3줄 요약
- Tsinghua·University of Chicago 공동 연구진(Hao·Xu·Li·Evans)이 1980~2025년 자연과학 논문 4,130만 편을 분석해 AI 도입의 개인-집단 효과를 동시에 측정한 Nature 게재(2026년 1월) 논문이다.
- 개별 과학자에게 AI는 강력한 추진제다 — 논문 수 3.02배, 인용 4.84배, 프로젝트 리더 1.37년 조기 진입.
- 그러나 집단 차원에서 과학의 주제 다양성은 4.63% 좁혀지고, 후속 연구 간 상호 인용은 22% 감소한다. AI는 데이터가 풍부한 분야로 과학자를 끌어모아 “데이터 부족한 프런티어"를 비워 두는 중력장 역할을 한다.
연구 설계
저자들은 OpenAlex 데이터셋에서 1980~2025년 영어 자연과학 논문 41,298,433편을 추렸다. 분야는 생물·의학·화학·물리·재료·지질 6개 — AI 자체를 발명·정련하는 컴퓨터과학·수학은 의도적으로 제외했다. AI를 쓰는 자연과학과 AI를 만드는 학문을 분리해야, AI가 다른 학문에 미치는 영향을 깨끗하게 측정할 수 있기 때문이다.
AI 논문 식별은 BERT 기반 두 단계 분류기를 썼다. 제목과 초록을 각각 학습한 두 모델을 앙상블해 F1=0.875의 식별 정확도를 얻었고, 12명의 도메인 전문가가 라벨링한 결과(Fleiss’ κ=0.964)와 대조했다. 식별된 AI 논문은 총 310,957편으로, 전체의 0.75%다.
저자들은 AI 발전을 세 시대로 나눈다.
각 시대마다 AI 채택률은 가속됐다. 1980년 대비 2025년 AI 논문 비중은 지질학에서 10.70배, 생물학에서 51.89배로 늘었고, AI를 채택한 연구자 수는 지질학에서 135.46배, 물리학에서 362.16배로 증가했다.
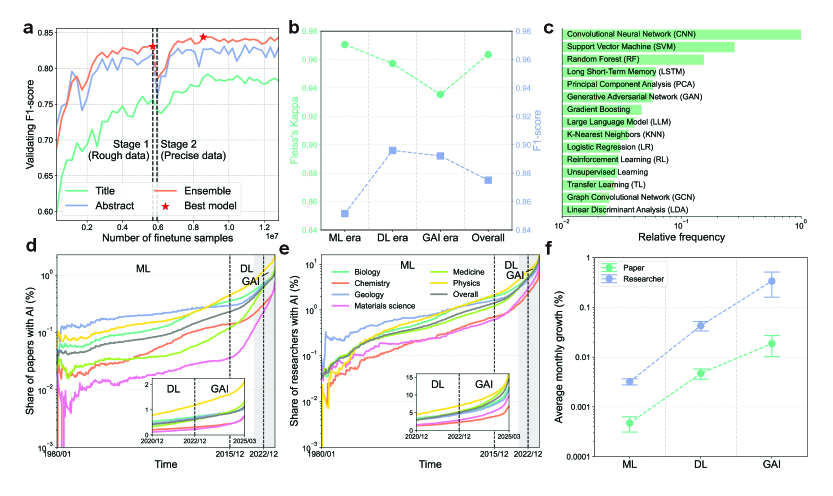
Fig 1. 1980~2025년 6개 자연과학 분야의 AI 채택 추세. 모든 분야에서 AI 논문 비중과 AI 채택 연구자 수가 가속하며 증가한다. 출처: Hao et al. (2026), Nature, CC BY 4.0.
개인 차원 — AI는 과학자에게 무엇을 주는가
먼저 논문 단위. AI 논문은 발표 이후 수십 년에 걸쳐 비-AI 논문보다 연간 인용을 평균 98.70% 더 받는다. JCR Q1 저널 게재 비중도 18.60% 더 높다.
연구자 단위에서는 격차가 더 크다. AI를 채택한 과학자는 평균적으로 다음 이점을 누린다.
| 지표 | AI 채택 vs. 비채택 |
|---|---|
| 연간 출판 논문 수 | 3.02배 |
| 연간 받는 인용 수 | 4.84배 |
| 주니어 → 시니어(프로젝트 리더) 전환 시간 | 1.37년 단축 (7.33년 vs. 8.70년) |
| 주니어가 시니어로 전환할 확률 | 13.64%p 높음 (45.00% vs. 31.36%) |
저자들은 같은 시기 같은 위치에서 출발한 과학자들을 매칭한 분석(selection bias 통제)에서도 이 격차가 유지된다고 보고한다. 즉 “원래 잘하는 사람이 AI를 쓰는” 효과가 아니라, AI 자체가 추가 가속을 만든다는 것이다.
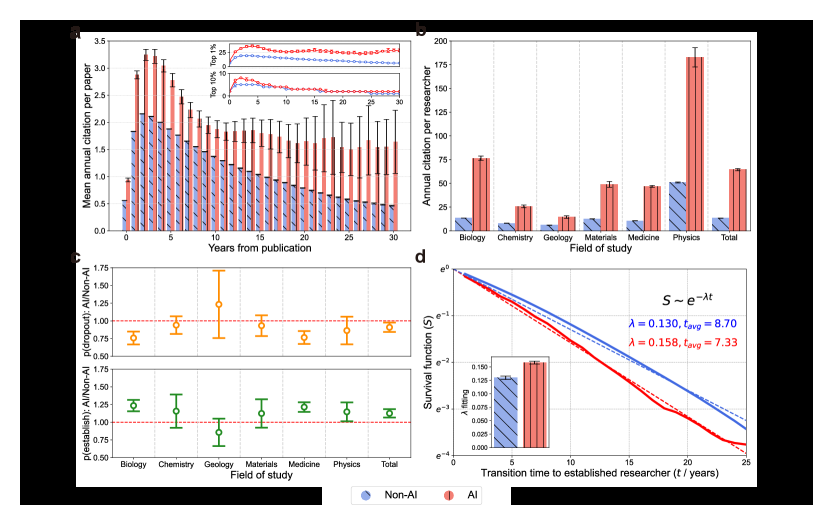
Fig 2. (a) AI 논문 vs. 비-AI 논문의 연간 평균 인용. (b) AI 채택 연구자의 연간 인용 — 4.84배. (c) 주니어→시니어 전환 확률. (d) 전환 시간 생존 함수 — 지수 분포 적합. 출처: Hao et al. (2026), Nature.
흥미로운 부차 발견 한 가지: AI 논문 팀은 비-AI 팀보다 평균 19.29% 작다. 특히 주니어 연구자 수가 31.14% 줄어든다. AI가 주니어가 하던 단순 데이터 처리·문헌 검색·코드 작성을 자동화하면서, 팀이 굳이 주니어를 많이 두지 않아도 굴러간다는 신호다. 동시에 남아 있는 주니어는 더 빨리 시니어가 된다. 입구는 좁아지고 통과는 빨라지는 구조다.
집단 차원 — 과학의 초점은 좁아진다
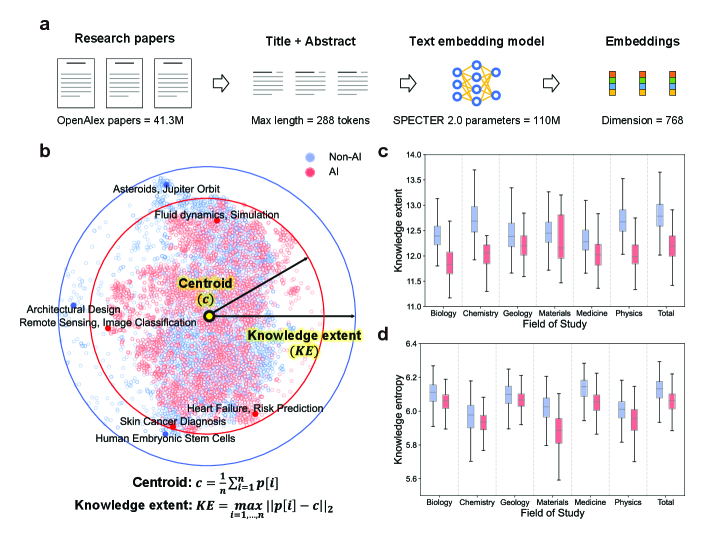
논문은 여기서부터 본격적으로 역설을 펼친다. 저자들은 논문을 SPECTER 2.0(과학 문헌 전용 임베딩) 768차원 공간에 투영한 뒤, 두 가지 지표로 “지식의 너비"를 측정했다.
- 지식 범위(Knowledge Extent, KE) — 표본 논문군이 공간에서 차지하는 “지름”. 같은 분야 내에서 얼마나 넓은 주제를 다루는지.
- 지식 엔트로피 — 주제 분포의 균등도. 낮을수록 특정 문제에 쏠려 있다는 뜻.
결과는 일관적이다. AI 연구는 비-AI 연구보다 지식 범위가 4.63% 좁고, 모든 6개 분야에서 (p<0.001) 동일한 방향이다. 200개 이상의 하위 분야로 쪼개 봐도 70% 이상에서 같은 수축이 관찰된다. 엔트로피도 모든 분야에서 낮다 — AI 연구는 분야 전반보다 특정 인기 문제에 쏠려 있다.

Fig 3. (b) 768차원 임베딩의 t-SNE 투영. AI 논문(파랑)은 비-AI 논문(주황)보다 좁은 영역에 군집한다. (c) 6개 분야 모두에서 AI의 지식 범위가 더 좁다. (d) 엔트로피도 일관되게 낮다. 출처: Hao et al. (2026), Nature.
저자들은 이 수축의 원인을 따져 봤다. 주제의 본질적 인기, 원래의 영향력, 연구비 우선순위 — 모두 AI 채택률과 거의 관련이 없었다. 유일하게 강하게 연관된 변수는 데이터 가용성이다. 데이터가 풍부한 영역일수록 AI가 도입되고, 결과적으로 그 영역에 과학자가 더 모인다. AI는 데이터의 무게로 학문 공간을 잡아당기는 중력장이다.
메커니즘 — 별 모양 인용과 “외로운 군중”
수축이 어디서 오는가? 저자들은 두 가지 보완 분석으로 메커니즘을 풀어낸다.
먼저 논문 가족(paper family) 분석. AI 논문 한 편에서 파생된 인용 가족의 지식 범위는 오히려 비-AI보다 3.46% 넓다. 즉 원본 한 편이 다양한 후속 연구를 낳는 능력은 AI 쪽이 더 좋다. 그렇다면 전체 수축은 어디서 오는가?
답은 후속 연구들 사이의 상호 인용 부재에 있다. 같은 원본을 인용한 후속 논문들이 서로 인용하는 빈도 — 저자들은 이를 “팔로우온 engagement"라 부른다 — 가 AI 연구에서는 22.00% 낮다. 후속 연구들은 원본만 바라볼 뿐, 서로 대화하지 않는다.
이 패턴이 누적되면 별 모양 인용 구조가 생긴다. 소수 슈퍼스타 논문이 중앙에 있고, 다수의 후속 논문이 방사형으로 매달려 있되 서로는 연결되지 않는 구조. AI 인용의 GINI 계수는 0.754로, 비-AI(0.690)보다 높다. 상위 22.2% 논문이 전체 인용의 80%를, 상위 54.14%가 95%를 가져간다.
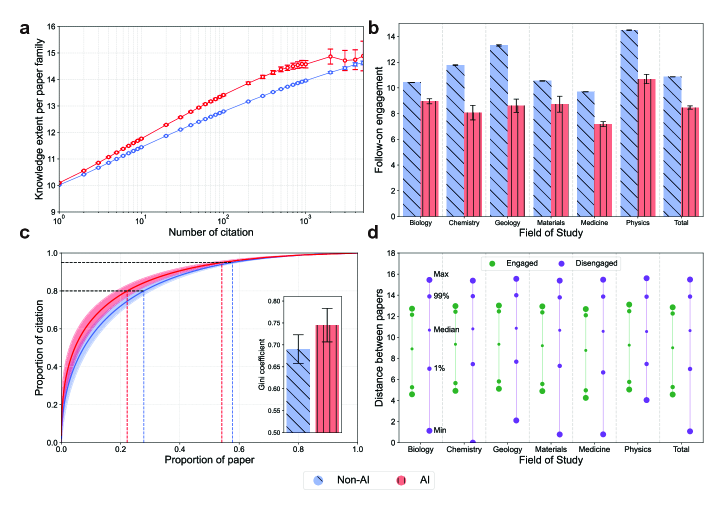
Fig 4. (b) 같은 원본을 인용한 논문들끼리 서로 인용하는 비율 — AI 쪽이 22% 낮다. (c) 인용 분포 — AI는 상위 소수가 압도적으로 점유. (d) 같은 원본을 인용하면서도 서로 모르는 논문 쌍은 임베딩 공간에서 가장 가까운 쌍의 거리가 76.51% 더 짧다 — 중복 연구의 신호. 출처: Hao et al. (2026), Nature.
더 통렬한 발견은 (d) 패널에 있다. 같은 원본을 인용했지만 서로 모르는 논문 쌍을 보면, 임베딩 공간에서 가장 가까운 쌍의 거리가 서로 아는 쌍보다 76.51% 짧다. 가까이서 같은 주제를 다루면서도 서로의 존재를 모르는 — “lonely crowd”. 결과적으로 중복 연구가 늘어난다.
저자들은 이 집단 행동을 collective hill-climbing(집단적 산오름)으로 비유한다.
모두가 같은 인기 산을, 같은 등산로로 오르는 상황. 경로와 정상이 모두 한정되어 있어 정체가 발생하고, 더 높을 수도 있는 다른 산 — 새로운 질문과 답 — 의 탐색은 외면받는다.
AI가 잘하는 일(데이터 풍부한 분야의 알려진 문제 가속)이 너무 매력적이기 때문에, 과학자들은 그쪽으로 몰리고, 그 결과 과학 전체의 다양성이 줄어든다.
정책 함의 — 무엇이 뒤에 남겨지는가
저자들은 Discussion에서 가장 무거운 질문을 던진다. 어떤 주제가 AI 시대에 가장 덜 다뤄질 위험에 처해 있는가?
답은 자연 현상의 기원에 관한 질문들이다. 본질적으로 데이터가 적을 수밖에 없는 주제 — 희귀 질환, 신생 분야, 가설이 먼저 와야 데이터가 모이는 영역. AI는 “가로등 아래의 과학"을 가속하면서, 가로등이 비치지 않는 곳의 근본 질문을 멀리한다.
이 우려가 더 큰 이유는 두 가지 요인이 겹쳐 있기 때문이다.
- 개인적 인센티브: 논문 3배, 인용 5배, 승진 1.37년 빠름. AI 채택을 거부하는 합리적 이유가 개인 차원에선 없다.
- 정책적 가속: 연구비 정책은 AI for Science 지원을 늘리는 방향으로 움직인다.4
두 힘이 합쳐지면 데이터 빈약한 프런티어는 더 비워진다. 저자들은 마지막 문단에서 처방을 제시한다 — AI의 인지적 능력 확장에서 감각적·실험적 능력 확장으로 방향을 전환해야 한다는 것이다. 기존 데이터를 더 잘 분석하는 AI가 아니라, 지금까지 접근 불가능했던 새로운 종류의 데이터를 수집하고 관측할 수 있게 해 주는 AI. 과학사의 큰 발견들이 새 도구로 자연을 새로 본 데서 왔다는 점을 떠올리면 자연스러운 결론이다.
가장 흥미로운 지점
내가 가장 오래 멈춰 선 부분은 메커니즘이 결핍이 아니라 효율에서 온다는 점이다. AI 연구의 인용 가족이 더 넓다는 발견 — 즉 AI 논문 한 편은 다양한 후속을 낳는 능력이 충분하다. 그런데도 전체 다양성이 좁아지는 이유는, 그 후속들이 서로의 존재를 모르기 때문이다.
AI가 자동화하는 일들 — 문헌 검색, 데이터 정리, 가설 후보 생성 — 은 원래는 옆 연구실의 동료와 대화하면서 하던 일이다. 그 대화에서 우연한 충돌이 새 발견을 낳았다. NPR 인터뷰에서 James Evans가 짚은 대목도 같다. AI가 동료 대화를 대체할 수 있게 되면서, 과학자들이 그 대화를 덜 하게 된다. 22% 감소는 인지적 도구의 부수효과가 아니라, 과학이라는 사회 시스템 자체의 구조 변화 신호다.
거꾸로 말하면, AI 시대에 과학의 다양성을 지키려면 “AI를 덜 쓰자"가 아니라 “AI를 쓰는 사람들 사이의 우연한 충돌을 어떻게 다시 설계할 것인가"가 진짜 질문이다. 학회 구조, 협업 인센티브, 평가 시스템, 도구 자체의 UX — 모두 다시 봐야 할 자리에 놓여 있다.
같은 시기 Nature에 실린 동반 논문은 이 흐름이 과학자 훈련과 판단력 자체를 약화시킬 위험을 추가로 경고했다. 개인 가속과 집단 수축의 역설은, 더 깊은 곳에서는 과학자가 무엇을 배워서 무엇을 묻는 사람으로 자라느냐의 문제로 이어진다.
출처
- 논문: Hao, Q., Xu, F., Li, Y., & Evans, J. (2026). Artificial intelligence tools expand scientists’ impact but contract science’s focus. Nature, 649(8099), 1237–1243.
arXiv 프리프린트: https://arxiv.org/abs/2412.07727 ↩︎
트윗 소개: @iam_elias1, 2026-05 ↩︎