3줄 요약
- Robin Hogarth, Tomás Lejarraga, Emre Soyer가 2015년 Current Directions in Psychological Science에 게재한 짧은 개관 논문이다. “착한(kind) 학습 환경 / 사악한(wicked) 학습 환경"이라는 개념의 학술 정본 문헌이다.12
- 사람의 추론은 한 모집단이 아니라 두 개의 설정(two settings)을 다룬다. 정보가 쌓이는 학습 설정 L과 그 정보가 적용되는 타깃 설정 T 사이의 정보 원소가 얼마나 일치하는가가 직관의 정확성을 결정한다. 매칭 양상을 6가지 케이스(A~F)로 분류해 kind와 wicked의 경계를 명확히 한다.
- 처방은 단순하다 — 학습 환경을 일부러 kind하게 설계하면 통계적·경제적 판단 정확도가 올라간다. 사람의 합리성을 가정하는 대신, 사람이 학습한 환경을 정교하게 만드는 쪽이 더 빠른 길이라는 것이 결론이다.
원전과 트윗 사이의 거리 — 왜 정리가 필요한가
이 다이제스트는 David Epstein의 Range를 인용한 트윗을 계기로 원전을 추적해 정리한 결과다. 트윗은 Range의 흐름을 그대로 따라 “체스는 kind 환경, 의료·투자·창업은 wicked 환경"이라고 단순화한다. 그러나 Range가 인용한 Hogarth 2001의 개념은 14년 뒤 Current Directions in Psychological Science에 실린 본 논문에서 보다 정교한 분류 도구로 다듬어진다. 트윗에서 빠진 것 두 가지가 핵심이다.3
첫째, kind와 wicked는 이분법이 아니라 연속체다. 둘째, kind/wicked의 기준은 단순한 “피드백 품질"이 아니라 학습 단계의 정보(L)와 타깃 단계의 정보(T) 사이의 집합론적 매칭이다. 이 두 가지가 이 논문의 핵심 기여다.
두 설정 프레임워크 — L과 T
우리는 두 모집단이 아니라 두 설정을 다룬다고 본다. 첫 번째 설정에서 사람은 상황을 학습한다(두 변수가 어떻게 공변하는가 등). 두 번째 설정에서, 학습한 지식을 사용해 행동하거나 예측한다.
기존 판단·의사결정 문헌은 표본이 같은 모집단에서 무작위로 뽑힌다고 가정해왔다(Tversky & Kahneman, 1974 등). 저자들은 이 가정 자체를 문제 삼는다. 사람이 실제로 마주하는 것은 학습(Learning) 설정 L과 타깃(Target) 설정 T라는 두 개의 분포이며, 둘이 얼마나 일치하는지를 따져야 한다는 것이다.
논문의 예시: 인사 담당자가 입사 시험으로 후보자를 뽑는다. 과거에 그 시험이 정확했다(L). 지금 후보자에게 그 시험을 쓴다(T). 정확도는 두 설정의 특징이 얼마나 일치하는가에 달려 있다 — 지금 후보자들이 과거 후보자들과 비슷한가? 이 매칭을 묻는 일이 추론의 본질이다.
매칭의 여섯 가지 모양 — Figure 1
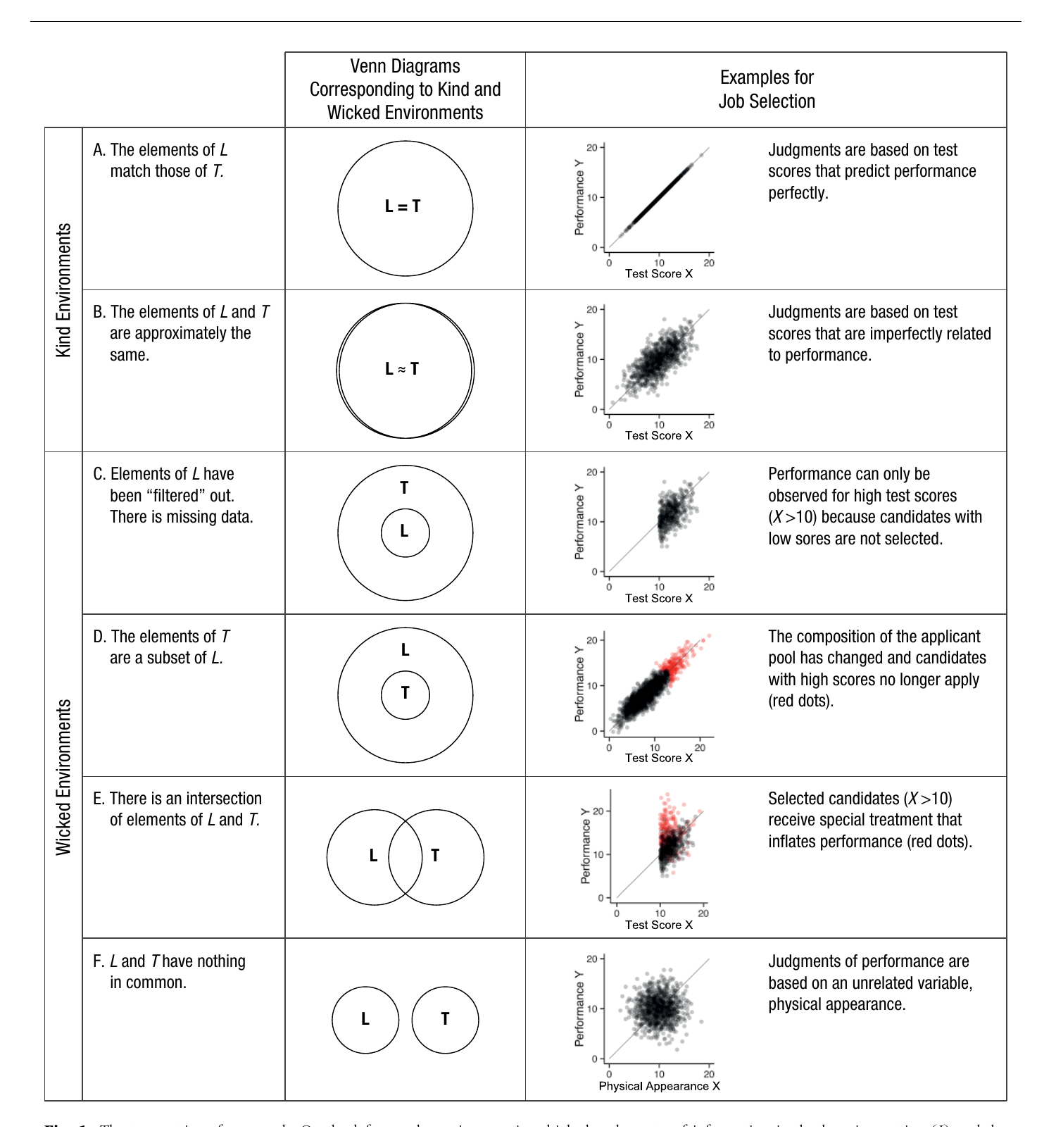
논문의 정수는 위 표 한 장에 다 들어있다. 좌측은 L과 T의 집합 관계(벤 다이어그램), 우측은 채용 시험 시나리오를 통한 예시다.
Kind Environments
- 케이스 A — L = T (완전 일치): 시험 점수가 업무 성과와 상관계수 1.0. 시험으로 성과를 완전히 예측한다.
- 케이스 B — L ≈ T (근사 일치, 노이즈만 있음): 무작위 오차로 산점도가 타원 형태. 매칭은 근사적이지만 mismatch의 원인이 전적으로 무작위다.
Wicked Environments
- 케이스 C — L ⊂ T (학습 데이터에 누락): 시험에서 낮은 점수를 받은 사람은 채용되지 않았으므로, 그들의 성과 데이터 자체가 없다. 생존 편향(survivorship bias)의 구조다.
- 케이스 D — T ⊂ L (타깃이 학습의 부분집합): 지원자 풀의 구성이 바뀌었는데(예: 지역 대학이 입학 기준을 낮춰 우수 후보가 더 이상 지원하지 않음) 인사 담당자는 모른다. 과거에 학습한 분포의 일부만 지금 마주한다.
- 케이스 E — L ∩ T (체계적 교집합): 채용된 후보(X > 10)에게만 특별한 처우(예: 좋은 멘토)가 주어져 성과가 체계적으로 부풀려진다. 자기 충족 예언, 처치 효과가 여기 속한다.
- 케이스 F — L ∩ T = ∅ (공통 원소 없음): 성과 예측에 쓴 변수(예: 외모)가 성과와 무관하다.
논문은 *kindness/wickedness는 정도(degree)*라고 분명히 한다. A는 B보다 kind하고, B는 E·F보다 kind하다. 흥미로운 단서가 하나 있다 —
노이즈가 매우 클 때, B의 예측력은 C와 같은 일부 wicked 환경보다 오히려 더 낮을 수 있다. 그러나 둘의 차이는 명확하다 — B의 mismatch 원인은 무작위이고, C의 원인은 체계적이다.
이 한 문장이 중요하다. 예측 정확도와 환경의 kind/wicked는 별개의 축이라는 뜻이다. Wicked한데 정확도가 더 높을 수도 있고, kind한데 노이즈가 너무 커서 무용할 수도 있다. 분류는 원인의 종류를 가르는 일이지 정확도 순위를 매기는 일이 아니다.
디폴트는 매칭 — 사람이 헷갈리는 이유
사람은 흔히 “L과 T가 일치한다"는 디폴트로 추론한다(Kahneman & Tversky, 1973). 저자들은 그 이유를 세 가지로 정리한다.
- 추론은 흔히 방향만 필요하다. 정확한 수치가 아니라 “A가 B보다 큰가” 정도로 충분한 경우가 많다.
- 누락된 정보를 보정하는 일이 규범적으로도 어렵다. C(missing data)나 D(unrepresentative learning)에서 어떻게 교정해야 하는지가 명확하지 않다.
- 디폴트 매칭은 인지적으로 단순하다. 디폴트를 의심하려면 메타인지가 필요한데, 사람들은 그것을 늘 가동하지는 않는다.
이 세 번째 이유가 가장 통렬하다. 디폴트를 왜 의심해야 하는지 인지하려면, 이미 두 설정 프레임워크 같은 도구가 머릿속에 있어야 한다는 뜻이다. 도구 없는 사람에게 “당신의 학습 표본이 편향되어 있다"는 경고는 들리지 않는다.
네 가지 고전적 편향, 두 설정 프레임으로 다시 보기
논문 Table 1은 익숙한 편향 네 가지를 L↔T 매칭 관점으로 재해석한다.
| 편향 | 학습 설정 L에서 무엇이 일어나는가 | 사례 |
|---|---|---|
| 생존 편향 | L이 과거 실패 사례를 제외 → T로의 외삽이 편향됨 | 실패한 창업가가 사라지므로 신규 벤처의 성공 확률이 과대평가됨 (Einhorn & Hogarth, 1978) |
| 검열 편향 | L이 검열 지점 너머 정보를 배제 → T 평가에 필요한 정보 부족 | 매니저는 직원이 일을 못해낼 때만 관찰하고, 더 많이 할 수 있었을 때는 관찰하지 못함 (Feiler, Tong, & Larrick, 2012) |
| 선택 편향 | L이 특정 부분집합에 집중 → T에서 고려해야 할 사례가 빠짐 | 기자가 성공한 기업만 연구해 “성공 비결"을 찾음 (Denrell, 2005b) |
| Hot stove 효과 | 초기 부정 경험이 L에서의 탐색을 멈추게 함 → T에 필요한 원소를 L에서 빠뜨림 | 매니저가 즉각적 부정 효과 때문에 새 프로세스를 즉시 폐기하고 재시도하지 않음 (Denrell & March, 2001) |
네 편향은 “사람의 인지 결함"으로 묶이지 않고, 모두 학습 환경이 타깃 환경의 어떤 부분을 잘라먹었기 때문으로 통일된다. 같은 사람이라도 환경이 kind했다면 같은 편향에 빠지지 않았을 것이다.
처방 — 환경 자체를 kind하게 만든다
판단 편향을 고치려는 시도는 무수히 많았고, 대부분 한정적 성공에 그쳤다. 저자들의 처방은 다른 각도다 — 사람을 고치지 말고 환경을 고친다.
저자들이 직접 수행한 simulated experience 연구(Hogarth & Soyer, 2011)가 그 예다. 사람들에게 확률 과정의 결과를 순차적으로 경험하게 함으로써 인위적으로 kind한 학습 환경을 만들었더니, 평소에는 틀리던 확률 추론을 정확히 수행했다는 결과다. 게다가 본인의 답에 자신감까지 가졌다.
같은 논리를 경제 정책에도 적용할 수 있다. 사람이 합리적 극대화를 계산할 수 있다고 가정하는 대신, kind한 학습 환경을 경험하게 함으로써 결과적으로 극대화 행동을 끌어낼 수 있다는 것이다. Erev & Roth(2014)의 결과가 이 방향을 시사한다.
흥미로운 단서: wicked 환경을 의도적으로 이용할 수도 있다. 위약(placebo) 효과가 그 예다 — 환자가 경험으로부터 “잘못된” 교훈을 얻게 하는 것이 치료 목적이라면, 환경을 일부러 wicked하게 설계하는 것이 정당하다.
다른 프레임워크와의 관계
저자들은 두 설정 사이의 매칭이라는 발상의 계보를 짧게 짚는다.
- Thorndike(1903) “동일 원소(identical elements)” 이론 — 학습 전이는 학습 설정과 적용 설정에서 동일한 원소들이 얼마나 겹치는가에 달려있다는 주장. 단, Thorndike는 사실·기술 학습(예: 테니스가 다른 라켓 종목으로 전이되는가)을 다뤘다.
- 통계학·머신러닝의 out-of-sample 검증 — 표본 결과가 모집단으로 일반화된다는 가정을 검증하는 기법들. L↔T mismatch를 명시적으로 다루는 공학적 사례.
- Affective forecasting(Gilbert & Wilson, 2007) — 미래 결과의 상상과 실제 경험의 mismatch. 컨버터블 차를 살 때 화창한 날만 상상하고 비 오는 날은 안 떠올리는 것 등.
- 동적/비정상 환경 — 시간에 따라 변하는 환경은 기본적으로 wicked(케이스 E)지만, 변화의 양상이 첫 설정에서 추론 가능하다면 kind 환경이 될 수 있다. 계절 주기 학습이 그 예다.
가장 흥미로운 지점
논문을 읽고 두 가지가 머리에 남는다.
첫째, B(노이즈 큰 kind)와 C(systematic missing data wicked)의 예측력 역전 가능성이다. “kind = 정확, wicked = 부정확"이라는 직관은 깨진다. 노이즈가 충분히 크면 kind 환경의 예측력이 체계적으로 일부만 빠진 wicked 환경보다 낮을 수 있다. 다만 둘은 다른 처방을 요구한다 — B에는 표본을 키우는 것이 답이고, C에는 빠진 부분을 어떻게 채울지의 질문이 답이다. 정확도가 같더라도 개선 전략이 다르다는 것이 분류의 실용적 가치다.
둘째, 케이스 E의 자기 충족 예언이 가장 무섭다. 채용 시험으로 뽑힌 사람에게만 멘토를 붙여주면, 시험은 정말로 성과를 예측하는 도구처럼 보이게 된다. 인사 담당자는 L에서 “시험 점수와 성과의 강한 상관"을 학습하지만, 그 상관은 시스템이 만든 것이지 시험이 측정한 것이 아니다. 이 구조는 채용 시험뿐 아니라 모든 게이트키핑 메커니즘에 적용된다 — 대학 입시, 신용 평가, 의료 분류, 추천 알고리즘. 학습 데이터를 만들어내는 시스템 자체가 인과를 휘어놓는다.
논문 도입부의 장티푸스 메리 일화가 이 두 지점을 한 번에 보여준다. 뉴욕의 한 의사가 환자 혀를 만져 장티푸스를 진단해 명성을 얻었다. 항상 정확했다. 그러나 Lewis Thomas의 표현대로, “그는 손만으로도 장티푸스 메리보다 더 효과적인 보균자였다.” 의사의 학습 환경(L)은 자신이 진단한 사람들이 며칠 뒤 발병하는 것이었다. 이 L은 T를 예측하지 않았다 — T를 만들어냈다. 케이스 E의 가장 사악한 형태다.
이 일화가 1세기를 가로질러 여전히 무서운 이유는, 우리가 만드는 거의 모든 시스템이 같은 함정을 안고 있기 때문이다. 충분히 큰 규모로 작동하는 시스템은 자기 예측을 실현하기 시작한다. AI 추천 시스템부터 신용 점수까지, 자기 충족 예언의 구조가 케이스 E의 정의를 통과한다. 이 통과 여부를 빠르게 진단할 수 있는 사고 틀이 두 설정 프레임워크의 실용적 가치다.
출처
- 개념의 원전: Hogarth, R. M. (2001). Educating Intuition. Chicago: The University of Chicago Press. (특히 Chapter 3)
Hogarth, R. M., Lejarraga, T., & Soyer, E. (2015). The Two Settings of Kind and Wicked Learning Environments. Current Directions in Psychological Science, 24(5), 379–385. doi:10.1177/0963721415591878 ↩︎
풀텍스트 PDF (Max Planck PuRe, CC 알리안츠 라이선스): https://pure.mpg.de/pubman/item/item_2225074_9 ↩︎
다이제스트 계기 트윗: https://x.com/ihtesham2005/status/2053103815482859767 ↩︎