3줄 요약
- Mnilax가 2026년 5월 X에 발행한 글로, Andrej Karpathy의 2026년 1월 불평에서 시작해 Forrest Chang이 4규칙으로 정리한 CLAUDE.md 템플릿을 30개 코드베이스 6주간 직접 테스트하고 8규칙을 더한 실험 보고다.
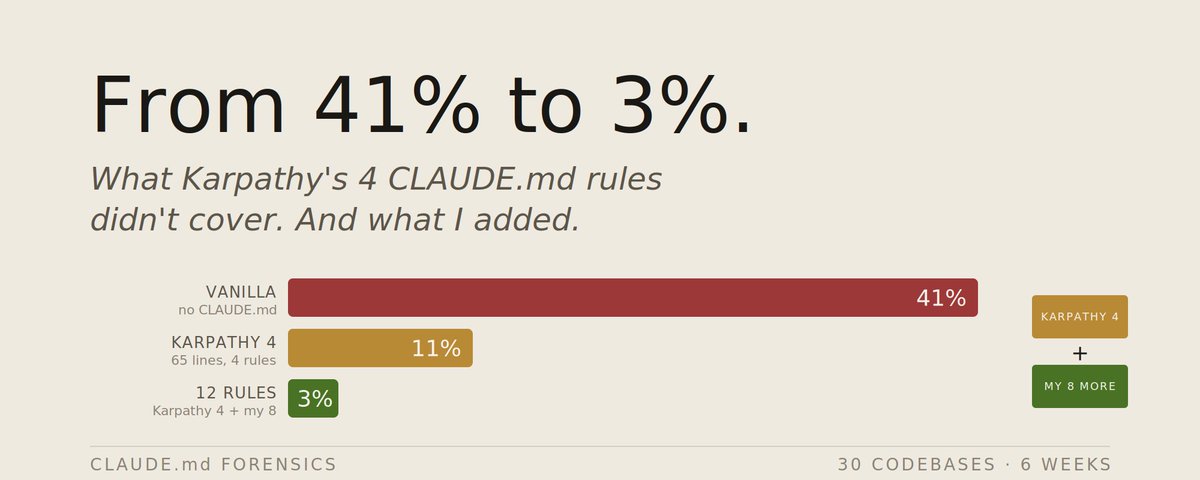
- 핵심 발견은 두 가지다. 4규칙으로 실수율이 41%에서 11%로, 12규칙으로 3%까지 떨어지지만, 규칙 수가 14개를 넘으면 컴플라이언스가 76%에서 52%로 무너진다.
- 결론은 분명하다. CLAUDE.md는 위시리스트가 아니라 관찰된 실수의 닫힌 목록이며, 자신의 실패 모드에 맞춘 6규칙이 일반 12규칙보다 낫다.
자료의 출발점
2026년 1월, Andrej Karpathy가 X에 Claude의 코드 작성 방식을 비판하는 스레드를 올렸다. 세 가지 실패 모드를 지목했다.1
- 조용한 잘못된 가정
- 과도한 복잡화
- 건드리지 말아야 할 인접 코드에 대한 직교적 손상
Forrest Chang이 이 불평을 4가지 행동 규칙으로 묶어 단일 CLAUDE.md 파일로 GitHub에 올렸다. 첫날 5,828 스타, 2주 만에 60,000 북마크, 현재 120,000 스타 — 2026년 가장 빠르게 성장한 단일 파일 리포다.2
저자 Mnilax는 이 템플릿을 30개 코드베이스에서 6주간 직접 시험했다. 결과는 Karpathy 4규칙은 작동하지만, 작성된 시점(2026년 1월, 자동완성 스타일 코딩)의 실패 모드만 다룬다는 것이었다. 5월 시점의 에이전트 충돌·훅 캐스케이드·스킬 로딩 충돌·다단계 워크플로우 문제는 다루지 않는다. 그래서 8규칙을 더했다.
왜 CLAUDE.md가 중요한가
Anthropic 공식 문서는 명시한다. CLAUDE.md는 권고이며, Claude는 약 80%의 확률로 따른다. 200줄을 넘으면 중요한 규칙이 노이즈에 묻혀 컴플라이언스가 급락한다.
저자는 대부분의 개발자가 셋 중 하나에 빠진다고 본다.
- 모든 선호를 쏟아부어 4,000+ 토큰으로 부풀린다 → 컴플라이언스 30%로 떨어진다.
- 아예 안 쓰고 매번 프롬프트를 다시 입력한다 → 5배 토큰 낭비, 세션 간 일관성 없음.
- 템플릿을 한 번 복사하고 잊는다 → 2주는 작동하지만 코드베이스가 변하면 조용히 망가진다.
Karpathy 템플릿은 65줄·4규칙으로 이 문제를 해결했다. 그것이 바닥이다. 천장은 8규칙을 더해 1월의 코드 작성 실수뿐 아니라 5월의 에이전트 운영 문제까지 덮는 데 있다.
원본 4규칙 (Karpathy/Forrest Chang)
| 규칙 | 핵심 |
|---|---|
| Rule 1 — Think Before Coding | 가정을 명시한다. 트레이드오프를 표면화한다. 추측 전에 묻는다. 더 단순한 길이 있으면 밀어붙여 반박한다. |
| Rule 2 — Simplicity First | 문제를 푸는 최소 코드만 쓴다. 투기적 기능, 일회용 추상화 금지. 시니어가 과하다고 부를 만하면 단순화한다. |
| Rule 3 — Surgical Changes | 건드려야 하는 것만 건드린다. 인접 코드·주석·서식을 “개선"하지 않는다. 망가지지 않은 것을 리팩터링하지 않는다. |
| Rule 4 — Goal-Driven Execution | 성공 기준을 정의한다. 검증될 때까지 루프한다. 단계를 지시하지 말고 성공이 어떤 모습인지를 알려준 뒤 모델이 스스로 반복하게 한다. |
이 4가지가 비감독 Claude Code 세션 실패 모드의 약 40%를 닫는다. 나머지 60%는 아래의 공백에 있다.
추가된 8규칙
각 규칙은 Karpathy 4규칙으로 부족했던 실제 순간에서 나왔다. 저자는 모든 규칙에 그 순간을 함께 적었다.
Rule 5 — 모델에게 비언어적 작업을 시키지 마라
503 에러에서 재시도할지 결정하는 코드를 Claude에 맡겼더니, 2주는 잘 돌다가 모델이 요청 본문을 의사결정의 맥락으로 읽기 시작하면서 재시도 정책이 무작위가 되었다. 프롬프트가 무작위이니 정책도 무작위였다.
결정론적이어야 할 작업은 코드에 두고, 추론이 필요한 작업만 모델에 둔다. 토큰당 0.003달러의 깜빡거리는 if-else를 만들지 않는다.
Rule 6 — 하드 토큰 예산. 예외 없다.
한 디버깅 세션이 90분간 돌았다. 모델은 같은 8KB 에러 메시지를 두고 즐겁게 반복했고, 자기가 이미 시도해 거부당한 수정을 40개 메시지 뒤에 다시 제안했다. 토큰 예산이 있었다면 12분에 끊었을 것이다.
CLAUDE.md에 예산이 없으면 백지수표다. 모델은 스스로 멈추지 않는다.
Rule 7 — 충돌을 평균내지 말고 표면화하라
한 코드베이스에 두 가지 에러 핸들링 패턴이 있었다. async/await + try/catch와 글로벌 에러 바운더리. Claude는 두 패턴을 모두 적용하는 새 코드를 짰다. 에러 핸들러가 두 배가 되었다. 에러가 두 번 삼켜지는 이유를 찾는 데 30분 걸렸다.
코드베이스 내부 충돌은 자동 화해 대상이 아니라 드러내야 할 사실이다.
Rule 8 — 쓰기 전에 읽어라
Claude는 30줄 옆에 이미 같은 일을 하는 함수가 있는 줄 모르고 새 함수를 추가했다. 임포트 순서 때문에 새 함수가 우선되었고, 6개월간 진실의 원천이었던 기존 함수가 덮였다.
Karpathy의 Surgical Changes는 인접 코드를 건드리지 마라고만 말한다. 이해하라고는 말하지 않는다. Surgical의 전제는 사전 독해다.
Rule 9 — 테스트는 선택사항이 아니지만, 목표도 아니다
Claude가 인증 함수에 테스트 12개를 짰고 모두 통과했다. 프로덕션에서 인증은 망가져 있었다. 테스트는 함수가 무언가를 반환한다는 것만 검사하고 있었다. 함수는 상수를 반환했기 때문에 통과한 것이다.
테스트의 통과가 아니라 옳음의 검증이 기준이어야 한다.
Rule 10 — 장기 작업에는 체크포인트가 필요하다
6단계 리팩터의 4단계에서 잘못된 길로 빠졌는데, 그 위에 5·6단계가 더 쌓이고 나서야 발견하면 풀어내는 것이 처음부터 다시 하는 것보다 비싸진다.
Karpathy 템플릿은 한 번의 상호작용을 가정한다. 다파일·다세션·다단계 작업에서는 명시적 체크포인트가 없으면 한 번의 오판이 모든 진척을 삼킨다.
Rule 11 — 컨벤션이 새로움을 이긴다
Claude가 클래스 컴포넌트 코드베이스에 React Hooks를 도입했다. 동작은 했다. componentDidMount를 가정하던 테스트 패턴이 깨졌고, 반나절을 들여 도로 되돌려야 했다.
모델의 “더 나은” 방식이 기존 방식과 공존하는 순간, 두 패턴 모두보다 못한 상태가 된다.
Rule 12 — 조용히 실패하지 말고 시끄럽게
Claude가 “마이그레이션 성공"이라 보고한 작업이 제약 조건을 어긴 14%의 레코드를 조용히 건너뛰었고, 11일 뒤 리포트가 이상해지면서야 발견되었다. 건너뜀은 로그에 있었지만 표면화되지 않았다.
가장 비싼 실패는 성공처럼 보이는 실패다. 함수가 “동작"하지만 잘못된 값을 반환하고, 테스트가 “통과"하지만 단언 자체가 틀린 경우들 — 모델은 실패를 표면으로 올리도록 명시적으로 요구해야 한다.
핵심 수치
| 구성 | 실수율 | 컴플라이언스 |
|---|---|---|
| Vanilla (CLAUDE.md 없음) | 41% | — |
| Karpathy 4 (65줄·4규칙) | 11% | 78% |
| 12 Rules (Karpathy 4 + 8) | 3% | 76% |
| 18 Rules | — | 52% (14개 초과 시 폭락) |
저자가 가장 흥미롭게 본 결과는 4 → 12로 늘려도 컴플라이언스가 78% → 76%로 거의 변하지 않으면서 실수율이 8포인트 더 내려간 것이다. 새 규칙은 기존 4규칙과 같은 주의 예산을 두고 경쟁하지 않고, 다른 실패 모드를 다룬다는 의미다.3
다만 14개를 넘기는 순간 76% → 52%로 무너진다. 200줄 천장은 실재한다.
Karpathy 템플릿의 사각지대 4곳
저자가 직접 짚은 곳들이다.
- 장기 에이전트 작업. Karpathy 규칙은 코드를 쓰는 순간을 겨냥한다. 다단계 파이프라인을 도는 동안에 대해서는 침묵한다. 예산 규칙도, 체크포인트 규칙도, 시끄러운 실패 규칙도 없다. 파이프라인은 드리프트한다.
- 다중 코드베이스 일관성. “기존 스타일에 맞춰라"는 하나의 스타일을 가정한다. 12개 서비스를 가진 모노레포에서는 어떤 스타일을 골라야 할지 규칙이 말해주지 않는다. 모델은 무작위로 고르거나 평균낸다.
- 테스트 품질. Goal-Driven Execution은 “테스트 통과"를 성공으로 친다. 테스트가 의미 있어야 한다고는 말하지 않는다. 결과는 아무 쓸모없지만 모델을 자신감 있게 만드는 테스트다.
- 프로덕션 vs 프로토타입. 프로덕션 코드를 과도한 엔지니어링에서 보호하는 같은 규칙이, 100줄짜리 투기적 스캐폴딩이 합법적으로 필요한 초기 프로토타입을 느리게 만든다. Simplicity First가 초기 코드에 오작동한다.
작동하지 않은 시도
저자가 12규칙에 안착하기 전에 시도하고 버린 것들이다.
- 레딧/X에서 본 규칙들 — 대부분 Karpathy 4의 다른 표현이거나, 일반화되지 않는 도메인 특이 규칙(“Tailwind 클래스를 항상 써라”)이었다. 잘랐다.
- 12개 이상의 규칙 — 18까지 시험했다. 14개를 넘으면 컴플라이언스가 76% → 52%로 떨어졌다. 모델은 “규칙이 존재한다"는 사실에 패턴 매칭만 하고 실제로 읽지 않기 시작한다.
- 존재하지 않을 수 있는 도구에 의존하는 규칙 — “항상 eslint를 써라"는 eslint가 설치되지 않은 환경에서 조용히 무너진다. “코드베이스가 강제하는 스타일을 따라라"처럼 능력 불가지론적으로 다시 썼다.
- CLAUDE.md 안의 예제 — 예제 3개의 토큰 비용은 규칙 10개와 맞먹는다. 모델은 추상 규칙보다 구체 예제에 과적합한다. 규칙은 추상적이고, 예제는 구체적이다. 규칙을 쓴다.
- “신중하게” / “깊이 생각해” / “정말 집중해” — 순수 노이즈. 컴플라이언스 30%로 떨어진다. 테스트할 수 없기 때문이다. “가정을 명시적으로 진술하라” 같은 구체적 명령으로 바꿔야 한다.
- “시니어처럼 행동하라” — 작동하지 않는다. 모델은 이미 자신을 시니어로 여긴다. 컴플라이언스 격차는 생각과 행동 사이에 있고, 정체성 프롬프트는 그 격차를 못 닫는다. 명령형 규칙이 닫는다.
멘탈 모델
CLAUDE.md는 위시리스트가 아니다. 관찰된 실패 모드를 닫는 행동 계약이다. 각 규칙은 *이 규칙이 어떤 실수를 막는가?*에 답할 수 있어야 한다.
저자가 강조하는 마지막 원칙은 두 가지다.
- 각 규칙은 답을 가져야 한다 — 답할 수 없으면 규칙이 아니라 희망이다.
- 내 실수에 맞춘 6규칙이 일반 12규칙을 이긴다 — 멀티스텝 파이프라인을 안 돌리면 Rule 10은 불필요하고, 린팅으로 스타일이 강제되면 Rule 11은 잉여다. 12규칙을 읽고, 실제로 한 실수에 매핑되는 것만 남기고 나머지는 버리는 것이 정답이다.
가장 흥미로운 지점
내가 가장 흥미롭게 본 부분은 컴플라이언스와 실수율의 디커플링이다. 4규칙에서 12규칙으로 늘릴 때 컴플라이언스는 78%에서 76%로 거의 변하지 않는데, 실수율은 11%에서 3%로 더 떨어진다. 같은 자원(주의 예산)을 두고 새 규칙이 경쟁하지 않는다는 뜻이고, 서로 다른 실수를 막는 규칙끼리는 직교한다는 정량적 신호다.
그런데 14개를 넘기는 순간 컴플라이언스가 52%로 폭락한다. 직교성이 영원하지는 않다. 어느 지점에서 모델은 규칙의 내용이 아니라 존재 자체에 패턴 매칭하기 시작한다. 200줄 천장은 비유가 아니라 실측된 임계값이다.
이 두 가지를 함께 보면, CLAUDE.md 설계의 진짜 변수는 규칙의 개수가 아니라 규칙끼리 다른 실수를 다루는가이다. 같은 실수를 다른 표현으로 두 번 적으면 한 자리를 낭비한다. 그것은 200줄 예산 안에서 정말 비싼 사치다.
출처
저자: Mnilax · 발행: 2026년 5월 · 플랫폼: X(Twitter) 원문: https://x.com/Mnilax/status/2053116311132155938