3줄 요약
- Goodfire가 ‘Neural Geometry Series’의 둘째 글로 발표한 사례 연구다 (Wurgaft·Rager·Kowal·Shyam·Feucht 외, 2026-05-07). 어제 공개된 첫 글 The World Inside Neural Networks가 매니폴드 가설을 입장문으로 폈다면, 이 글은 요일이라는 순환 개념으로 그 가설을 검증한다.
- Llama-3.1 8B에 “What day comes five days after Sunday?” 류 질문을 던지면 출력 토큰 분포(행동 매니폴드)와 내부 활성(표상 매니폴드) 양쪽에서 일곱 요일이 같은 원형 7-클러스터를 이룬다. 표상 매니폴드의 곡선을 따라 활성을 움직이면 Mon→Tue→Wed로 확률 질량이 깨끗이 옮겨가지만, 직선 스티어링은 행동 매니폴드를 가로질러 노이즈와 비요일 토큰을 만든다.
- 표상→행동만이 아니라 행동→표상도 성립한다. 행동 매니폴드를 따라 활성 개입을 최적화하면 그 활성 경로가 별도로 추정한 표상 매니폴드와 모양이 일치한다. 두 기하는 사전적으로 정렬될 이유가 없는데도 정확히 대응하며, 같은 패턴이 월·글자·나이·합성 ICL·이미지-액션 모델에서도 재현된다.
출처: Goodfire, Steering Along Manifolds to Control Neural Networks 메인 비주얼 (2026-05-07).1 원본: https://static.goodfire.ai/manifold-steering/bead-maze-riso-wide.webp
{kind=link}
들어가며 — 왜 매니폴드 스티어링인가
표상 스티어링(representation steering)은 모델의 내부 활성에 개입해 행동을 조정하는 가벼운 기법이다. 추론과 훈련 양쪽에서 모델 설계와 정렬에 쓸 수 있다. 표준 방식은 직선이다. 활성에 스티어링 벡터를 스칼라 배수로 더하는 식이다. 조작 대상 개념이 표상 공간의 직선 위에 살 때 잘 작동하지만, 그렇지 않다면 어떨까.
“steering along manifolds, i.e., curved surfaces in representation space, provides better control than linear steering”
이 글은 그 답을 요일이라는 가장 친숙한 순환 개념으로 보인다. 시리즈의 첫 글에서 mountain car의 1차원 위치 매니폴드로 직관을 제시했다면, 이번엔 7개 점이 닫힌 고리를 이루는 진짜 순환 구조를 검증대에 올린다.
사례 — 요일은 임의 토큰이 아니라 순환이다
요일은 인간이 시간을 조직하는 순환 개념이다. 사전학습 데이터의 공기(共起) 통계에 그 구조가 새겨진다. Monday는 Sunday·Tuesday와 더 자주 함께 나타나고 Thursday와는 덜 함께 나타난다. 그 결과 모델은 Monday부터 Sunday까지의 토큰을 임의 심볼이 아니라 닫힌 고리 구조로 표상한다.
“language models don’t treat the tokens Monday, Tuesday…, Saturday, Sunday as arbitrary symbols, but instead recapitulate the cyclical structure in their behavior and representations”
저자들은 Llama-3.1 8B에 “What day comes five days after Sunday?” 류 프로프트를 던져 행동(출력 토큰의 확률 분포)과 표상(내부 활성 벡터)을 동시에 살핀다. 두 공간 모두에서 일곱 요일이 원으로 배치된 클러스터로 드러난다.
두 매니폴드 — 행동 공간과 활성 공간
행동 매니폴드
각 프로프트가 만드는 출력 토큰 분포 사이의 거리를 Hellinger 거리로 잰다. 이 행동 공간에서 일곱 요일이 원형 7-클러스터를 이룬다. 모델이 Monday를 출력할 때, Sunday와 Tuesday에 부여되는 확률은 Thursday보다 높다. 이 원에 1차원 매니폴드를 적합하면, 매니폴드를 한 발자국 이동시키는 것은 한 요일에서 인접 요일로 확률 질량을 옮기는 일에 해당한다.
표상 매니폴드
내부 활성 벡터를 좌표로 보면 같은 원형 7-클러스터가 다시 나타난다. 인접 요일은 더 비슷한 활성으로 표상된다. 여기에도 1차원 매니폴드를 적합할 수 있다. 두 매니폴드의 닮음은 우연이 아니다. 둘 다 학습 데이터의 순환 구조라는 공통 기원에서 비롯한 결과다.
기하 인지 스티어링 — 직선 vs 매니폴드
저자들은 데모에서2 슬라이더를 끌면 두 종류 개입을 동시에 수행한다. 활성에 직선 스티어링 벡터를 더하는 길과, 표상 매니폴드의 곡선을 따라 움직이는 길이다.
매니폴드를 따라가면 출력 분포가 행동 매니폴드의 자연스러운 원을 따라간다. Monday→Tuesday→Wednesday→Thursday→Friday로 확률 질량이 깔끔하게 이동한다. 반면 직선 스티어링은
“linear steering cuts across the behavior manifold and produces noisy, off-target effects”
여기서 ‘cuts across’가 결정적이다. 활성 공간의 직선은 표상 매니폴드의 곡선을 가로지르므로, 그 활성에 대응하는 출력 분포가 행동 매니폴드 위의 어떤 자연스러운 점에도 닿지 않는다. 결과는 노이즈다. 자료에 따르면 직선 스티어링이 만드는 출력 토큰은 요일조차 아닌 경우가 흔하다.
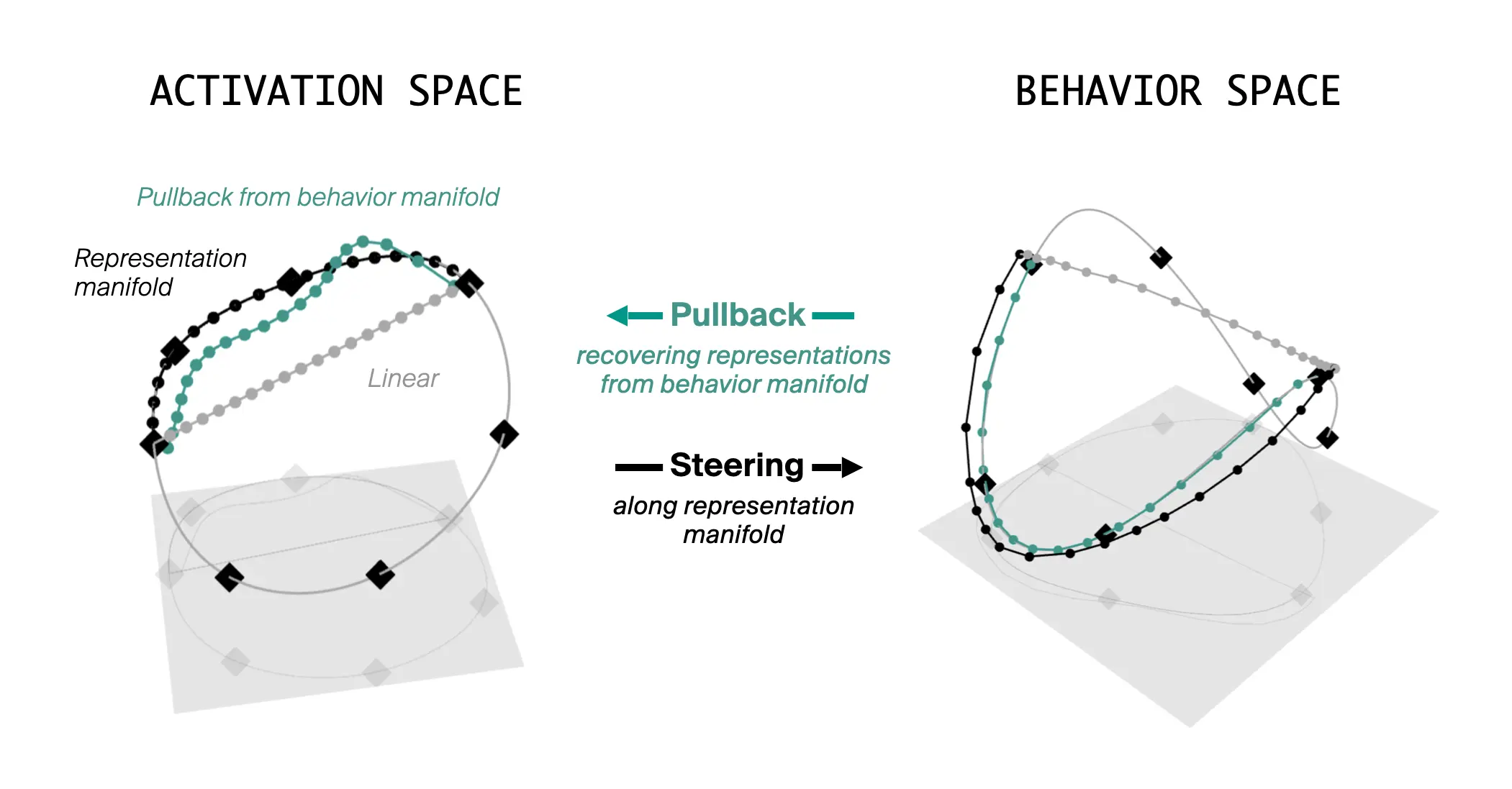
양방향 일치 — Pullback 실험
여기까지는 표상→행동 방향이다. 매니폴드를 따라 표상을 움직이면 행동도 매니폴드를 따라간다. 저자들은 반대 방향도 묻는다. 표상 매니폴드는 잠시 잊고, 출력 분포가 행동 매니폴드를 따르도록 활성 개입을 최적화하면 어떤 경로가 나오는가.
놀랍게도, 그렇게 얻은 활성 공간의 경로는 별도로 추정한 표상 매니폴드와 형태가 일치한다.
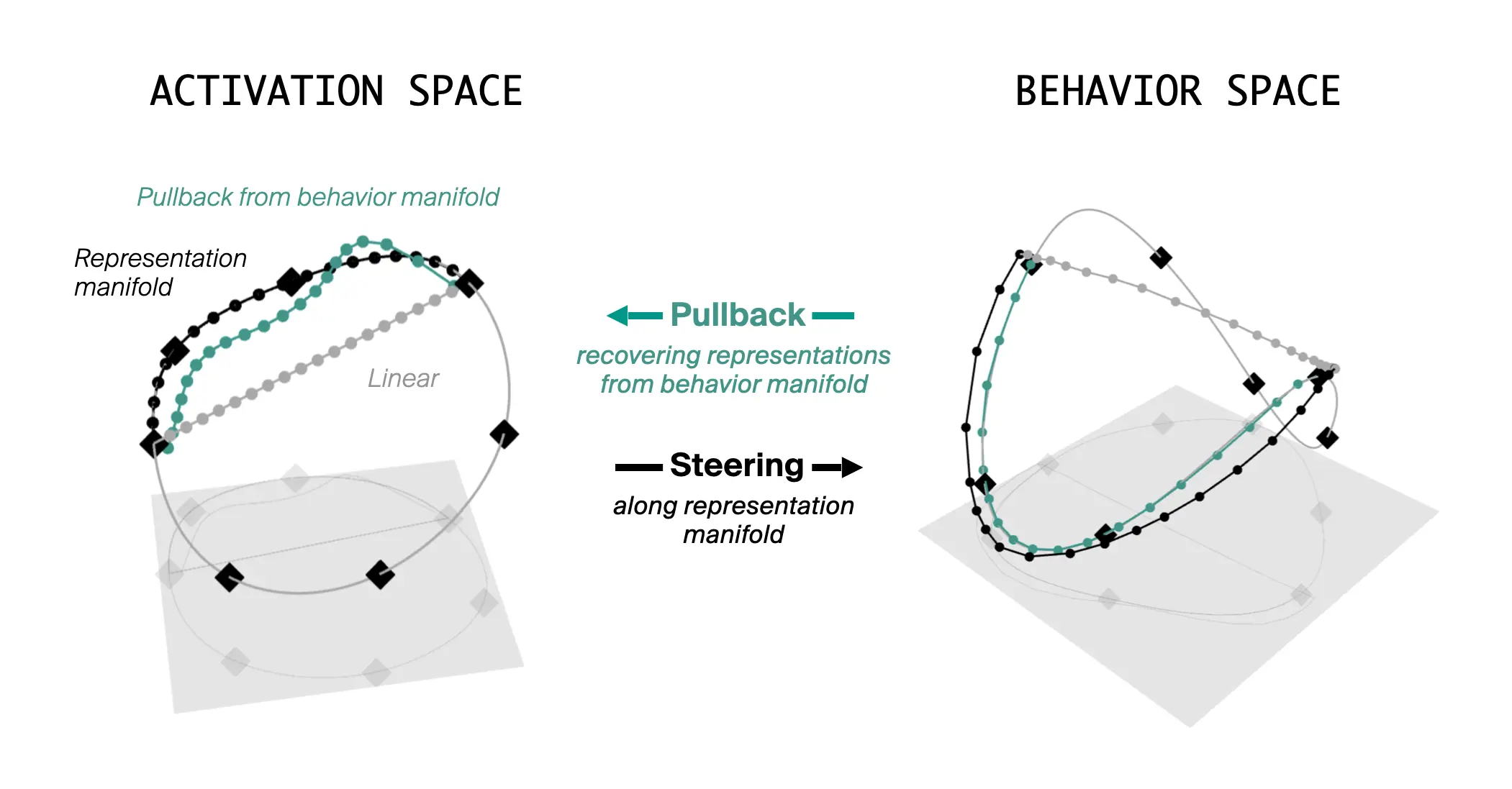
출처: Goodfire, Steering Along Manifolds to Control Neural Networks (2026-05-07). 검정: 표상(활성) 매니폴드를 따른 경로. 청록: 행동 매니폴드를 활성 공간에 매핑한 경로. 회색: 활성 공간의 직선 경로. 원본: https://static.goodfire.ai/manifold-steering/pullback-steering.webp
{kind=link}
저자들이 직접 강조하는 함의는 다음과 같다.
“representation geometry and behavior geometry need not align at all… Instead, we find a precise correspondence: the structures models use internally are reflected in what they do externally.”
이론적으로는 활성 공간을 가로지르는 경로가 행동에 무관한 변화를 만들어도 이상하지 않다. 그런데 Llama에서는 두 기하가 정확히 대응한다. 모델의 외양은 모델 내부의 거울이라는 경험적 증거다.
일반화 — 요일을 넘어
요일은 깨끗한 사례일 뿐이다. 풀 페이퍼는3 같은 매니폴드 대응이 다른 도메인에서도 재현됨을 보고한다.
- 언어 모델: 월(months), 글자, 나이, 사전 정의된 기하의 합성 ICL 태스크.
- 다른 모달리티: 시리즈 첫 글의 mountain car 후속으로, 차의 위치를 예측하는 image-action 모델.
매니폴드 기하는 요일에 국한된 우연이 아니라, 모델 행동을 제어하는 실용적 청사진이라는 결론이다.
가장 흥미로운 지점 — 외부 지문
내가 가장 길게 곱씹은 부분은 양방향 일치다. 표상 기하와 행동 기하는 사전적으로 정렬될 이유가 없는데도 Llama에서는 정확히 대응한다. 학습 데이터의 통계 구조가 모델의 안과 밖에 같은 기하를 새겼기 때문이다.
이 점이 흥미로운 이유는 함의의 방향에 있다. 보통 해석가능성 연구는 가중치와 활성에 직접 접근할 수 있는 모델을 가정한다. 그런데 행동 기하가 표상 기하의 외부 지문이라면, 충분히 다양한 행동 측정을 매니폴드 도구로 분석하는 것만으로 모델 내부 기하를 역추적할 가능성이 열린다. 폐쇄형 API 모델의 해석가능성 연구가 비현실적인 야망에서 한 걸음 가까이 다가온다.
다만 전제가 있다. 행동을 직선으로 보면 이 지문은 보이지 않는다. 직선 스티어링이 노이즈를 내듯, 직선 척도로 행동을 측정하면 매니폴드의 곡률이 평탄화되어 사라진다. 도구를 매니폴드에 맞추는 것이 곧 관찰의 자격이다.
“Representation geometry is a window into the inner world of neural networks.”
창은 안에서 밖으로만 열리는 게 아니다. 이 글은 밖에서 안을 들여다보는 창의 가능성도 함께 열어둔다.
출처
발신: Goodfire (Stanford, UCL, Northeastern, Harvard, Technion 협력) 저자: Daniel Wurgaft·Can Rager·Matthew Kowal·Vasudev Shyam·Sheridan Feucht·Usha Bhalla·Tal Haklay·Eric Bigelow·Raphaël Sarfati·Thomas McGrath·Owen Lewis·Jack Merullo·Noah Goodman·Thomas Fel·Atticus Geiger·Ekdeep Singh Lubana 발표: 2026-05-07 시리즈 첫 글 다이제스트: The World Inside Neural Networks