3줄 요약
- David Klindt·Yann LeCun·Randall Balestriero가 2026년 공개한 글(논문 arXiv:2605.26379). 르쿤이 LLM의 대안으로 밀어 온 자기지도 학습기 LeJEPA가, 그저 그럴듯한 표현이 아니라 세계의 진짜 구조를 배우는지를 수학으로 따졌다.
- 결론: LeJEPA는 카메라가 본 복잡한 이미지에서 세계의 상태를 정하는 ‘진짜 좌표(숨은 변수)‘를 거의 그대로(방향만 돌아간 채) 되찾는다. 그리고 이게 가능한 건 그 좌표들이 종 모양 분포(가우시안)일 때 뿐이다.
- 그 좌표를 되찾을 수 있으면, 그 공간에서 세운 계획이 실제 세계의 최적 계획과 정확히 같아진다. 네 개의 핵심 정리를 사람이 아니라 증명 검사기(Lean 4)가 한 줄씩 검증했다.
JEPA는 정말 LLM의 대안인가
LLM은 다음 단어(또는 픽셀)를 글자 그대로 맞히려 한다. 이 방식은 자잘한 디테일까지 전부 예측하느라 정작 ‘무슨 일이 벌어지는가’라는 큰 그림을 놓치기 쉽다. 르쿤의 JEPA(Joint-Embedding Predictive Architecture)는 발상이 다르다 — 원본을 그대로 그려내는 대신, 요약된 의미 공간에서 “다음 장면이 대충 어떻게 될지"를 맞힌다. 비유하자면 영화의 다음 프레임을 픽셀 단위로 그리는 대신 “주인공이 문으로 다가간다” 정도의 줄거리로 예측하는 셈이다. 픽셀을 버리고 구조를 잡자는 것이다.
같은 의심은 LLM 진영 밖에서도 들린다. geohot은 최근 글 Eternal Sloptember에서 “world model(세계의 작동 모델) 없는 LLM은 진짜 프로그래밍 에이전트가 될 수 없다"고 결론지었다.
원 논문 LeJEPA(Balestriero & LeCun, 2025-11, arXiv:2511.08544)는 이 청사진을 실용 단계로 끌어내렸다. 핵심은, JEPA가 만드는 벡터들이 따라야 할 가장 좋은 분포가 등방 가우시안(모든 방향으로 고르게 퍼진 종 모양 구름)임을 밝히고, 그 모양을 강제하는 장치 SIGReg(Sketched Isotropic Gaussian Regularization)를 붙인 것이다. 교사-학생 모델이나 gradient 차단 같은 잔기술 없이, 조절값(하이퍼파라미터) 하나·약 50줄 코드로 ImageNet-1k에서 ViT-H/14 기준 79%를 찍었다.
나는 지난 글 안정화의 축이 이동한다 — 구조에서 분포 제약으로에서 SIGReg의 의미를 “표현 학습의 붕괴를 막는 일이 네트워크 구조 설계에서 벡터 분포에 거는 제약으로 옮겨갔다"로 정리했다. 이 글은 거기서 자연스럽게 따라오는 다음 질문에 답한다 — 왜 하필 종 모양(가우시안)인가, 그 제약이 우리에게 무엇을 사주는가.
먼저, 등장인물 셋
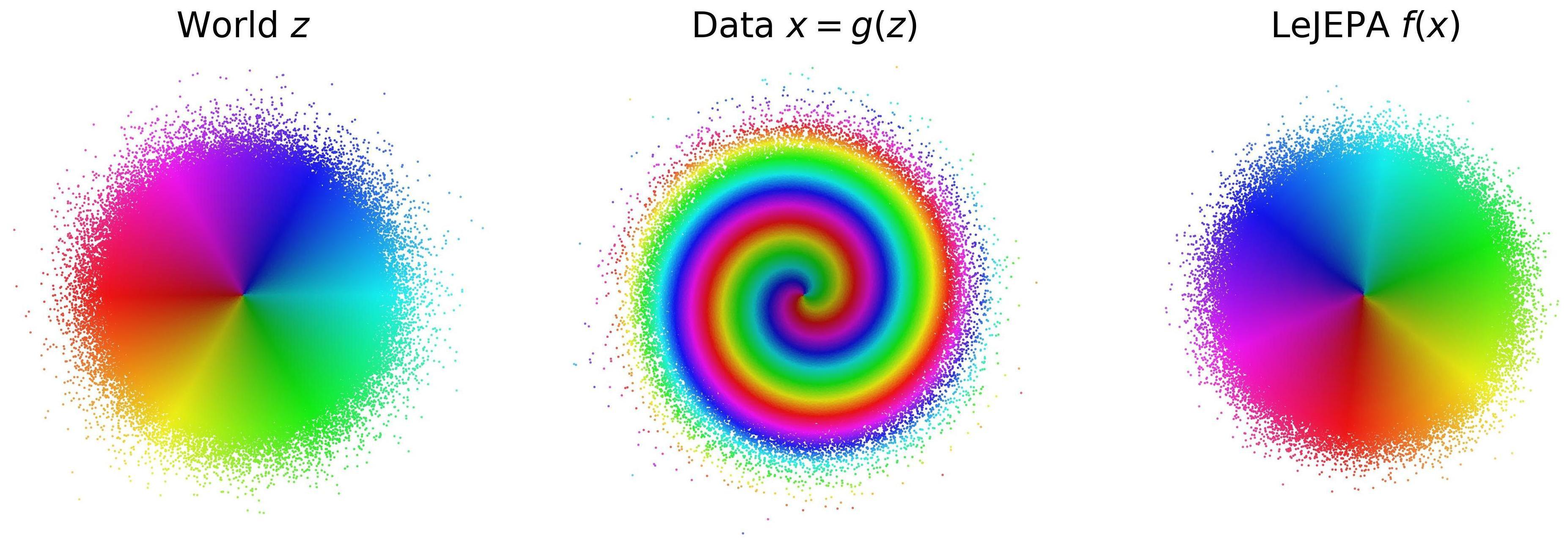
본론에 들어가기 전에 그림 한 장으로 무대를 정리해 두자.
 (좌) 세계에는 그 상태를 정하는 ‘숨은 변수(진짜 좌표)‘가 있다. (중) 알 수 없는 과정이 그것을 우리가 보는 복잡한 데이터로 뒤섞는다. (우) LeJEPA는 그 좌표를 방향만 돌아간 채로 되찾는다 — 이것이 유일한 최적해임을 증명한다. 출처: klindtlab.github.io/lejepa-identifiability1234
(좌) 세계에는 그 상태를 정하는 ‘숨은 변수(진짜 좌표)‘가 있다. (중) 알 수 없는 과정이 그것을 우리가 보는 복잡한 데이터로 뒤섞는다. (우) LeJEPA는 그 좌표를 방향만 돌아간 채로 되찾는다 — 이것이 유일한 최적해임을 증명한다. 출처: klindtlab.github.io/lejepa-identifiability1234
① 세계 — 숨은 변수(진짜 좌표). 세계가 실제로 움직이는 데는 몇 개의 핵심 변수면 충분하다. 로봇 팔이라면 관절 각도 두세 개. 이 글은 그것을 잠재변수 $z$라 부른다. 이 변수들이 만드는 공간이 곧 그 세계에서 일어날 수 있는 일들이 사는 공간이다 — 공간의 한 점은 ‘지금 세계의 상태’, 점들 사이의 이동은 ‘그 세계에서 유효한 조작’이다. 우리는 이 변수를 직접 보지 못한다. 대신 그것이 복잡하게 뒤섞여 나온 결과 — 카메라 이미지 같은 관측 $x$ — 만 본다. 수학으로는 알 수 없는 뒤섞기 함수 $g$가 있어 $x = g(z)$다. 또 이 변수는 시간에 따라 조금씩 변한다($z'$는 $z$의 다음 순간).
② 학습자 — 인코더. 인코더 $h$는 이미지 한 장을 받아 숫자 묶음(벡터) 하나로 바꾸는 함수다. LeJEPA는 이 인코더에게 딱 두 가지를 시킨다.
- (정렬) 연달아 일어난 두 순간은 비슷한 벡터로 보내라. 방금 전과 지금이 닮았으니 표현도 닮아야 한다.
- (가우시안 제약) 전체 벡터들을 모아 놓으면 종 모양 구름이 되게 하라. 이걸 실전에서 강제하는 장치가 SIGReg다.
왜 두 번째가 필요할까? 제약이 없으면 인코더가 게을러진다. 모든 입력을 똑같은 한 점으로 보내버리면 “연달은 순간은 가깝다"는 첫 조건이 공짜로 만족되기 때문이다. 이렇게 표현이 한 점으로 쪼그라드는 사고를 ‘붕괴(collapse)‘라 하는데, “고르게 퍼진 종 모양이 되라"는 두 번째 요구가 바로 이 붕괴를 막는다.
거꾸로, ‘종 모양으로 만들어라’만으로도 부족하다. 입력을 통째로 무시하고 난수만 종 모양으로 뿌려도 이 조건은 통과하지만, 그건 세계에 대해 아무것도 배우지 못한 껍데기다. 종 모양으로 펼치는 방법은 무수히 많고, 그중 세계를 비추는 것은 극소수다. 그래서 핵심은 두 조건을 함께 거는 데 있다 — ‘시간상 이웃은 가깝게’(정렬)가 그 무수한 종 모양 배치 가운데 세계의 진짜 좌표와 맞는 단 하나(회전 차이)를 골라낸다. 한쪽은 ‘모양’을, 다른 쪽은 ‘어느 배치인가’를 정하니, 둘이 만나야 비로소 올바른 공간이 결정된다.
말로 푼 두 요구를 식 하나로 적으면 이렇다(겁먹지 않아도 된다, 위 두 줄을 그대로 옮긴 것이다).
$$\min_h\ \underbrace{\mathbb{E}\big[\,\lVert h(z') - h(z)\rVert^2\,\big]}_{\text{연달은 두 순간을 가깝게(정렬)}} \quad \text{s.t.}\quad \underbrace{h(z) \sim \mathcal{N}(0, I_n)}_{\text{전체는 종 모양(가우시안)}}.$$③ 식별가능성 — 진짜를 되찾았는가. 인코더가 무언가를 배우긴 했는데, 그게 세계의 진짜 좌표인지 아니면 알아볼 수 없게 헝클어진 딴것인지가 문제다. 표현이 진짜 자유도를 뒤섞어 버리면 그 위에서 세운 계획은 믿을 수 없다. 선형 식별가능성이란, 학습된 표현이 진짜 좌표를 방향만 돌려놓은(회전시킨) 형태로 되찾았다는 뜻이다. 지도를 손에 들고 빙 돌려 보는 것과 같다 — 방향은 바뀌어도 두 도시 사이 거리와 모양은 그대로다. 그러니 회전만큼의 차이는 사실상 완벽한 복원이다.
네 개의 정리
각 정리를 말로 먼저, 형식은 그 뒤에 짧게 붙인다.
정리 1 — 되찾는다 (선형 식별가능성). 세계의 숨은 변수가 종 모양으로 분포해 있다면, 위 레시피를 가장 잘 푸는 인코더는 ‘진짜 좌표를 회전시킨 것’ 딱 하나뿐이다. 즉 뒤섞기를 깨끗이 풀어낸다. 직관은 이렇다 — 표현을 비틀면(비선형으로 만들면) 연달은 두 순간을 가깝게 두는 데 오히려 손해다. 그래서 최적해는 비틀지 않은 ‘곧은’(선형) 변환에 머문다. 원 논문은 이걸 Hermite 다항식이라는 도구로 엄밀히 보였다. (형식: 어떤 회전행렬 $Q$에 대해 $h(z) = Qz$.)
정리 2 — 종 모양만 된다 (가우시안 유일성). 이 깨끗한 복원이 가능한 변수 분포는 종 모양(가우시안) 하나뿐이다. 변수가 다른 모양으로 분포해 있으면 레시피가 깨진다. 이게 이 글의 핵심 한 방이다 — SIGReg가 굳이 종 모양을 노린 것이 설계자의 취향이 아니라, 복원이 가능한 유일한 정답이었다는 뜻이기 때문이다.
정리 3 — 살짝 어긋나도 괜찮다 (근사 식별가능성). 현실에서 레시피를 한 치 오차 없이 맞추긴 어렵다. 다행히 두 조건이 조금($\varepsilon$, $\delta$만큼) 어긋나면 복원도 조금 어긋날 뿐, 갑자기 와르르 무너지지 않는다. 오차가 얼마까지 커질 수 있는지도 식으로 한계가 정해진다.
정리 4 — 그러면 계획을 세울 수 있다 (최적 잠재공간 플래닝). 좌표를 회전 차이로 되찾았다면, 그 공간에서 “어떻게 움직일지” 계획을 세워도 진짜 세계에서 세운 최적 계획과 똑같이 좋다. 놀라운 점은, 돌아간 방향을 굳이 되돌리지 않아도 된다는 것이다. 돌려 든 지도로도 최단 경로는 똑같이 찾을 수 있는 것과 같다.
네 결과 모두 Lean 4 + Mathlib로 형식 검증됐다. Lean 4는 증명을 한 줄씩 기계적으로 검사하는 소프트웨어다. 8,032개의 검증 항목이 통과했고, ‘증명 못한 자리’를 비워 두는 표시인 sorry가 0개다 — 손으로 얼버무린 빈틈이 없다는 뜻이다. (아직 Mathlib에 없어 공리로 가져다 쓴 부분은 Hermite 다항식 같은 표준 배경 정리뿐이다.)
실험 검증
이론만 있는 게 아니라, 작은 장난감부터 픽셀 로봇까지 실제로 돌려 봤다.
2D 장난감. 숨은 변수 2개짜리 세계를 여러 방식(나선·전단·RealNVP)으로 뒤섞은 뒤 인코더에게 풀게 했다. 네 경우 모두 뒤섞인 점구름을 회전된 원본으로 되돌렸다(정리 1과 일치). 눈으로 바로 확인되는 결과다.
 각 패널 왼쪽은 뒤섞인 관측, 오른쪽은 인코더가 되찾은 표현. 방향만 돌리면 원본과 같은 모양이다.
각 패널 왼쪽은 뒤섞인 관측, 오른쪽은 인코더가 되찾은 표현. 방향만 돌리면 원본과 같은 모양이다.
고차원으로 키우기. 숨은 변수의 개수 $N$을 2개에서 1024개까지 늘려도 SIGReg는 복원 정확도(1에 가까울수록 완벽)를 $R^2 > 0.999$로 유지했다. 대조군 InfoNCE는 변수가 많아질수록 무너진다.
| 변수 수 $N$ | SIGReg 복원도 | InfoNCE 복원도 |
|---|---|---|
| 2 | 0.999998 | 0.950961 |
| 64 | 0.999966 | 0.648496 |
| 1024 | 0.999561 | 0.720241 |
분포 모양 바꿔보기. 숨은 변수의 분포 모양을 무거운 꼬리에서 종 모양($\alpha = 2$)을 거쳐 평평한 모양까지 바꿔가며 실험하니, 복원 정확도가 정확히 종 모양에서 가장 뾰족하게 정점을 찍었다 — 정리 2(종 모양만 된다)를 눈으로 보여준 셈이다.
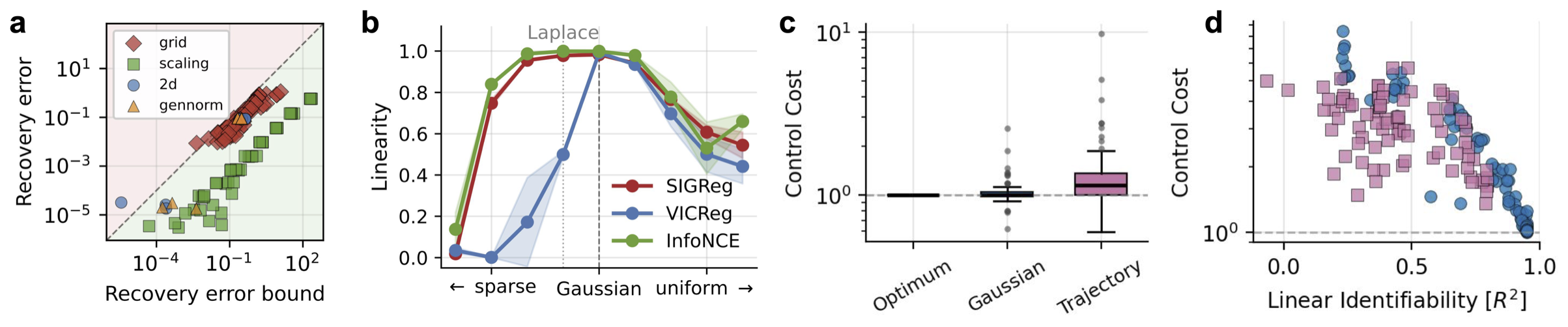 (a) 정리 3의 오차 한계가 모든 실험에서 지켜진다. (b) 복원 정확도가 종 모양($\alpha = 2$)에서 정점(정리 2). (c)(d) 복원이 정확할수록 제어(움직임) 비용이 낮아진다(정리 4).
(a) 정리 3의 오차 한계가 모든 실험에서 지켜진다. (b) 복원 정확도가 종 모양($\alpha = 2$)에서 정점(정리 2). (c)(d) 복원이 정확할수록 제어(움직임) 비용이 낮아진다(정리 4).
픽셀로 로봇 제어. DMC Reacher라는 가상 로봇 팔을 64×64 화면으로만 보고 인코더를 학습시킨 뒤, 그 표현 공간에서 시작 지점과 목표 지점을 직선으로 이어 계획을 세웠다. 좌표를 제대로 되찾은 인코더의 계획은 정답(oracle)을 거의 그대로 따라갔지만, 그러지 못한 인코더는 길을 벗어났다. 계획의 품질이 복원 정확도를 그대로 따라간 것이다(정리 4).
 위: 정답(관절 공간 직선). 가운데: 잘 배운 인코더 — 정답을 바짝 따라간다. 아래: 못 배운 인코더 — 좌표를 제대로 못 되찾아 길을 벗어난다.
위: 정답(관절 공간 직선). 가운데: 잘 배운 인코더 — 정답을 바짝 따라간다. 아래: 못 배운 인코더 — 좌표를 제대로 못 되찾아 길을 벗어난다.
가장 흥미로운 지점
두 가지가 인상 깊었다.
첫째, 종 모양이 우연한 선택이 아니라 수학적 필연이라는 점이다. 원 LeJEPA 논문은 “종 모양이 가장 쓸모 있는 분포"라고 말했는데, 이 글은 한 걸음 더 들어가 “이런 종류의 세계에서는 종 모양만이 세계를 되찾게 해 준다"고 증명한다(정리 2). 잘 되는 줄 알고 쓰던 설계가, 알고 보니 유일한 정답이었다는 뒷받침이다.
둘째, ‘표현이 좋다’에서 ‘계획이 가능하다’로 넘어가는 다리(정리 4)다. 보통 식별가능성은 표현 학습의 예쁜 목표쯤으로 여겨지는데, 이 글은 그것이 곧 최적의 행동을 고를 수 있는 충분조건임을 보인다. LLM이 세계를 진짜로 이해하지 않고도 그럴듯한 다음 토큰을 잘 잇는 것과, 표현 공간에서 실제로 최적 경로를 그려내는 것 — 그 사이의 차이를 이 정리가 또렷이 가른다. 르쿤이 말하는 ‘월드 모델’이 왜 단순한 표현과 다른지를 수학으로 보여준 대목이다.
다만 가장 큰 가정을 분명히 해 두자. 이 정리들은 세계의 숨은 변수가 종 모양으로 분포하고, 비교적 얌전하게(매 순간 조금씩, 잡음을 더하며) 변하는 세계를 전제한다. ‘세계가 정말 그러한가’가 이 글의 가장 약한 고리다. 오해 하나는 풀어 두자 — 이 조건은 날것의 관측(픽셀)이 아니라 그 아래 숨은 변수에 걸린다. 픽셀 자체는 전혀 종 모양이 아니어도 된다. 진짜 부담은 동역학이 얌전한 바로 그 좌표계에서 변수들이 종 모양이어야 한다는, 두 요구를 한 좌표계에서 동시에 만족시키는 데 있다. 그나마 정리 3이 보장하듯 세계가 근사적으로만 가우시안이어도 복원은 갑자기 무너지지 않고 그만큼만 어긋나며, 실제로 픽셀 기반 로봇 제어에서 통했다. 반대로 무거운 꼬리(드문 극단이 잦은)나 불연속·기호적 구조가 지배하는 세계라면 이 가정은 잘 맞지 않을 수 있다 — 흥미롭게도 이는 연속적인 물리 세계(시각·제어)와 이산적 언어(LLM의 영역)가 갈리는 지점과 겹친다.
갈 길 — 주춧돌이지 완공이 아니다
솔직히 말하면, 이 결과가 곧 ‘월드 모델을 풀었다’는 뜻은 아니다. 오히려 거대한 공정에 증명된 주춧돌 하나를 놓은 쪽에 가깝다. 이 정리가 아직 닿지 못한 곳을 늘어놓으면 그 거리가 제법 아득하다.
- 가정의 폭. 증명은 정상·가법잡음으로 매끄럽게 흐르는 연속 세계를 가정한다. 현실은 규칙이 시간에 따라 바뀌고(비정상), 잡음이 곱해지고, 사건이 불쑥 끊기고(불연속), 일부만 관측되며, 여러 물체가 얽힌 계층 구조다. 정리 3은 근사만 메울 뿐 이 간극을 없애지 못한다.
- 규모. 검증은 잠재 1024차원과 단순한 Reacher 팔까지다. 긴 영상, 여러 물체, 긴 시간 지평의 복잡한 동역학은 아직 손대지 않았다.
- 행동과 보상. 최적 계획 보장은 비용이 미리 알려진 유한 지평 제어에 한한다. 미지의 보상, 탐험, 장기 신용 할당은 통째로 다른 난제다.
- 동역학 학습 그 자체. 여기선 좌표가 워낙 좋아 직선만 그어도 계획이 됐다. 그러나 풍부한 세계의 변화를 실제로 학습해 일반화하는 일은 그것대로 열린 문제다.
그럼에도 이 한 장의 값어치는 분명하다. 이 분야가 넓지만 불확실한 주장으로 붐비는데, 이건 드물게 좁지만 확실한 결과다. 이상화된 세계에서일지언정 ‘이 레시피는 반드시 통한다’를 증명 검사기로 확정 지었다 — 남이 그 위에 안심하고 쌓아 올릴 디딤돌이라는 뜻이다. ‘드디어 모습을 드러냈다’는 말이 맞다면, 드러난 것은 완성된 월드 모델이 아니라 그것이 가능하다는 증명이다.
출처
David Klindt(Cold Spring Harbor Laboratory), Yann LeCun(New York University), Randall Balestriero(Brown University), “When Does LeJEPA Learn a World Model?” (2026), arXiv:2605.26379.
원 LeJEPA 논문: Randall Balestriero, Yann LeCun, “LeJEPA: Provable and Scalable Self-Supervised Learning Without the Heuristics” (2025-11), arXiv:2511.08544.