요
- 제목: LLMs Get Lost In Multi-Turn Conversation
- 저자: Philippe Laban (Microsoft Research), Hiroaki Hayashi·Yingbo Zhou (Salesforce Research), Jennifer Neville (Microsoft Research)
- 발표: arXiv 2505.06120, 2025년 5월 9일
- 코드·데이터:
github.com/microsoft/lost_in_conversation,huggingface.co/datasets/Microsoft/lost_in_conversation1 - 실험 비용: 약 USD 5,000 (저자 추산)
저자들은 기존 LLM 평가가 거의 모두 단일턴·fully-specified 조건에 머물러 있다고 진단한다. 그러나 실제 사용자들은 자기 요구를 처음부터 완전히 명세하지 않으며, 여러 턴에 걸쳐 점진적으로 드러낸다. 이 논문은 그 간극을 메우기 위한 첫 대규모 시뮬레이션이다.
무엇을 측정했나 — Sharded Simulation
핵심 장치는 sharded instruction이다. GSM8K·HumanEval·Spider 등 기존 단일턴 벤치마크의 instruction을 의미 단위 “shard"로 쪼개, 사용자 시뮬레이터가 매 턴마다 최대 한 shard씩 흘리도록 만든다. 최종적으로 전달되는 정보량은 원본과 동일하되, 전달 속도만 달라진다.
 Figure 2. 좌측은 원본 instruction(“Jay is making snowballs…”), 우측은 같은 정보를 다섯 조각으로 나눈 sharded instruction.
Figure 2. 좌측은 원본 instruction(“Jay is making snowballs…”), 우측은 같은 정보를 다섯 조각으로 나눈 sharded instruction.
대화 시뮬레이션 구조는 다음과 같다.
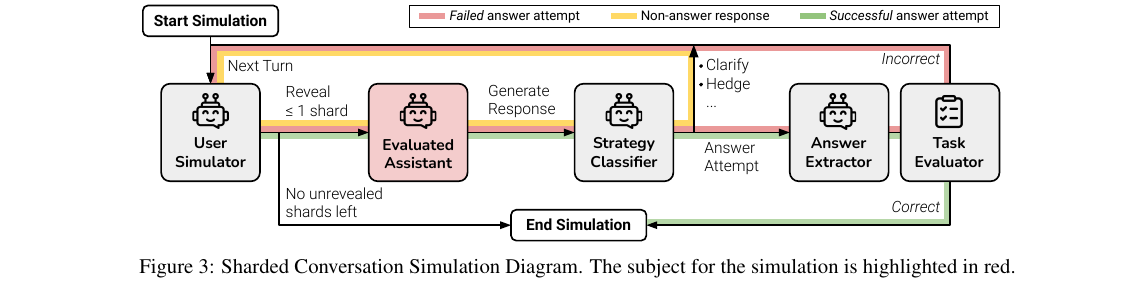 Figure 3. 매 턴 user simulator가 shard를 흘리고, 평가 대상 LLM이 응답한 뒤, strategy classifier가 응답을 7개 카테고리(clarification·refusal·hedging·interrogation·discussion·missing·answer attempt)로 분류한다. answer attempt가 나오면 task evaluator가 채점한다.
Figure 3. 매 턴 user simulator가 shard를 흘리고, 평가 대상 LLM이 응답한 뒤, strategy classifier가 응답을 7개 카테고리(clarification·refusal·hedging·interrogation·discussion·missing·answer attempt)로 분류한다. answer attempt가 나오면 task evaluator가 채점한다.
시뮬레이션 유형은 다섯 가지를 비교한다.
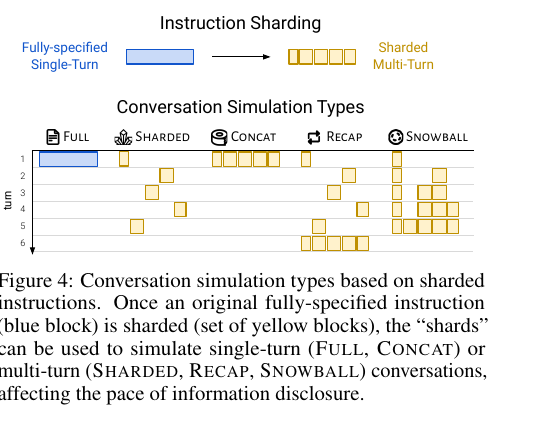
| 유형 | 설명 | 역할 |
|---|---|---|
| FULL | 원본 single-turn instruction을 1턴에 전달 | 상한선 baseline |
| SHARDED | shard를 매 턴 1개씩 노출 (실험 대상) | 다중턴 underspecified |
| CONCAT | shard를 모두 이어붙여 1턴에 전달 | rephrase 효과만 격리 |
| RECAP | SHARDED 끝에 전체 정보 재진술 1턴 추가 | 사후 보정 시도 |
| SNOWBALL | 매 턴마다 누적 재진술 | 능동적 보정 시도 |
태스크는 프로그래밍 영역의 Code(HumanEval·LiveCodeBench)·Database(Spider)·Actions(Berkeley Function Calling)·Math(GSM8K), 자연어 영역의 Data-to-Text(ToTTo)·Summary(Summary of a Haystack) 여섯 가지다. 태스크당 90–120개 instruction을 sharded 버전으로 변환했고, 각 (LLM, instruction, 시뮬레이션 유형) 조합당 10회 반복하여 평균과 분포를 측정했다.
평가 메트릭은 세 가지를 분리한다. Average Performance(P̄), Aptitude(상위 10분위 점수 — best-case 능력), Unreliability(상위 10분위와 하위 10분위 점수 차이 — 결과 변동성). 단일 평균치로는 능력 손실과 신뢰성 손실을 구분할 수 없기에 두 축을 분리해 보고한다.
무엇을 발견했나 — Lost in Conversation
모든 LLM, 모든 태스크에서 SHARDED 성능이 FULL 대비 평균 39% 저하한다.
이 결과는 GPT-4.1·Claude 3.7 Sonnet·Gemini 2.5 Pro 같은 최첨단 모델부터 Llama 3.1-8B·OLMo-2-13B 같은 소형 모델까지 예외 없이 관찰된다. 모델별로 30–40% 폭의 일관된 저하다.
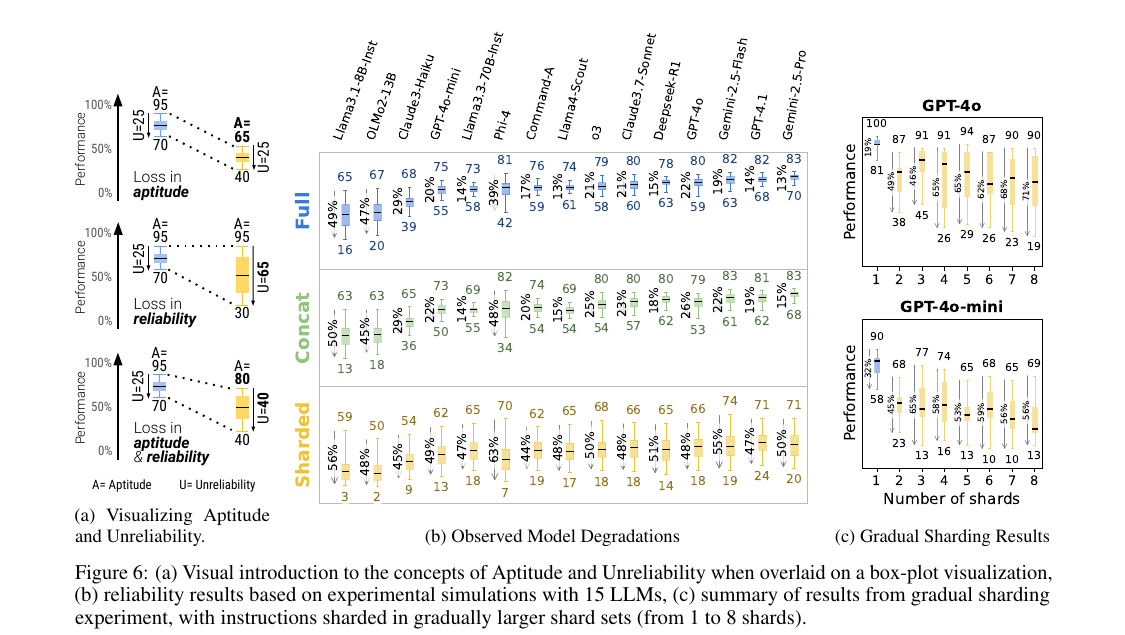 Figure 6. (a) Aptitude와 Unreliability의 박스플롯 정의. (b) 15개 LLM 결과 — FULL 조건(상단)과 비교해 SHARDED 조건(하단)에서 모든 모델이 큰 폭으로 떨어지고 변동성이 폭증한다. (c) Gradual sharding 실험에서 shard 수가 1에서 2로만 늘어도 즉시 성능 저하가 발생한다.
Figure 6. (a) Aptitude와 Unreliability의 박스플롯 정의. (b) 15개 LLM 결과 — FULL 조건(상단)과 비교해 SHARDED 조건(하단)에서 모든 모델이 큰 폭으로 떨어지고 변동성이 폭증한다. (c) Gradual sharding 실험에서 shard 수가 1에서 2로만 늘어도 즉시 성능 저하가 발생한다.
성능 저하를 두 축으로 분해하면 그림이 더 명확해진다.
- Aptitude 손실은 평균 16% 정도로 크지 않다. 능력 좋은 모델은 다중턴에서도 약간 더 높은 best-case 점수를 낸다.
- Unreliability는 112% 증가한다 — 두 배 이상이다. 같은 instruction을 10번 시뮬레이션하면 best와 worst 사이 평균 50점 차이가 벌어진다. 단일턴에서 통하던 “좋은 모델은 안정적이다"라는 직관이 다중턴에서는 깨진다.
저자들이 “Lost in Conversation"이라 이름 붙인 핵심 현상은 이것이다. 모델이 대화 초기에 잘못된 가정으로 한 발 디디면, 이후 새 정보를 받아도 그 가정을 고집한다. 단순 sampling 노이즈가 아니라 경로 의존적 실패다.
추가 발견은 다음과 같다.
- CONCAT은 FULL의 95.1% 성능을 유지한다. shard로 쪼개 다시 이어붙여 한 턴에 주면 거의 떨어지지 않는다. 진짜 원인은 sharding이라는 가공 작업이 아니라 다중턴에 걸친 점진적 정보 노출 그 자체다.
- 2턴만 되어도 LLM은 잃기 시작한다. Gradual sharding 실험에서 instruction을 1·2·3·…·8 shard로 점진 분해했을 때, 2-shard부터 이미 능력 저하와 신뢰성 폭증이 나타난다. 정보를 한 번에 주는 것(1-shard)만이 신뢰성을 보장한다.
- Reasoning 모델(o3, DeepSeek-R1)도 동일하게 잃는다. Test-time compute는 단일턴 능력은 올려도 다중턴 안정성을 키우지 못한다. 오히려 reasoning 모델의 응답이 평균 33% 더 길어 가정 삽입이 증폭된다.
- Temperature=0도 30% 수준의 unreliability를 남긴다. 사용자 시뮬레이터와 어시스턴트의 temperature를 모두 0으로 내려도 SHARDED 조건에서는 상당한 변동이 남는다. 초기 한 토큰의 차이가 이후 턴 전체로 증폭되기 때문이다.
- Episodic 태스크는 잃지 않는다. 문서 단위 번역처럼 매 턴이 독립 subtask로 분해되는 작업은 SHARDED에서도 거의 떨어지지 않는다. 즉 다중턴 자체가 문제가 아니라, “underspecified + 점진 공개"의 결합이 문제다.
왜 잃는가 — 네 가지 실패 패턴
저자들은 Appendix F에서 모델이 잃는 이유를 네 가지로 분석한다.
- Premature answer attempts (조기 답변 시도). 정보가 다 공개되지 않은 초반 턴에서도 모델은 “Sure thing! def function(…)” 식의 완성형 답안을 내놓으려 한다. 빠진 정보는 가정으로 메우는데, 그 가정이 이후 모든 답안을 오염시킨다.
- Over-reliance on previous answers (자기 응답에 과의존). 새 정보를 받아도 이전(틀린) 답을 처음부터 다시 짜지 않고 미세 수정만 시도한다. 회복 실패의 직접적 메커니즘이다.
- Loss-of-middle-turns (중간 턴 망각). 모델은 첫 턴(고수준 의도)과 마지막 턴(직전 요구)에 과도하게 집중하고 그 사이에 끼인 핵심 요구를 누락한다. 긴 컨텍스트의 ’lost in the middle’ 현상이 대화 수준에서도 재현된다.
- Bloated answers (verbosity). 응답이 길수록 사용자 발화에 없는 가정이 더 많이 삽입된다. Reasoning 모델이 더 잘하지 못하는 이유와 직결된다.
대응책은 — 사용자·개발자 권장사항
저자들은 7장 Implications에서 두 부류의 권장사항을 나눈다.
사용자에게:
If time allows, try again.
대화가 산으로 갔다는 느낌이 들면, 같은 채팅 안에서 정정하지 말고 새 세션을 열어 처음부터 동일한 정보를 다시 던지는 것이 효과적이다. Cursor 사용자들이 “whenever they can” 새 채팅을 연다는 일화가 이 권장사항을 뒷받침한다.
Consolidate before retrying.
이미 잃은 대화에서 모델에게 “Please consolidate everything I’ve told you so far"로 요약을 받은 뒤, 그 요약을 새 대화의 첫 메시지로 넘긴다. 사용자가 손으로 만드는 CONCAT 패치다.
LLM 개발자에게: agent framework(LangChain·Autogen 등)로 다중턴 약점을 우회하는 것은 부분 완화에 그친다. RECAP·SNOWBALL이 SHARDED 대비 15–20% 회복하지만 여전히 FULL에 닿지 못한다. 저자들의 call to action은 명확하다 — 다음 세대 LLM은 (1) 단일턴/다중턴 aptitude 동등, (2) U⁹⁰₁₀ < 15의 낮은 unreliability, (3) T=1에서도 안정성, 세 가지를 동시에 만족해야 한다. 신뢰성은 외부 래퍼로 메워지지 않는다.
NLP 연구자에게: 자기 데이터셋의 sharded 버전을 공개하라. Sharding 과정은 1세트 100개 instruction당 약 3시간의 수작업이 든다고 한다. 저자들은 이 과정 자체를 향후 평가 인프라의 일부로 본다.
가장 흥미로운 지점
나는 두 지점에서 멈춰 섰다.
첫째, “좋은 모델은 안정적이다"라는 직관이 다중턴에서 깨진다는 사실이다. 단일턴에서는 aptitude와 reliability가 함께 간다. 다중턴에서는 둘이 분리된다. GPT-4.1이든 Llama-8B든 한 instruction을 10번 풀면 평균 50점 변동이 생긴다. 단일 평균치만 보고 모델을 선정해 온 관행이 실제 운영 환경에서 얼마나 큰 분산을 가리고 있었는지 다시 보게 된다.
둘째, CONCAT 95%와 SHARDED 60%의 격차다. 같은 정보를 한 번에 주면 거의 잃지 않고, 여러 턴에 나눠 주면 크게 잃는다. 이는 곧 사용자 인터페이스 설계의 문제로 옮겨간다. 즉답형 챗봇 UX가 사용자에게 점진적 명세를 유도하는 반면, “충분히 적은 뒤 보내라"는 폼 기반 UX는 모델의 강점을 더 살린다. AI 코딩 에디터가 채팅창과 별개로 “명세 작성” 패널을 분리해 두는 패턴이 왜 잘 동작하는지 이 데이터로 설명된다.
출처
Laban, P., Hayashi, H., Zhou, Y., & Neville, J. (2025). LLMs Get Lost In Multi-Turn Conversation. arXiv preprint arXiv:2505.06120.
원문: https://arxiv.org/abs/2505.06120 데이터: https://huggingface.co/datasets/Microsoft/lost_in_conversation
본 다이제스트의 모든 그림은 원문 논문에서 발췌했다.