Goodfire AI · Research · 2026년 5월 14일 신경 기하학 시리즈(Neural Geometry Series)의 한 편.1
3줄 요약
- Goodfire 연구진이 Llama 3.1 8B의 레이어 18에서 범용 덧셈 모듈을 발견했다. 모델은 숫자를 직선이 아니라 여러 모듈러 원의 좌표 — 푸리에 특징 — 로 인코딩한다.2
- 같은 모듈이 산술뿐 아니라 “금요일에서 이틀 뒤”, “8월에서 6개월 뒤” 같은 순환 개념 과제에서도 재사용된다. 정보 흐름 추적으로 회로를 식별하고, 활성화 조작(steering)으로 인과적 역할을 검증했다.3
- 표현(어디에 인코딩되는가)뿐 아니라 연산(그 위에서 무엇이 일어나는가)까지 추적해야 모델 행동을 설명·디버깅·제어할 수 있다는 것이 신경 기하학 어젠다의 핵심 주장이다.
도입 — Llama는 월을 어떻게 더하는가
지금이 8월이고 6개월 뒤 약속을 잡아야 한다고 하자. 사람은 보통 8월·9월·10월·11월·12월·1월·2월처럼 차례로 세거나, 머릿속에 월이 원형으로 배치된 그림을 떠올려 2월을 짚는다.
Llama 3.1 8B는 두 전략 모두 쓰지 않는다. 모델은 단일 forward pass 안에서 다음을 수행한다.
- August를 숫자 8로 변환한다.
- 8 + 6 = 14를 원형 표현 위에서 계산한다.
- 결과를 다시 February로 되돌린다.
각 숫자는 활성화 공간 위에 원을 그리는 푸리에 특징으로 표현된다. 사람의 멘탈 이미지와 모양은 닮았지만, 모델이 그 위에서 수행하는 것은 모듈러 산술이다.
범용 덧셈 모듈 — 레이어 18에 단일 메커니즘
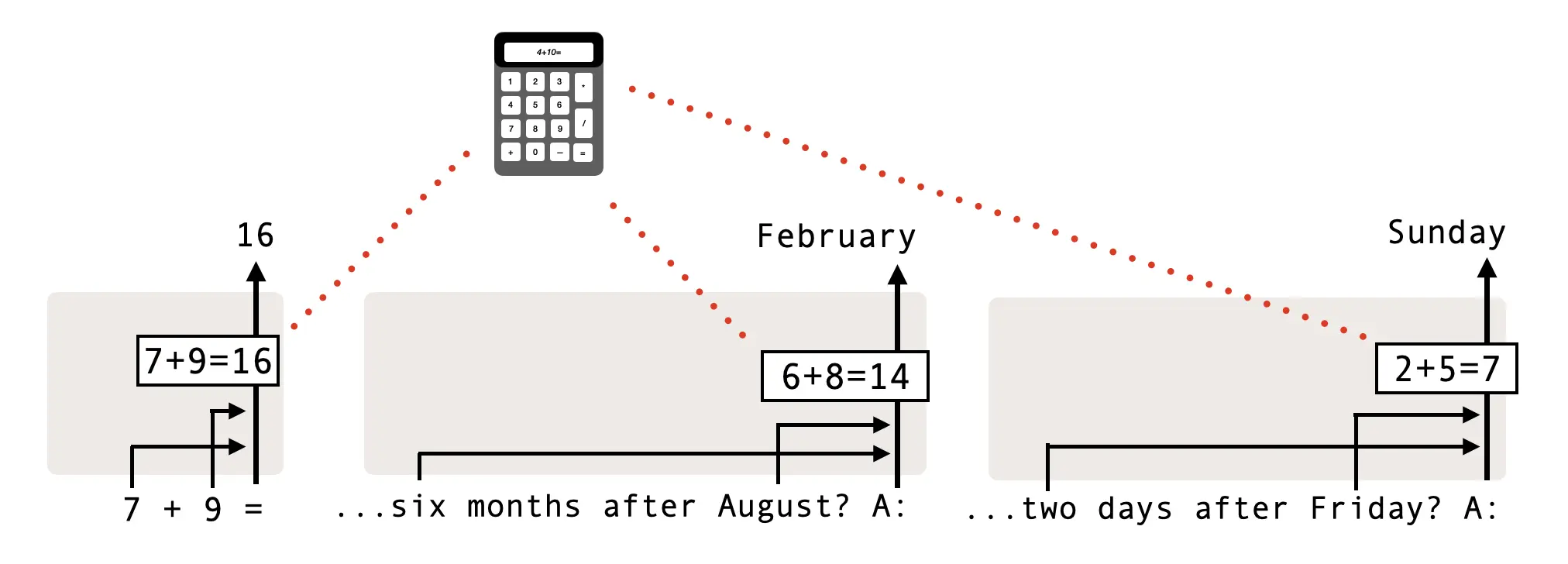
연구진은 정보 흐름을 레이어와 토큰 위치에 걸쳐 추적한 끝에 덧셈 모듈을 레이어 18에서 식별했다. 단일 모듈이 다음과 같은 서로 다른 과제에 동일하게 쓰인다.
- 산술: “7 + 9는?”
- 요일: “금요일에서 이틀 뒤는 무슨 요일인가?”
- 월: “8월에서 6개월 뒤는 몇 월인가?”
공유 사실은 단순 관찰이 아니라 인과 검증으로 뒷받침된다. 모듈에 개입하면 세 과제의 출력이 함께 영향을 받는다.
왜 모델은 별도 회로를 두지 않고 하나로 처리할까. 연구진의 해석은 파라미터 압박이다. 학습 중 사용할 수 있는 파라미터 수는 유한하므로, 구조적으로 비슷한 과제들은 기존 회로를 공유하도록 최적화 압박이 작동한다. 산술과 순환 개념은 모두 모듈러 덧셈이라는 구조를 공유하기 때문에 같은 모듈이 형성된다.
숫자를 원으로 표현하는 법

Figure from Kantamneni & Tegmark (2025). GPT-J encodes numbers on circles.
언어 모델이 숫자를 표현하는 방식은 직관과 어긋난다. 활성화 공간 안에 1, 2, 3, … 이 직선으로 나열된 *내부 자(internal ruler)*도 아니고, 컴퓨터처럼 이진수도 아니다.
LLM은 숫자를 여러 개의 모듈러 원의 좌표 집합으로 인코딩한다. 각 원은 “숫자 modulo k"에 해당한다.
예를 들어 17은 다음 네 좌표의 집합으로 표현된다.
| 원 | 좌표 |
|---|---|
| mod-2 | 1 |
| mod-5 | 2 |
| mod-10 | 7 |
| mod-100 | 17 |
이는 잉여수 체계(residue number system)의 변형에 해당한다 — 다만 모듈러 값들이 서로 소(coprime)일 필요는 없다.
왜 큰 원 하나로 끝내지 않는가
mod-100 원만으로도 1부터 100까지 모든 숫자를 표현할 수 있다. 그런데도 mod-2, mod-5, mod-10이 함께 존재하는 이유는 정밀도에 있다.
큰 원에서는 16, 17, 18이 거의 같은 위치에 놓인다. 이 상태에서는 16과 17을 구분하기 어렵다. mod-2 원의 짝/홀 좌표가 이들을 떼어놓고, mod-5가 한 번 더 떼어놓는다. 베버-페히너 법칙처럼 큰 양은 흐릿하고 작은 양은 정밀한 표현 위계가 자연스럽게 생긴다.
푸리에 분해라는 수학적 근거
여러 주기의 원으로 숫자를 표현하는 방식은 푸리에 분해와 동형이다. 임의 함수를 주기 함수로 분해하는 익숙한 수학 도구가, 신경망 학습 과정에서 자연스럽게 떠올라 GPT-J, Llama 등 서로 다른 LLM에서 독립적으로 관측된다. 본 자료의 각주는 Nanda et al. (2023), Zhong et al. (2023), Zhou et al. (2024, 2025), Kantamneni & Tegmark (2025), Levy & Geva (2025), Fu et al. (2026) 등 일곱 개의 선행 연구를 인용한다.
모듈은 어떻게 더하는가
덧셈 모듈은 큰 덧셈을 한 번에 풀지 않는다. 대신 각 원의 주기에 맞는 작은 모듈러 덧셈을 병렬로 푼다.
6 + 8을 예로 들면:
(6 mod 2) + (8 mod 2) = 0 + 0 = 0 (mod 2)
(6 mod 5) + (8 mod 5) = 1 + 3 = 4 (mod 5)
(6 mod 10) + (8 mod 10) = 6 + 8 = 4 (mod 10)
각 원이 자기 주기에 맞는 답 좌표를 만들고, 그 좌표들이 모이면 정답 14가 된다. 큰 문제를 작은 부분 문제로 쪼개 동시에 푸는 모듈러 덧셈 아키텍처가 활성화 공간 안에 자리잡아 있다.
Steering — 모듈의 인과적 역할 검증
관찰만으로는 부족하다. 모듈이 단지 상관된 활성화일 가능성을 배제할 수 없다.
연구진은 원들의 좌표를 직접 조작(steering)했다. “8월에서 16개월 뒤는 무슨 월인가"라는 질문에 답하는 동안 덧셈 모듈의 출력 좌표를 슬라이더로 다른 월에 해당하는 위치로 옮기면, 모델의 최종 토큰 예측이 그에 맞춰 바뀐다.
자료는 한 가지 한계를 정직하게 인정한다: steering의 진폭을 자연 발생값보다 수 배 키워 효과를 또렷이 만들었다. 결과는 설득력 있지만 완결된 그림은 아니며, 후속 연구가 양적으로 채워야 한다고 적어두었다.
뉴런 수준의 모듈러 분업
덧셈 모듈을 구성하는 개별 뉴런도 자신이 다루는 원의 주기로 깔끔히 갈린다. 어떤 뉴런은 mod-2 부분 문제에만, 어떤 뉴런은 mod-5에만 반응한다. 그리고 같은 뉴런이 산술·요일·월 과제에 걸쳐 거의 동일한 발화 패턴을 보인다.
모듈러 분업이 거시 회로뿐 아니라 미시 뉴런까지 일관되게 나타난다는 점이, 이 모듈을 단순한 시각화 패턴이 아니라 모델의 계산 단위로 받아들이게 만든다.
신경 기하학 어젠다

자료의 결론은 두 문장으로 요약된다.
Neural networks do not merely store geometric representations of concepts; they perform computations using them.
차원 축소로 그려진 원형 매니폴드는 흔히 “보기 좋은 그림"으로 치부된다. 그러나 그 원들을 조작하면 모델 출력이 함께 움직인다. 활성화 공간의 기하학은 사후 시각화의 부산물이 아니라, 모델이 실제 계산에 사용하는 객체다.
기존 해석가능성 연구는 표현(어떤 개념이 어디에 인코딩되는가)에 집중해 왔다. 이 연구가 더하는 한 걸음은 그 표현 위에서 어떤 연산이 일어나는지까지 추적하는 일이다. 표현과 연산을 함께 보아야 모델 행동을 설명할 수 있고, 디버깅할 수 있고, 통제할 수 있다 — 이것이 신경 기하학 어젠다의 중심 주장이다.
가장 흥미로운 지점
내가 가장 흥미로웠던 부분은 모듈 재사용을 유도한 것이 학습 압박이라는 설명이다. 사람의 “월을 원으로 떠올린다"는 직관은 비유에 가깝지만, 모델에게 원형 표현은 비유가 아니라 파라미터 절약의 귀결이다. 산술·요일·월이 같은 모듈러 구조를 공유하기 때문에 학습이 자연히 회로를 한 곳으로 모은다.
다른 한편 자료가 인정한 steering 진폭 증폭은 정직한 한계 표시로 읽힌다. 인과 검증의 강도와 자연 동작의 충실도가 곧장 일치하지는 않으므로, 후속 연구가 더 부드러운 개입으로도 같은 결과를 얻어내는 단계에 도달해야 그림이 완결될 것이다.
출처
- 저자: Sheridan Feucht, Ekdeep Singh Lubana, Tal Haklay, Thomas Fel, Usha Bhalla, Atticus Geiger, Daniel Wurgaft, Can Rager, Raphaël Sarfati, Jack Merullo, Thomas McGrath, Owen Lewis (Goodfire · Northeastern · Technion IIT · Harvard · Stanford)
- 발행: 2026년 5월 14일
- 원문: https://www.goodfire.ai/research/a-geometric-calculator