William Harding · GitClear / Alloy.dev Research · 2025.02
3줄 요약
- GitClear의 William Harding이 2025년 2월에 발행한 코드 품질 보고서다. 2020년 1월부터 2024년 12월까지 약 1만 개 리포 (Chromium·React·VS Code 등 25+개 오픈소스 + 비공개 기업 데이터)에서 의미 있는 211M 라인의 변경을 7가지 코드 연산으로 분류해 측정하였다.
- 핵심 발견 셋. (a) 변경 라인 중 Moved(이동·재배치, 즉 리팩토링의 시그니처)는 2021년 25%에서 2024년 9.5%로 반토막 이상 감소. (b) 같은 기간 Copy/Pasted는 8.3%에서 12.3%로 상승, 2024년에 처음으로 Moved를 추월. (c) 5라인 이상 중복 블록을 포함한 commit 비율은 2022년 0.45%에서 2024년 6.66%로 2년 만에 10배 증가하였다.
- 동시대의 Google DORA 2024 보고서(39,000명 응답)는 회귀 모델로 “AI 채택률 25% 증가 → 소프트웨어 전달 안정성 7.2% 감소"를 추정하여 GitClear의 진단을 외부 데이터로 받친다. 결론은 한 줄. AI가 강해질수록 인간 개발자에게 남는 우위는 이해한 코드를 단순화·통합하는 능력이다.
자료의 위치
저자는 GitClear의 CEO이자 Alloy.dev Research 리드 리서처 William Harding.1 본문 33페이지. 2025년 2월 발행, 보고서 버전 v2025.2.5. 부제는 Evaluating 2024’s Increased Defect Rate via Code Quality Metrics — 211m lines of analyzed code + projections for 2025이다.
본 자료는 GitClear의 2024년 1월 보고서 Coding on Copilot: 2023 Data Suggests Downward Pressure on Code Quality의 후속편이다. 2024년 보고서는 “결함률이 오를 것"이라 예측하였고, 같은 해 10월 발표된 Google DORA 2024가 그 예측을 데이터로 확인하였다. 본 2025년판은 예측이 빗나갔다면 어떻게 되었을까가 아니라 얼마나 더 빠르게 빗나갔는가를 다룬다.
211M 라인이라는 표본
GitClear는 2020년부터 자체 분류 엔진으로 약 10억 라인의 코드 변경을 분류하였고, 그 중 의미 있는(non-No-op) 211M 라인을 본 분석에 사용하였다. 표본 구성은 다음과 같다.
- 약 2/3는 익명화 동의를 한 비공개 기업 (NextGen Health, Bank of Georgia 등)
- 약 1/3은 오픈소스 — Chromium, Facebook React, VS Code, React Native, Postgres, Kubernetes, Signal, Jax, TensorFlow, Swift, Ruby, Go, Clickhouse, Babel, Standard Notes, Electron, TimescaleDB, Bluesky atproto, Elasticsearch, MS Powertoys, Ruby on Rails, Homebrew, Python(cpython), Ansible 외 약 80개
자동 생성 파일·서브리포 commit은 제외되었다. Stack Overflow 2024 개발자 설문 결과 — 전문 개발자의 63%가 이미 AI를 도입, 14%가 도입 예정 — 시점에서 측정된 실제 코드 거동이라는 점이 표본의 의미다.
7가지 코드 변경 연산이라는 분류
대부분의 git 통계 도구(GitHub·GitLab·Bitbucket·SonarQube)는 변경을 추가/삭제 이진으로만 분류한다. GitClear는 이를 일곱 가지로 세분한다.
| 연산 | 정의 |
|---|---|
| Added | 기존 라인의 점진적 변형이 아닌 새로 작성된 라인 |
| Deleted | 제거 후 2주 내 재추가되지 않은 라인 |
| Updated | 기존 라인을 ~3 단어 이하로 수정 |
| Moved | 같은 내용 그대로 다른 파일·함수로 이동 (리팩토링의 시그니처) |
| Find/Replaced | 같은 문자열을 3+ 위치에서 일관된 대체 (린터 자동 수정 등) |
| Copy/Pasted | 같은 commit 안에서 비키워드·비주석 라인이 다른 파일·함수에 복제 |
| No-op | 공백·줄번호 변경 (분석 제외) |
이 세분이 본 보고서의 분석력을 만든다. “코드가 늘었다"가 아니라 “어떻게 늘었는가"를 측정할 수 있게 되어 있다.
2020~2024 트렌드 — 그리고 2025 예측
전체 변경 라인의 연산별 분포다.
| 연도 | Added | Deleted | Updated | Moved | Copy/pasted | Find/replaced | Churn |
|---|---|---|---|---|---|---|---|
| 2020 | 39.2% | 19.1% | 5.2% | 24.1% | 8.3% | 2.9% | 3.1% |
| 2021 | 39.5% | 19.3% | 5.0% | 24.8% | 8.4% | 3.4% | 3.3% |
| 2022 | 40.9% | 19.8% | 5.2% | 20.5% | 9.4% | 3.7% | 3.3% |
| 2023 | 42.3% | 21.1% | 5.6% | 15.8% | 10.6% | 3.6% | 4.5% |
| 2024 예측 | 43.6% | 22.1% | 5.8% | 13.4% | 11.6% | 3.6% | 7.1% |
| 2024 실측 | 46.2% | 21.9% | 5.9% | 9.5% | 12.3% | 4.2% | 5.7% |
| YoY 변화 | +9.2% | +3.8% | +7.2% | −39.9% | +17.1% | +16.7% | +26% |
| 2025 예측 | 49.3% | 23.0% | 6.3% | 3.1% | 13.9% | 4.4% | 6.9% |
저자는 2024년 1월에 자기들이 예측한 11.6% Copy/Paste보다 실측이 6% 더 빠르게 자랐다는 점을 본문 첫머리에서 짚는다. 방향은 맞췄으되 속도는 과소평가하였다는 자각이다.
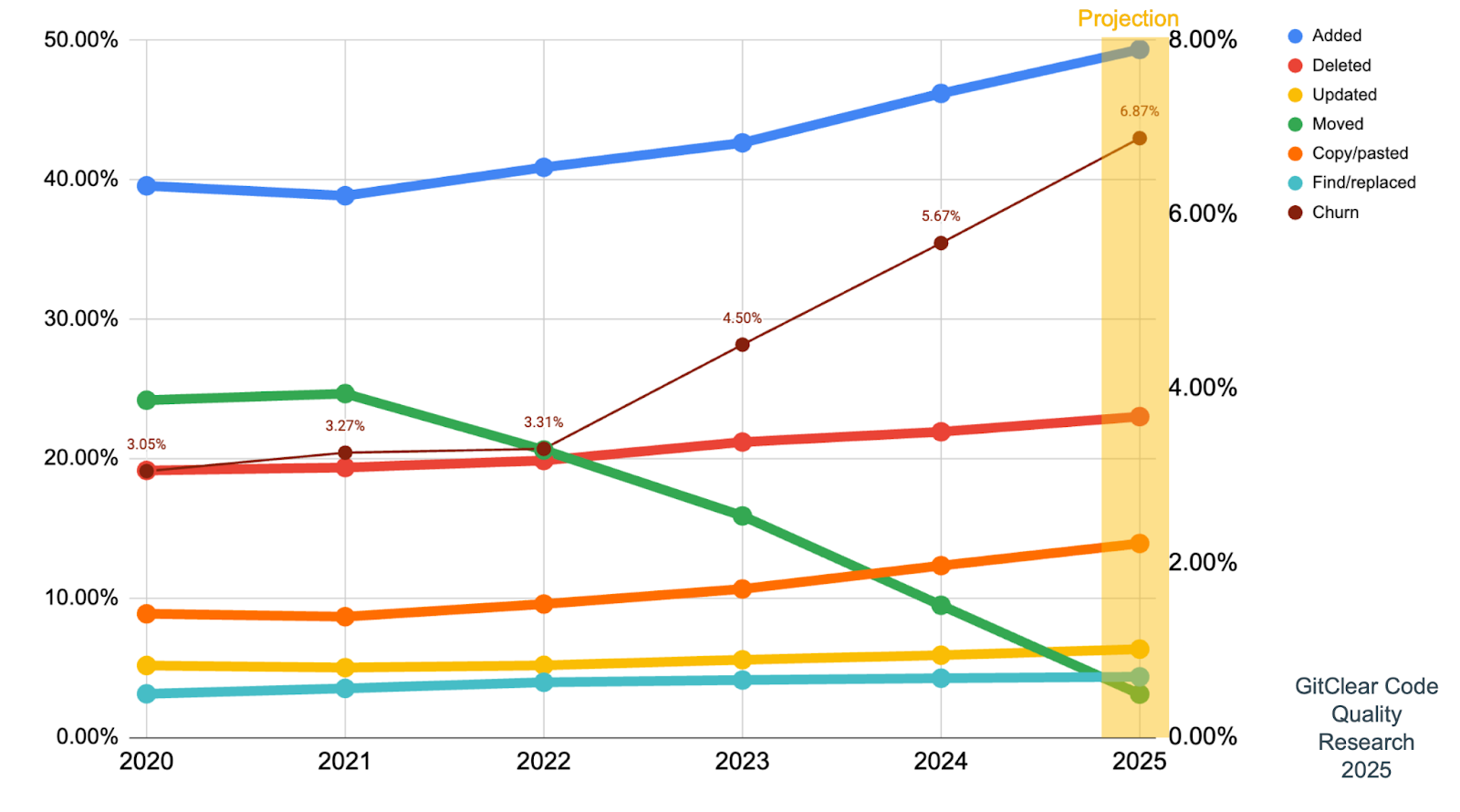 연도별 코드 연산 분포. 노란 영역은 2025 예측 구간.
연도별 코드 연산 분포. 노란 영역은 2025 예측 구간.
“Moved” 코드의 멸종 위기
GitClear는 Moved 연산의 급락을 본 보고서의 가장 심각한 신호로 취급한다. 직접 인용하자면.
컨텍스트 윈도우 크기를 탓해도 좋다. UI의 한계를 탓해도 좋다. 그러나 어떤 근접 원인을 들든, 2024년 시점에서 인간 프로그래머가 AI 코드 어시스턴트에 대해 주장할 수 있는 본질적 우위는 이전 작업을 재사용 가능한 모듈로 통합하는 능력이다.
리팩토링된 시스템과 이동된 코드는 코드 재사용의 시그니처다. 코드를 재사용하면 새 팀원이 학습할 개념(과 함정)이 줄고, 시스템이 새 호출자에게 사용될 때마다 테스트·문서 인프라가 누적된다. 이 활동이 4년 만에 반토막 이상 줄었다.
또한 저자는 자기 가설을 반증할 수 있는 가장 자연스러운 대안 가설을 미리 처리한다 — 재택근무로 협업이 줄어 코드 재사용이 줄었다는 식의 설명이다. 그러나 2024년에는 재택 의무 해제(back-to-office)가 광범위하게 진행되었고, 그 해에 Moved는 16.9%에서 9.5%로 44% 더 떨어졌다. “같은 방에 있어도 reuse는 줄어드는” 추세가 확인된 셈이다.
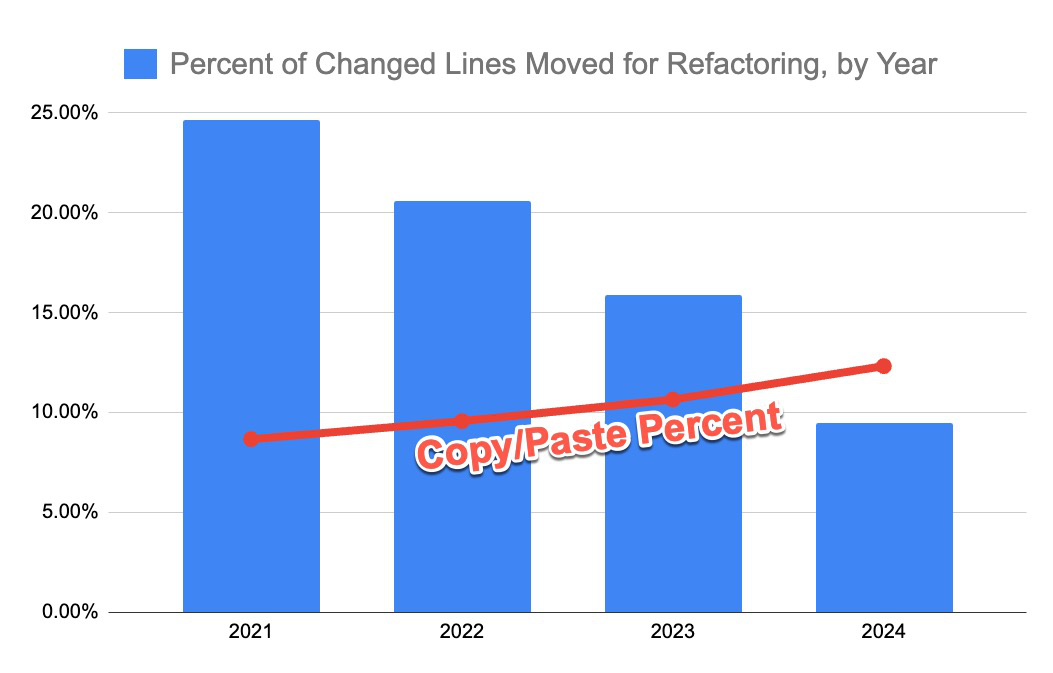 Moved(파랑)는 25%대에서 9.5%대로 하강. Copy/Paste(빨강)는 8.3%대에서 12.3%대로 상승.
Moved(파랑)는 25%대에서 9.5%대로 하강. Copy/Paste(빨강)는 8.3%대에서 12.3%대로 상승.
2024 — Copy/Paste가 처음으로 Moved를 추월하다
본 보고서가 강조하는 단일 사건이다. 2024년은 GitClear가 측정해 온 5년 가운데 Copy/Pasted 라인이 Moved 라인을 추월한 첫 해다.
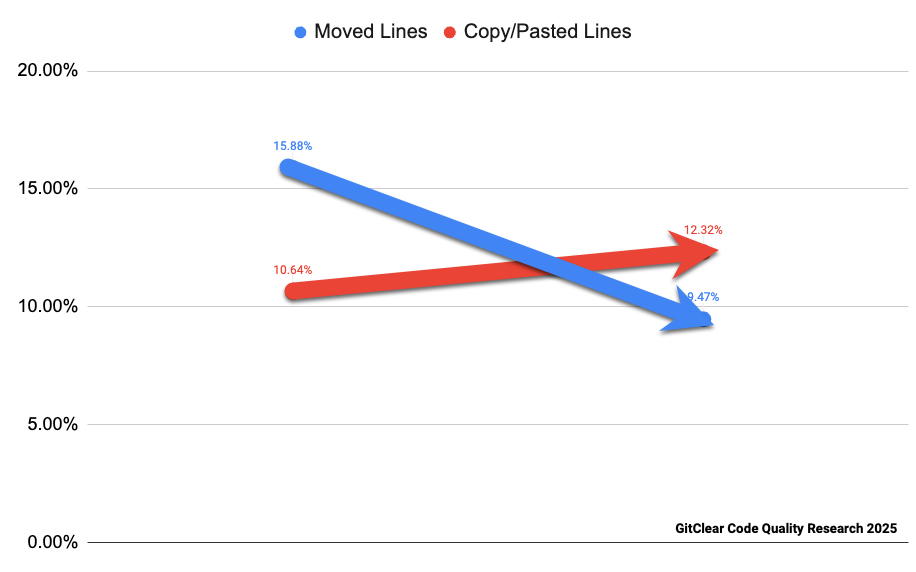 추월의 한 장면. 2024년에 두 곡선이 교차한다.
추월의 한 장면. 2024년에 두 곡선이 교차한다.
저자의 진단은 단호하다.
현재 형태의 AI 어시스턴트는 우리를 더 생산적으로 만들지만, 그 대가로 우리(또는 동료)를 반복하게 만든다. 본인도 그 사실을 모르는 채로 말이다. 리팩토링하여 DRY(Don’t Repeat Yourself)로 가는 대신, 우리는 끊임없이 복제의 유혹에 빠진다.
중복 블록 commit 비율 — 2년 만에 10배
GitClear는 본 보고서에서 처음으로 5라인 이상 연속된 중복 블록을 직접 검출하는 인프라를 도입하였다. 결과 표는 다음과 같다.
| 연도 | 스캔한 commit | 중복 블록 총수 | 중복 포함 commit | 중복 블록 % | 중복 블록 중간값 크기 |
|---|---|---|---|---|---|
| 2020 | 19,805 | 9,227 | 139 | 0.70% | 10 |
| 2021 | 29,912 | 9,295 | 143 | 0.48% | 11 |
| 2022 | 40,010 | 10,685 | 182 | 0.45% | 11 |
| 2023 | 41,561 | 20,448 | 747 | 1.80% | 10 |
| 2024 | 56,495 | 63,566 | 3,764 | 6.66% | 10 |
2년 전 대비 약 10배. 1년 전 대비 3.7배. 측정 인프라의 정의 변경이 아니라 같은 기준으로 측정한 비율이라는 점이 핵심이다.
저자는 왜 이 시점에 이런 도약이 일어났는가에 대한 가설로 컨텍스트 윈도우 한계를 든다. 2024년에 가장 인기 있던 코드 어시스턴트의 컨텍스트는 약 10개 파일에 한정되었다. 즉 AI는 인접 코드를 생성할 수 있지만, 리포의 다른 곳에 이미 동일 함수가 존재한다는 사실을 기억하지는 못한다. 탭 한 번에 새 라인이 생기는 UI는 이 경향을 더욱 가속한다.
저자가 더 강조하는 비용은 중복 블록 자체가 아니라 그것이 만드는 propagation 부담이다.
단순한 Jira 한 건이 해당 코드 블록을 중복하고 있는 리포의 모든 시스템을 이해해야 하는 작업으로 부풀어 오른다. 개발자가 친숙하지 않은 시스템들로 부풀어 오르는 부담은, 동료에게도 임원에게도 가시화되지 않는다.
학술 보강 — Mo·Zhang(2023)의 클론과 버그
GitClear는 중복이 곧 버그를 부른다는 직관에 학술적 근거를 댄다. ACM 2023의 Exploring the Impact of Code Clones on Deep Learning Software(Ran Mo·Yao Zhang 외)2가 핵심 인용이다. 핵심 결과 셋이다.
- 딥러닝 프로젝트의 *코드 조각 16.3%*가 클론을 포함 — 전통 소프트웨어의 약 두 배
- 3,113쌍의 공동 변경된 클론을 분석한 결과, 57.1%가 버그에 관여
- 34개 DL 프로젝트 중 *28개(82.4%)*에서 공동 변경된 클론이 버그에 관여
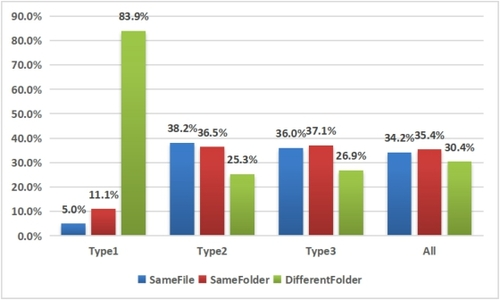 Type 1(완전 동일)은 다른 폴더에 압도적으로 많고(83.9%), Type 2·3(이름·일부 변형)은 같은 파일/폴더/다른 폴더에 비교적 고르게 분포한다.
Type 1(완전 동일)은 다른 폴더에 압도적으로 많고(83.9%), Type 2·3(이름·일부 변형)은 같은 파일/폴더/다른 폴더에 비교적 고르게 분포한다.
GitClear의 인용 의도는 분명하다. 코드 중복은 단순한 스타일 위반이 아니라 결함률 베이스라인을 끌어올리는 메커니즘이며, 2022년 이후 관측된 결함률 상승의 일부를 직접 설명한다.
외부 검증 — Google DORA 2024
본 보고서는 자기 데이터의 정합성을 외부 데이터로도 확인한다. Google DORA 2024 보고서(39,000명 응답)3가 핵심 비교 대상이다. 이 보고서의 자체 회귀 모델은 다음을 추정한다.
- AI 채택률 25% 증가 → Delivery Stability 7.2% 감소
- 같은 자극 → Delivery Throughput 1.5% 감소
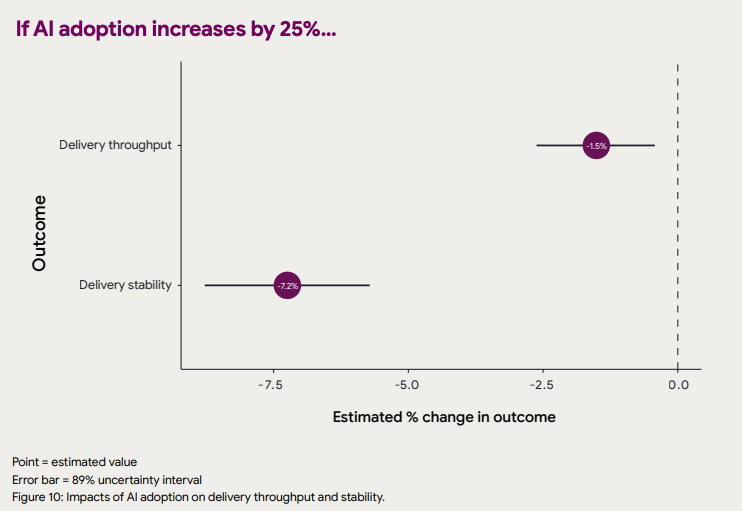 89% 신뢰 구간 막대. 두 지표 모두 감소 방향으로만 분포한다.
89% 신뢰 구간 막대. 두 지표 모두 감소 방향으로만 분포한다.
Google 측의 표현은 다음과 같다.
AI 채택은 일부 부정적 영향을 동반한다. 우리는 소프트웨어 전달 성능의 감소를 관찰하였고, 제품 성능에 대한 효과는 불확실하다.
흥미로운 부분은 인지와 측정의 어긋남이다. 같은 설문에서 개발자들은 AI 덕에 생산성이 “약간”·“보통”·“매우” 올랐다고 응답하였다(긍정 응답이 압도적). 그러나 AI 생성 코드를 신뢰하는가 항목에서는 중앙값이 “Somewhat"에 머물렀다.
 “매우 신뢰” 응답이 가장 적고, “그럭저럭"이 정점.
“매우 신뢰” 응답이 가장 적고, “그럭저럭"이 정점.
GitClear는 이 인지·측정 어긋남을 다음과 같이 화해시킨다.
개발자들이 리팩토링을 클로닝으로 바꾸는 비율이 우리가 관측한 정도라면, 그 결과는 “더 많은 코드(가난한 자의 생산성)“가 “증가하는 유지보수 부담"과 묶여서 나오는 것이다 — 이 부담이 일부는 결함률 상승으로 표현된다.
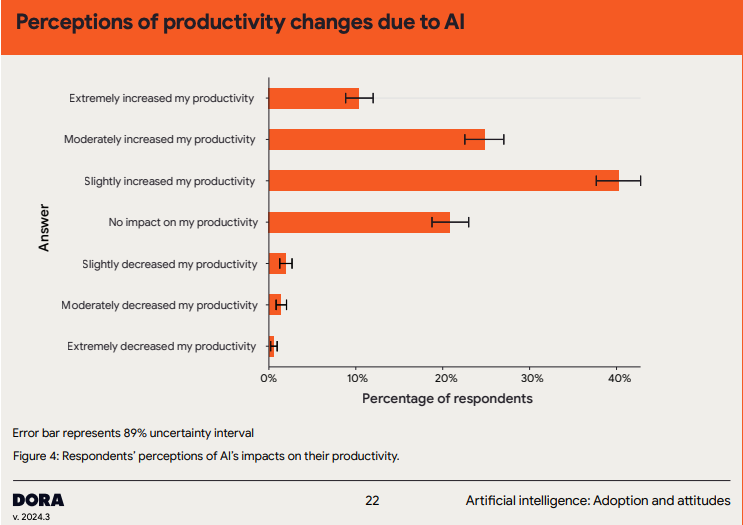 개발자 본인의 인식 측에서는 AI가 “도움이 된다"가 압도적이다.
개발자 본인의 인식 측에서는 AI가 “도움이 된다"가 압도적이다.
코드의 나이도 변하였다
또 다른 측정 축이 있다. 수정되는 코드가 얼마나 오래된 것인가이다.
| 연도 | 2주 이하 | 2-4주 | 1개월 이하 | 1년 이하 | 1~2년 | 2년 이상 |
|---|---|---|---|---|---|---|
| 2020 | 60.4% | 9.6% | 70.0% | 24.7% | 4.2% | 1.1% |
| 2021 | 61.1% | 9.3% | 70.4% | 24.2% | 4.7% | 0.7% |
| 2022 | 57.5% | 9.8% | 67.3% | 25.4% | 6.5% | 0.8% |
| 2023 | 60.6% | 10.6% | 71.2% | 21.9% | 6.2% | 0.8% |
| 2024 | 69.7% | 9.5% | 79.2% | 16.9% | 2.6% | 1.3% |
2024년에 수정된 라인 중 80%가 작성된 지 1개월 이내이고, 1~2년 된 라인을 손보는 비율은 6.2%에서 2.6%로 반 이상 줄었다.
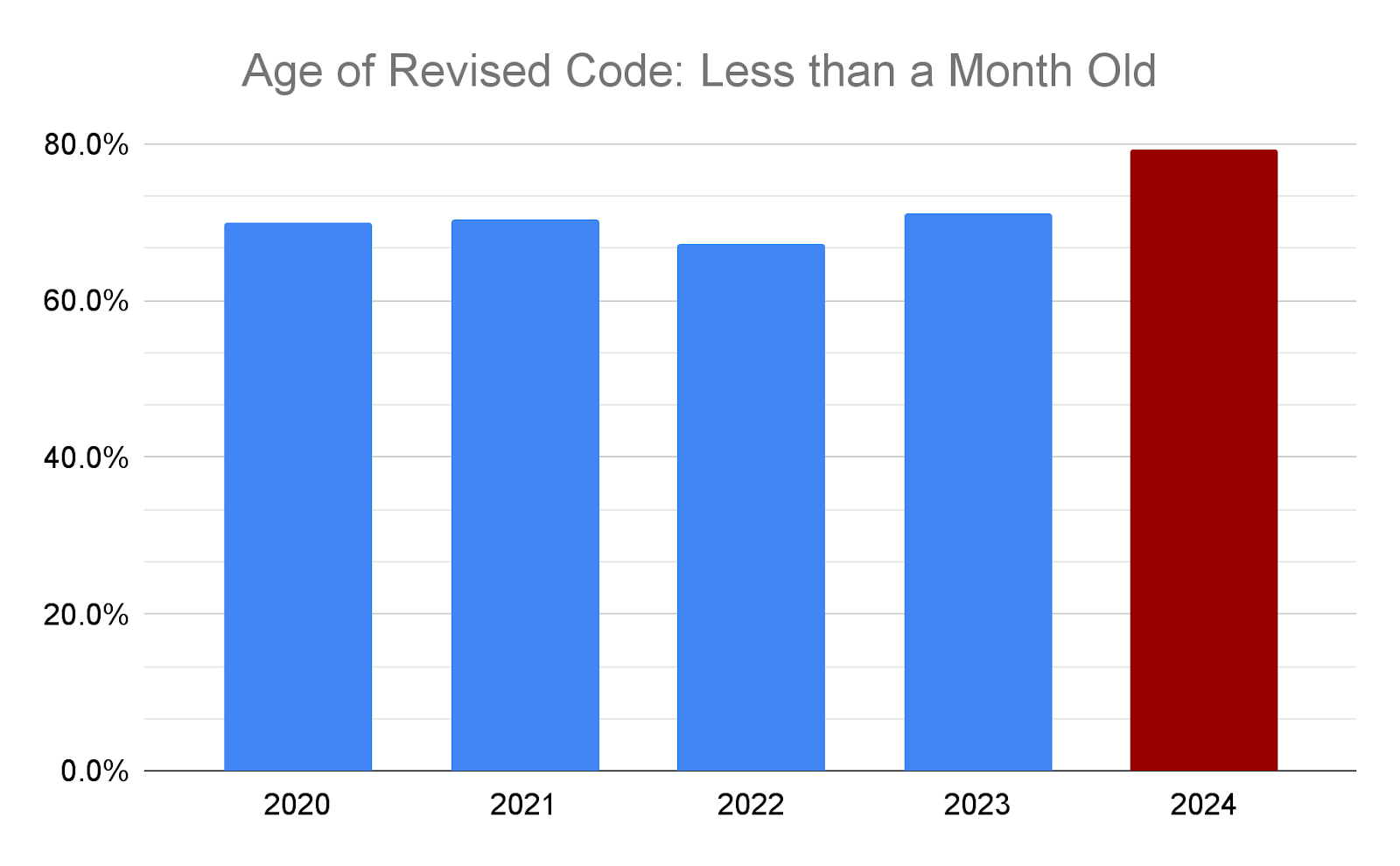 4년간 67~71% 사이에서 안정적이던 비율이 2024년에 79.2%로 도약한다.
4년간 67~71% 사이에서 안정적이던 비율이 2024년에 79.2%로 도약한다.
이어서 새로 작성된 라인이 2주 또는 4주 안에 다시 수정되는 비율(churn)도 2021년 베이스라인 대비 2024년에 20~25% 증가하였다.
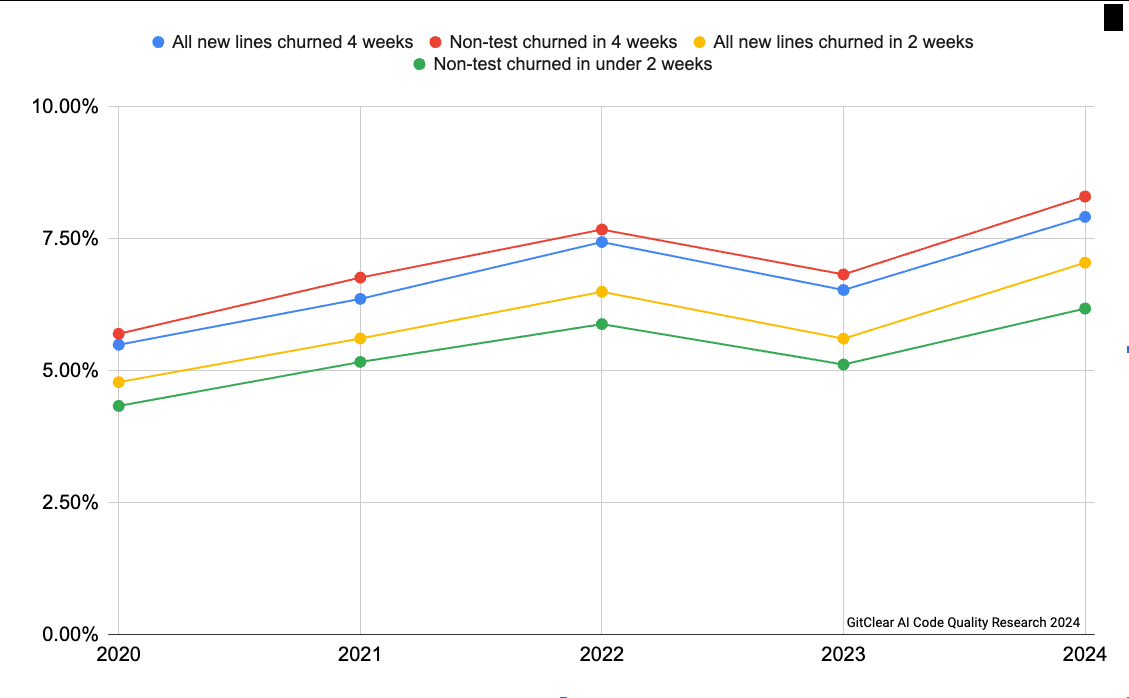 다듬는 코드의 손길이 최근 코드에 몰리는 동시에, 새로 쓴 코드가 더 자주 다시 수정된다.
다듬는 코드의 손길이 최근 코드에 몰리는 동시에, 새로 쓴 코드가 더 자주 다시 수정된다.
이는 기존 시스템을 다듬는 일에서 새로 만든 것을 다듬는 일로 노력의 무게중심이 이동했음을 시사한다. 저자의 표현으로는 모든 새 기능을 add 연산으로만 구현하면, 어떤 함수가 호출의 정본인지 판단하기가 점점 어려워지고, 신입을 받기가 점점 비싸진다.
결론 — 인간의 리팩토링 우위
GitClear의 결론은 간결하다.
어시스턴트가 계속 강해지더라도 인간에게는 뚜렷한 우위가 남는다.
저자가 임원과 개발자에게 권고하는 행동은 다음 한 줄이다.
개발자는 이해한 코드를 단순화하고 통합하는 자기만의 인간 능력을 강조해야 한다. 잘 명명되고 잘 문서화된 모듈을 만드는 데에는 art·skill·experience가 결합한다. AI 시대의 처리량을 극대화하려는 임원은 재사용을 인센티브화하는 새 방법을 발견할 것이다.
같은 보고서가 다른 자리에서 짚은 측정의 함정도 함께 받아두어야 한다. commit 수나 추가 라인 수로 생산성을 재면, AI는 큰 코드 블록을 복제하여 그 지표를 손쉽게 부풀린다. 티켓 해결 수나 보안 결함 없는 commit 수 같은 더 실질적인 지표조차 같은 방식으로 부풀릴 수 있다. 측정이 행동을 만든다는 Drucker의 명제가, AI 시대에는 더 정밀한 판본의 측정 체계를 요구한다.
핵심 함의
본 자료는 판단의 자가소진을 코드 라인 수준에서 정량화한다. CMR의 tacit knowledge 해자 논의와 IESE Enrique Ide의 OLG 모델(자동화의 손익분기 약 29~35년)이 경영학·학술 모델로 도달한 결론에, GitClear 데이터는 현장 측정값을 더한다. 4년 만에 Moved 비율이 절반 이상 사라지고 중복 블록이 2년 만에 10배 늘어나는 형태로 같은 추세가 관측된다.
지표별 부호도 함의가 분명하다. Find/Replace는 +17%, Moved는 −40%, 중복 블록은 +10배. AI IDE의 린터 자동 수정 덕에 행 단위 일관성은 개선되지만, 시스템적 통합과 재사용은 동시에 약화된다. 저자는 행 단위 일관성은 장기 유지보수성의 핵심 장애물이 아니다라고 단언한다. 풀린 영역과 풀리지 않은 영역의 경계가 데이터로 그어진 셈이다.
한계
본 자료가 스스로 인정하거나, 독자가 보충하여 짚어두어야 할 한계는 다음과 같다.
- 인과 분리의 제한. 211M 라인은 AI 도입의 결과인지, 같은 시기의 다른 변화(원격근무 확산·CI 변화·코드베이스의 자연 노화)의 결과인지 단정하기 어렵다. 저자는 back-to-office 가설은 데이터로 반증하였으되, 모든 교란 변수를 통제하지는 못한다.
- 표본 대표성. 211M 라인이 어떤 산업·기업 분포를 대표하는지가 명시되지 않았다. GitClear 사용 기업 표본의 편향이 있을 수 있다.
- 중복이 항상 나쁜가. 일부 중복은 마이크로서비스 경계나 의도된 분리에서 비롯될 수 있다. 저자는 공동 변경되는 클론이 가장 위험하다는 학술 증거(Mo·Zhang)를 인용해 이 한계를 부분적으로 좁힌다.
- 예측의 불확실성. 2024년 1월 예측이 11.6%였고 실측이 12.3%였다는 점은 방향성의 신뢰도를 높이지만, 같은 모델로 만든 2025년 예측(Moved 3.1%)은 가속이 계속된다는 가정 위에서 만들어진 외삽이다. 가속이 둔화될 가능성도 열려 있다.
이 네 한계를 인정해도, 같은 시기 Google DORA의 39,000명 응답·Mo·Zhang의 학술 결과·GitClear의 211M 라인이 세 메트릭이 같은 방향으로 이동한다는 사실은 우연으로 보기 어렵다.
William Harding (CEO, GitClear / Lead Researcher, Alloy.dev Research), AI Copilot Code Quality: 2025 Data Suggests 4x Growth in Code Clones (보고서 버전 v2025.2.5). GitClear, 2025년 2월. 원문: https://www.gitclear.com/ai_assistant_code_quality_2025_research. PDF: https://gitclear-public.s3.us-west-2.amazonaws.com/GitClear-AI-Copilot-Code-Quality-2025.pdf. 본 다이제스트의 도표 9장은 모두 이 보고서 PDF 본문에서 그대로 인용한 것이다. ↩︎
Mo, R., Zhang, Y., et al. (2023). Exploring the Impact of Code Clones on Deep Learning Software. ACM TOSEM. ↩︎
Google, DORA 2024 State of DevOps Report (39,000명 응답). https://dora.dev/research/2024/dora-report/. ↩︎