3줄 요약
- ElevenLabs Research Engineer Angelos Perivolaropoulos가 AI Engineer Europe에서 진행한 81분 핸즈온 워크숍이다. Andrej Karpathy의 nanoGPT에서 영감을 받았다.
- 순수 PyTorch로 GPT-2 기반 decoder-only 모델(10M 파라미터)을 처음부터 구현하고 훈련한다. 토크나이저, 트랜스포머 아키텍처, 학습 루프, 추론 전략을 모두 다룬다.
- 핵심 메시지: GPT-4와 GPT-4o, Gemini 3.0과 3.1의 벤치마크 차이는 모델 아키텍처가 아니라 학습 전략의 차이에서 온다.
발표자
Angelos Perivolaropoulos. ElevenLabs에서 Speech-to-Text 팀을 이끄는 Research Engineer다. Scribe v2 — 퍼블릭 벤치마크 기준 최고 성능 트랜스크립션 모델 — 의 주 개발자이며, 실시간 에이전트용 트랜스크립션 모델 훈련에 주력하고 있다.
토크나이저
이 워크숍에서는 Character-level 토크나이저를 사용한다.
- 어휘 크기: 셰익스피어 데이터셋의 고유 문자 65개. 바이그램 조합은 65² = 4,225개로 학습 가능한 규모다.
- 왜 BPE를 쓰지 않는가: GPT-2의 50K vocab을 쓰면 임베딩만 19M 파라미터로, 10M 파라미터 모델 전체의 3배가 된다. 소규모 데이터에서는 수렴 자체가 불가능하다.
- 트레이드오프: Character-level은 “sky"와 “blue"의 관계를 7개 토큰(“s”,“k”,“y”,“b”,“l”,“u”,“e”)으로 학습해야 하므로 비효율적이다. BPE라면 2개 토큰이면 된다. 하지만 이 규모에서는 최선의 선택이다.
- 실전: BPE(Byte Pair Encoding)가 표준이다. 훈련 데이터의 공통 패턴(“for”, “enumerate” 등)을 토큰으로 병합하는 방식이다.
ElevenLabs에서는 새 TTS 모델 개발 시 토크나이저에 6개월, 아키텍처에 2개월을 투자한다. 토크나이저가 모델의 천장을 결정하기 때문이다.
트랜스포머 아키텍처

GPT-2 기반 decoder-only causal 모델을 순수 PyTorch로 구현한다. 프레임워크나 사전 학습 가중치 없이 처음부터 작성한다. 트랜스포머의 4가지 빌딩 블록 전체가 100줄 미만이다.
| 항목 | 값 |
|---|---|
| Vocab Size | 65 |
| Block Size (context length) | 256 |
| Layers | 6 |
| Attention Heads | 6 |
| Embedding Dim | 384 |
| Total Parameters | 약 10M |
4가지 빌딩 블록:
- Multi-Head Self-Attention — 토큰 간 관계를 파악한다. 각 헤드가 문법, 구두점 등 서로 다른 특성에 집중한다. “sky"와 “blue"의 상관관계를 학습한다.
- MLP (Feed-Forward Network) — 어텐션이 파악한 토큰 관계를 LM Head가 이해할 수 있는 표현으로 변환한다.
- Residual Connection —
x = x + attention(x)패턴. 각 레이어가 입력을 완전히 재구성하지 않고 점진적 변화만 추가한다. - Layer Normalization — 활성화 값이 폭발적으로 커지는 것을 방지한다.
학습 과정과 Loss의 의미
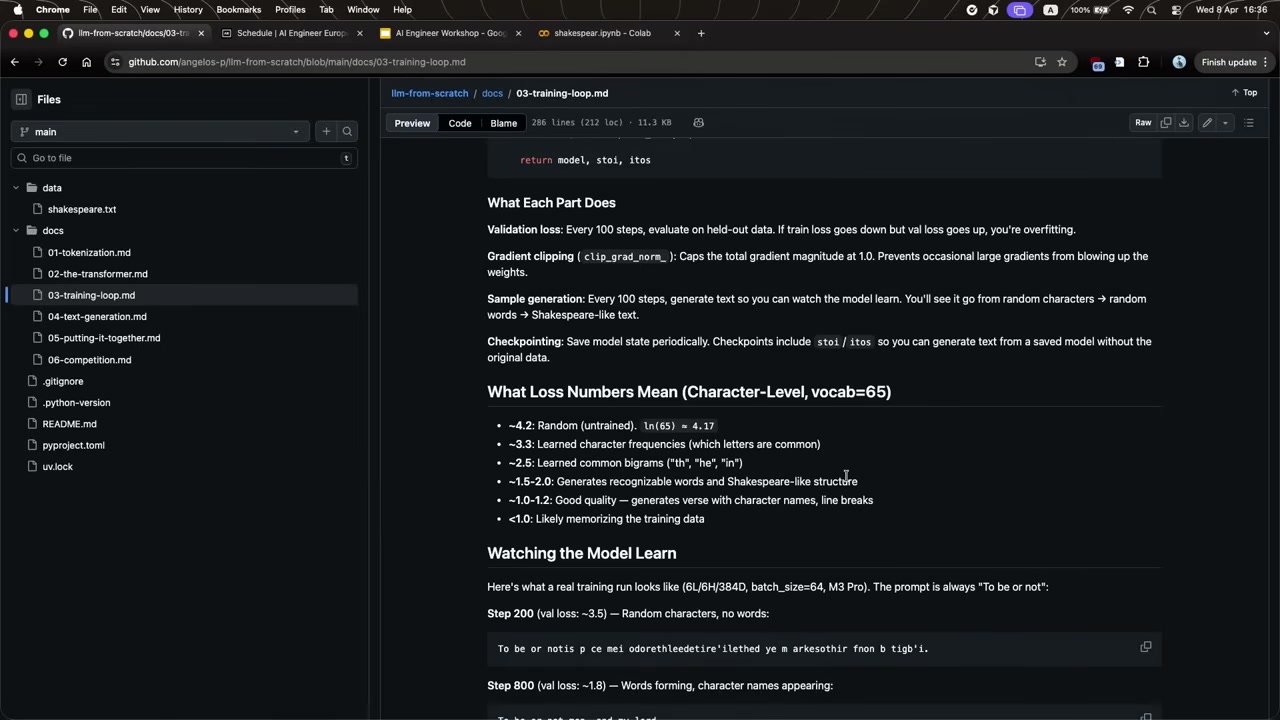
Loss 값이 모델의 학습 단계를 직접적으로 보여준다:
| Loss | 모델 상태 | 출력 특성 |
|---|---|---|
| 약 4.2 | 완전 랜덤 | ln(65) ≈ 4.17. 아무것도 모르는 초기 상태 |
| 약 3.3 | 문자 빈도 학습 | 어떤 글자가 자주 나오는지 파악 |
| 약 2.5 | 바이그램 학습 | “th”, “he”, “in” 같은 일반적 조합 |
| 약 1.5 | 단어 생성 | 인식 가능한 단어와 셰익스피어풍 구조 |
| 약 1.0 | 양호한 품질 | 캐릭터 이름, 운율, 줄바꿈 구사 |
| 1.0 미만 | 과적합 시작 | 훈련 데이터를 외우기 시작. 창의성 감소 |
학습 루프 핵심 요소
- Learning Rate Schedule — 100 step 워밍업 후 코사인 감쇠. 높은 학습률로 넓게 탐색한 뒤, 점점 줄여서 정밀 조정한다.
- AdamW Optimizer — Weight Decay가 포함된 옵티마이저.
- Validation Loss — 모델이 한 번도 보지 못한 데이터로 측정한다. 과적합 감지의 핵심 지표다.
- Gradient Clipping —
clip_grad_norm_()으로 기울기 폭발을 방지한다. - 체크포인트 — 1000 step마다 저장. 언제든 재개할 수 있다.
이 모델의 최적 학습 지점은 약 2,400 step이다. 이후 Validation Loss가 올라가기 시작하면 과적합 신호다.
텍스트 생성 전략

- Greedy Decoding — 항상 가장 확률 높은 토큰을 선택한다. 반복적이고 지루한 출력이 나온다.
- Temperature Scaling — logits를 temperature로 나눠 확률 분포를 조절한다. T→0이면 greedy, T=1.0이면 원래 분포, T>1.0이면 더 랜덤하다. 최적 구간은 0.7~0.8이다.
- Top-k Sampling — 상위 k개 토큰만 남기고 나머지를 제거한다. 극단적으로 낮은 확률의 노이즈 토큰을 차단한다. Character-level 모델(vocab=65)에서는 k=8 정도가 적절하다.
가장 흥미로운 지점
발표자가 워크숍 후반에 한 말이 가장 인상적이다: “GPT-4와 GPT-4o의 벤치마크 차이, Gemini 3.0과 3.1의 성능 2배 차이는 모델 아키텍처의 변화가 아니라 학습 전략의 차이에서 온 것이다.” 트랜스포머 전체 구현이 100줄 미만이라는 사실과 함께 놓고 보면 — 아키텍처보다 학습 루프 설계(LR 스케줄링, 데이터 구성, 배치 전략)가 성능을 결정하는 시대에 들어섰다는 것이다.
또 하나, ElevenLabs가 토크나이저에 6개월, 아키텍처에 2개월을 투자한다는 현업 증언도 눈에 띈다. 대부분의 관심이 모델 구조에 쏠려 있는 동안, 정작 모델의 천장을 결정하는 것은 토크나이저일 수 있다.
16GB RAM 노트북이면 따라할 수 있다.
출처
Angelos Perivolaropoulos (ElevenLabs, Research Engineer, STT 팀 리드) · AI Engineer Europe Workshop 원문: https://www.youtube.com/watch?v=UsB70Tf5zcE 코드: https://github.com/angelos-p/llm-from-scratch