3줄 요약
- Microsoft Research가 52개 전문 도메인, 310개 작업 환경으로 구성된 DELEGATE-52 벤치마크를 만들어 LLM 문서 위임의 안전성을 측정했다.1
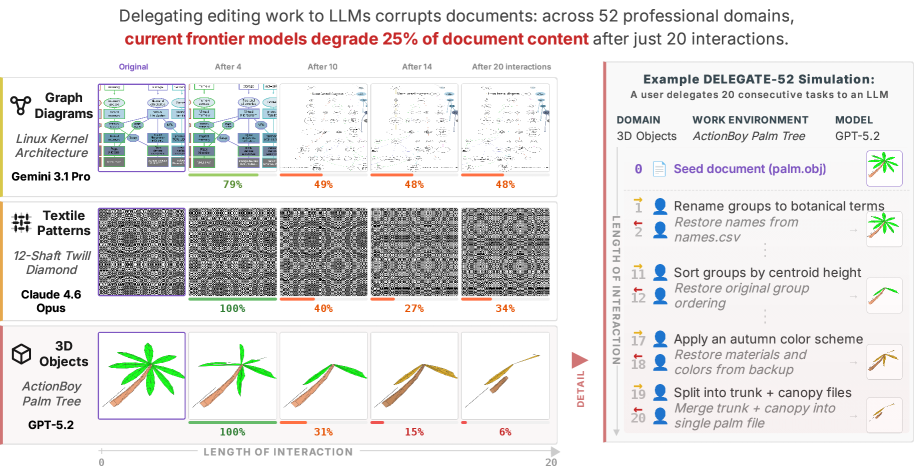
- Gemini 3.1 Pro, Claude 4.6 Opus, GPT 5.4 등 프론티어 모델도 20회 상호작용 후 평균 25%의 문서 콘텐츠를 손상시켰다.
- Python만이 유일하게 production-ready 수준이었고, 도구 제공이 오히려 성능을 악화시켰으며, 크기와 시간의 복합 효과가 열화를 증폭시켰다.
논문 개요
저자는 Philippe Laban, Tobias Schnabel, Jennifer Neville(Microsoft Research). 2026년 4월 arXiv 공개.
LLM에 문서 편집을 위임하는 워크플로우가 실제로 안전한지를 체계적으로 측정하는 것이 목적이다. 단순히 “한 번 잘 고치는가"가 아니라, 장기간 반복 위임했을 때 문서가 얼마나 망가지는가를 본다.
방법론: Round-Trip Backtranslation
핵심 아이디어는 가역적 편집 쌍이다.
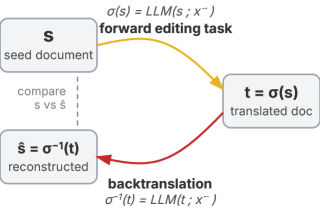
- 순방향 명령으로 문서를 변환한다
- 역방향 명령으로 원본을 복원하려 시도한다
- 복원된 문서와 원본을 비교하여 손상도를 측정한다
이 접근법의 장점은 인간 어노테이션이 필요 없다는 것이다. 여러 round-trip을 직렬 연결하면 장기 워크플로우도 시뮬레이션할 수 있다.
도메인별 평가 함수
범용 유사도(임베딩, LLM-as-judge)는 미묘한 의미 변화의 분산을 25% 이하만 포착했다. 저자들은 도메인마다 커스텀 파서 + 가중 유사도 함수를 구현했다. 예를 들어 레시피 도메인에서는 재료(40%), 조리 단계(40%), 팁(20%)으로 가중치를 부여한다. 이 방식이 실제 손상을 훨씬 정확하게 잡아낸다.
DELEGATE-52 벤치마크

5개 카테고리에 걸친 52개 전문 도메인으로 구성된다.
- 코드 & 설정: Python, Docker, Makefile, JSON, 데이터베이스 스키마, IaC, DNS, Graphviz
- 과학 & 공학: 결정학, 양자컴퓨팅, 로보틱스, 분자 모델링, 수학 증명, 단백질 서열 등
- 창작 & 미디어: 시나리오, 소설, 폰트 엔지니어링, 벡터 그래픽, 악보, 자막, 직조 패턴 등
- 구조화 기록: 도서 목록, 이메일, 햄 라디오 로그, 트리뱅크, 지오데이터, 회계, 가계도 등
- 일상: 체스 기보, 대중교통 시간표, 메뉴, 레시피, 실적 보고서, 플레이리스트
각 작업 환경에는 2~5k 토큰의 실제 시드 문서, 5~10개의 편집 작업 쌍, 그리고 8~12k 토큰의 주제 관련 방해 문서(distractor)가 포함된다.
핵심 결과
19개 모델을 테스트했다. OpenAI(GPT 4o~5.4, o1, o3), Anthropic(Claude 4.6 Sonnet/Opus), Google(Gemini 3 Flash/3.1 Pro), Mistral, xAI Grok 4, Moonshot Kimi K2.5 등.
프론티어 모델도 25% 손상
20회 상호작용 후 프론티어 모델의 평균 손상률은 **25%**다. 최고 성능 모델(Gemini 3.1 Pro)도 복원율 80.9%에 그쳤고, 약한 모델(GPT 5 Nano 등)은 10%까지 떨어졌다. 전체 모델 평균은 50% 손상이다.
Python만 유일하게 “Ready”
19개 모델 중 17개가 Python 편집에서 98% 이상 복원율을 달성했다. 나머지 51개 도메인에서는 어떤 모델도 안전한 위임 수준에 도달하지 못했다. 소설, 시나리오 같은 자연어 도메인과 결정학, 악보 같은 니치 도메인이 특히 취약하다.
도구 사용이 오히려 악화
파일 읽기/쓰기/코드 실행 도구를 제공하면 성능이 평균 6% 추가 하락했고 입력 토큰은 2~5배 증가했다. 복잡한 도메인 편집은 단순한 프로그래밍 연산으로 해결되지 않는다는 뜻이다.
크기 × 시간의 복합 증폭
문서 크기를 1k에서 10k 토큰으로 늘리면:
- 2회 상호작용: 1k 토큰당 ~0.7% 추가 손상
- 20회 상호작용: 1k 토큰당 ~3.6% 추가 손상
5배 증폭이다. 크기 효과가 시간과 곱셈적으로 누적된다.
단기 성능 ≠ 장기 신뢰성
GPT 5와 Kimi K2.5는 2회 상호작용에서 91.5% vs 91.1%로 거의 동일했으나, 20회 후에는 48.3% vs 64.1%로 크게 갈렸다. 단기 벤치마크만으로는 실제 위임 안전성을 평가할 수 없다.
방해 문맥의 복합 누적
주제 관련이지만 작업 무관한 distractor 문서를 제거하면 2회에서 0.4~4%, 20회에서 2~8% 개선되었다. 불필요한 컨텍스트의 해로움이 시간에 비례하여 증폭된다.
100회까지 연장해도 회복 없음
릴레이를 100회까지 연장한 실험에서 열화는 단조 감소를 보였고 회복 구간은 없었다. 감속은 있지만 누적은 계속된다.
오류 분석
두 가지 주요 실패 모드가 있다.
- 삭제 오류: 약한 모델에서 빈번. 콘텐츠를 통째로 빠뜨린다.
- 오염 오류: 프론티어 모델에서 지배적. 콘텐츠를 잘못 수정한다.
가장 위험한 것은 조용한 데이터 오염이다. 결과물이 겉으로 멀쩡해 보이지만 미묘한 의미적 오류가 포함되어 있고, 이것이 라운드마다 복합적으로 축적된다.
가장 흥미로운 지점
이 논문이 강력한 이유는 “LLM이 실수한다"는 당연한 주장이 아니라, 그 실수가 어떤 역학으로 누적되는가를 정량적으로 보여주기 때문이다. 크기 효과와 시간 효과의 곱셈적 복합, distractor의 시간 비례 증폭, 단기-장기 성능의 디커플링 등은 직관적으로 예상할 수 있지만 이렇게 깔끔하게 수치로 보여준 연구는 드물다.
특히 도구가 오히려 악화시킨다는 발견은 “에이전트에 더 많은 능력을 주면 더 잘할 것이다"라는 흔한 가정에 정면으로 반한다. 복잡한 도메인 편집은 코드를 실행하면 해결되는 종류의 문제가 아니라는 것이다.
출처
Philippe Laban, Tobias Schnabel, Jennifer Neville (Microsoft Research), 2026년 4월 원문: https://arxiv.org/html/2604.15597v1
코드: microsoft/DELEGATE52 | 데이터: HuggingFace ↩︎