3줄 요약
- 2025~2026년 사이 BFL(독일)·바이트댄스(Seed)·알리바바(Tongyi-MAI)·智谱AI(ZhipuAI)가 잇따라 발표한 네 가지 이미지 생성 모델 — FLUX.2, Seedream, Z-Image, GLM-Image — 의 아키텍처를 VAE·Text Encoder·DiT 백본·학습 파이프라인 네 층으로 가로로 해부한다.
- 네 모델 모두 CLIP/T5 이중 인코더에서 LLM 단일 인코더로 이동하고, VAE 채널을 늘려 토큰당 표현력을 강화하며, 단일 스트림 DiT(Z-Image)·4D RoPE(FLUX.2)·AR+Diffusion 분리(GLM-Image)처럼 서로 다른 방향으로 갈라지고 있다.
- 정렬 학습도 CLIP 리워드에서 VLM 리워드로, 다시 DPO에서 GRPO(DanceGRPO·flow-GRPO)로 한 칸씩 옮겨가고 있어, DeepSeek R1의 방법론이 이미지 생성 영역에 본격 이식되고 있음을 보여준다.
1. 네 모델이 같은 시간대에 나온 이유
저자(Rocky Ding, 공중호 WeThinkIn 운영)는 도입부에서 한 가지 그림을 그린다. Stable Diffusion 시대의 “범용 베이스 + LoRA + ControlNet” 파이프라인이 GPT-4o·Nano Banana·Seedream 같은 End-to-End 멀티모달 모델에 의해 빠르게 재편되고 있다는 진단이다. 그 위에서 2025년 하반기~2026년 초에 나온 네 모델은 같은 문제(텍스트 충실도·캐릭터 일관성·고해상도 효율)에 대한 서로 다른 답이라고 본다.
저자가 정렬한 자료 링크는 다음과 같다.
- FLUX.2 — 공식 페이지 · GitHub · HuggingFace
- Seedream — 2.0 · 3.0 · 4.0
- Z-Image — arXiv · GitHub
- GLM-Image — GitHub · HuggingFace
2. FLUX.2 — 16→32채널 VAE, 4D RoPE, 그리고 32B로의 스케일업

Black Forest Labs는 FLUX.1을 파인튜닝하지 않고 처음부터 다시 학습한 새 모델을 내놓았다. VAE·Text Encoder·DiT 백본 모두 새로 짰다는 점이 핵심이다.
2.1 4종 라인업과 라이선스

| 라인 | 규모/성격 | 채널 | 가격/라이선스 |
|---|---|---|---|
| FLUX.2 [pro] | 클로즈드 API, 8단계 추론 | BFL Playground/API | 약 10크레딧/회 (이미지당 900토큰) |
| FLUX.2 [flex] | LoRA·IP-Adapter 류 레퍼런스 기반 (1400토큰) | API | 사용량 과금 |
| FLUX.2 [dev] | 32B 오픈 가중치, RTX 4090 fp8 추론 가능 | HuggingFace + FAL·Replicate·TogetherAI 등 | 비상업 (상업화는 BFL 별도 라이선스) |
| FLUX.2 [klein] | 4B / 9B 경량 버전 | HuggingFace | Apache 2.0 |
| FLUX.2-VAE | 독립 오픈소스 VAE | HuggingFace | Apache 2.0 |
[klein]만 진정한 오픈소스라는 점, 그리고 VAE를 별도 오픈 컴포넌트로 분리해 배포한 점이 새 패턴이다. 400개 이상 언어와 4MP(최대 1920×1920) 출력, JSON 형식의 UI 레이아웃 지시·#DDC57A 같은 컬러 코드 직접 인식이 가능하다고 명시되어 있다.
2.2 VAE — 채널을 늘리고, 그 다음 더 못 늘리는 한계
FLUX.2의 핵심 변경은 VAE 채널 수다.
- SD VAE: 4채널, 토큰당 ~16px
- FLUX.1 VAE: 16채널, 토큰당 ~64px
- FLUX.2 AE: 32채널, 토큰당 ~128px
- RAE(참고용 극단치): ~768px/토큰
토큰당 픽셀 정보량을 두 배로 늘리면 같은 해상도를 더 적은 토큰으로 표현하게 되고, Transformer에 들어가는 시퀀스 길이가 짧아진다. 같은 연산량으로 더 큰 이미지를 다룰 수 있다.
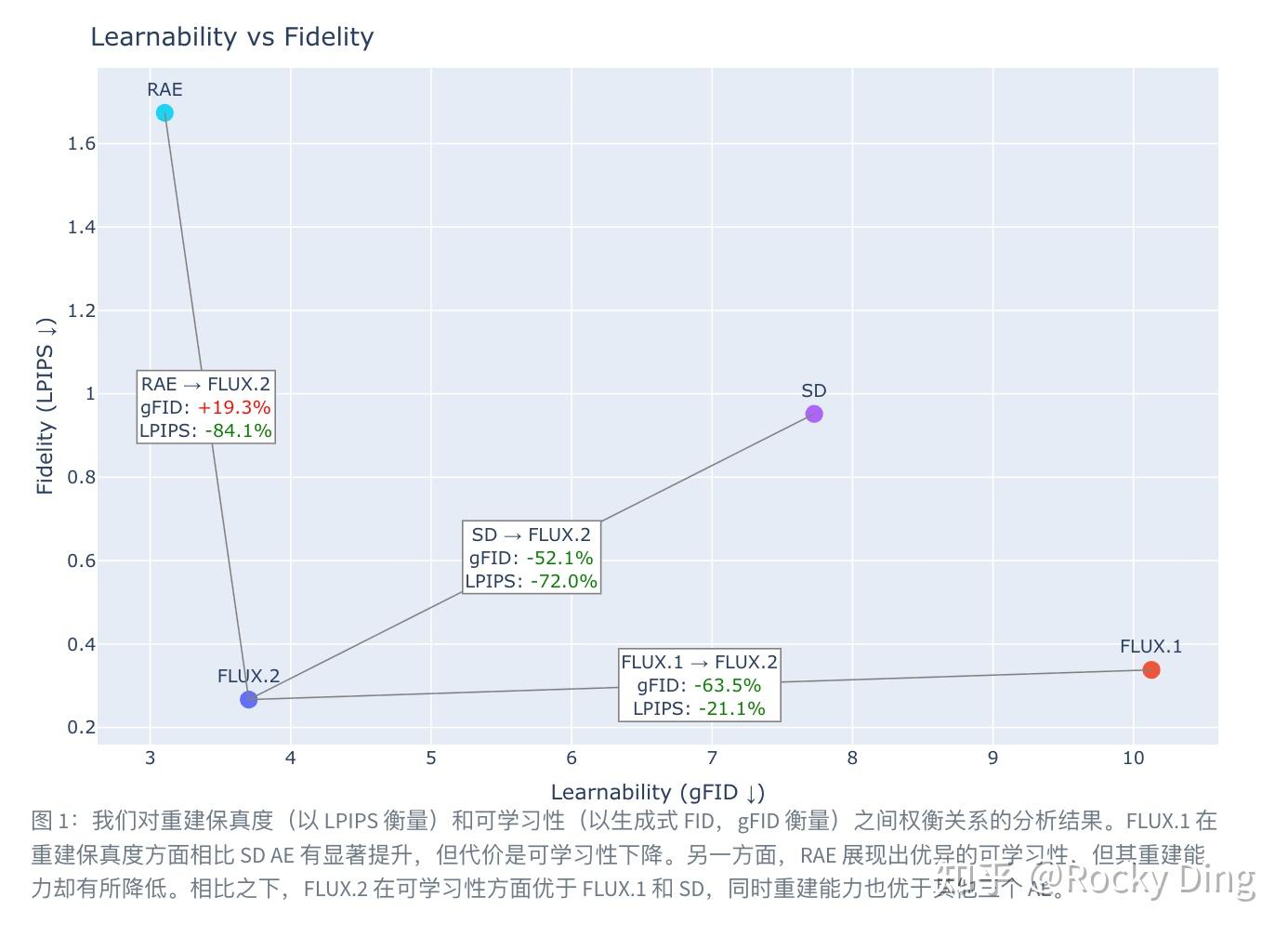
저자는 네 VAE를 LPIPS·SSIM·PSNR·rFID로 비교한 표를 그대로 옮긴다.
| 모델 | LPIPS ↓ | SSIM ↑ | PSNR ↑ | rFID ↓ |
|---|---|---|---|---|
| RAE | 1.6737 | 0.4962 | 18.83 | 0.6107 |
| SD VAE | 0.9519 | 0.6976 | 25.05 | 0.6451 |
| FLUX.1 VAE | 0.3380 | 0.8893 | 31.13 | 0.1761 |
| FLUX.2 AE | 0.2668 | 0.9038 | 31.46 | 0.1124 |
FLUX.2 AE가 네 지표 모두 1등이다. 흥미로운 대비는 RAE — gFID 비교에서는 FLUX.2(3.7017)보다 더 좋은 3.1040을 찍지만(−19.3%), LPIPS는 무려 +84.1% 나빠진다. 압축을 극단까지 밀면 전역 통계는 좋아져도 지각적 충실도가 무너진다는 신호다. 저자는 여기서 “단순히 토큰을 더 줄이는 방향은 한계가 있다"고 정리한다.
또한 FLUX.2 AE는 REPA(Representation Alignment, DINOv2 정렬) 없이도 위 결과를 냈다고 보고된다. FLUX.1 VAE는 REPA의 효과를 봤지만, FLUX.2 AE는 자체 학습만으로 그 자리를 대체한 셈이다.
2.3 Text Encoder — Mistral-3-24B 단일 LLM으로 갈아끼우다
FLUX.1까지 이어진 CLIP+T5 이중 구조는 FLUX.2에서 사라지고, Mistral-Small-3.2-24B-Instruct-2506(비전·언어 통합 24B 모델) 한 개로 대체된다. 단일 LLM이 프롬프트의 의미·복합 지시·텍스트 렌더링 의도까지 한 번에 임베딩하고, 그 임베딩을 DiT 백본이 받는다.
2.4 DiT 백본 — 12B → 32B, 활성화 함수, 4D RoPE
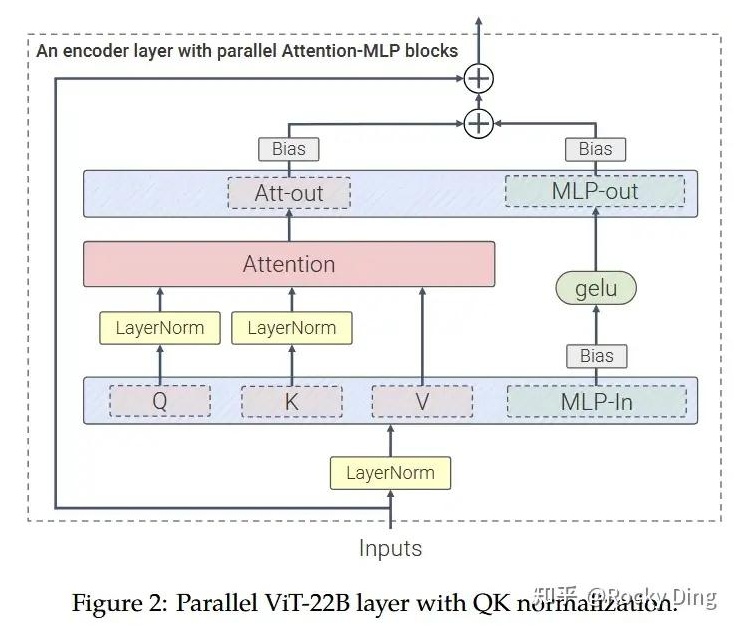
DiT 쪽 변경은 네 가지다.
- 스케일업: 12B → 32B.
- 활성화: GELU → SwiGLU. ViT-22B의 설계를 따랐다.
- Timestep·Guidance 주입: AdaLayerNorm-Zero. FLUX.1 대비 분기를 단순화하여 추론 효율을 끌어올렸다.
- RoPE: FLUX.1의 3D RoPE(w, h, t=0 고정) → 4D RoPE(w, h, l, t). 레이어 깊이
l이 추가되고,t는 0(새로 생성할 토큰)부터 10+(레퍼런스/편집 대상 토큰)까지 연속 값으로 확장된다.
같은 하드웨어에서 FLUX.1(12B, 19분 38초)이 받던 작업을 FLUX.2dev가 8분 48초에 끝낸다. 더 큰 모델이 더 빨라진 셈인데, 활성화·정규화 단순화와 토큰 수 절감이 누적된 결과로 정리된다.
2.5 학습 — CFM과 로그 선형 스케줄
FLUX 시리즈는 Rectified Flow / Conditional Flow Matching 계열 손실로 학습한다. FLUX.2의 CFM 손실 형태는 다음과 같이 정의된다.
$$\mathcal{L}_{\text{CFM}}(\theta) = \mathbb{E}_{t,\, u,\, \epsilon}\, \left\lVert v_\theta\!\left((1-t)E(u) + t\epsilon;\, t\right) - \left(\epsilon - E(u)\right)\right\rVert_2$$여기서 E는 FLUX.2 VAE, u는 학습 이미지, t는 시간 스텝, \(\epsilon\)은 노이즈다. 시간 스텝 분포 p에 어떤 분포를 쓰느냐가 중요한데, FLUX.2는 다음 변형 함수로 로그 선형 분포(ln) 위에 가중치를 입힌다.
알파 값은 VAE의 압축 강도에 따라 달라진다 — SD VAE 1.00, FLUX.1 1.78, FLUX.2 4.63, RAE 6.93. 압축이 강할수록 중간 timestep을 더 비중 있게 학습해야 한다는 경험칙이다. FLUX.2의 4.63은 FLUX.1보다 중간 단계 가중치를 더 끌어올린 값이고, 같은 RAE 결과(6.93)는 압축이 강한 인코더일수록 학습 신호를 중간 영역에 집중해야 함을 시사한다.
3. Seedream — 글리프 인코더와 RLHF의 누적
바이트댄스 Seed 팀의 Seedream 시리즈는 2.0(2025년 3월) → 3.0(2025년 4월) → 4.0(2025년 9월)으로 빠르게 진화했다. 3.0 기준 Artificial Analysis ELO 1158로 GPT-4o·Midjourney v6.1과 경쟁한다고 자평한다.
3.1 PE — 프롬프트 엔지니어링을 학습 파이프라인 안으로
Seedream의 가장 특이한 결정은 PE(Prompt Engineering)를 모델 외부의 트릭이 아니라 학습 파이프라인의 한 단계로 포함한 것이다. 사용자가 입력한 짧고 모호한 프롬프트를, 별도의 LLM이 길고 명확한 묘사로 재작성한 뒤 본 모델에 넣는다.
저자는 Seedream 4.0의 PE 학습이 다음 두 단계로 이뤄진다고 정리한다.
- SFT 단계 — 짧은 사용자 프롬프트
u와 정제된 긴 프롬프트r쌍\(D = \langle u, r\rangle\)로 LLM을 지도학습한다. 이때 두 방향을 동시에 학습한다 —\(u \to r\)(확장)과\(r \to u\)(요약). 사용자가 짧게 줘도, 길게 줘도, 둘 다 자연스럽게 변환되게 만든다. - PE-RLHF 단계 — 같은
u에 대해 PE가 만든 여러\(r_1, r_2, \dots, r_n\)을 본 모델로 통과시켜 이미지를 생성하고, 그 이미지 품질로 PE 자체에 SimPO를 돌린다. 즉 최종 이미지 품질을 기준으로 프롬프트 재작성기를 강화학습한다.
저자의 추정: PE 처리만으로 이미지 품질이 약 30% 향상되고, 추론 파라미터 조정은 5% 정도다. 학습 파이프라인 입구에 사람·LLM 사이의 통역사를 두는 결정이 효과가 크다.
Seedream 4.0은 AdaCoT(Adaptive Chain-of-Thought)까지 도입했다. PE가 항상 길게 생각하지 않고, 입력 복잡도에 따라 사고 예산(Thinking Budget)을 동적으로 배분한다. 단순한 프롬프트에는 짧게, 복잡한 프롬프트에는 길게.
3.2 Glyph-Aligned ByT5 — 글자만을 위한 전용 인코더
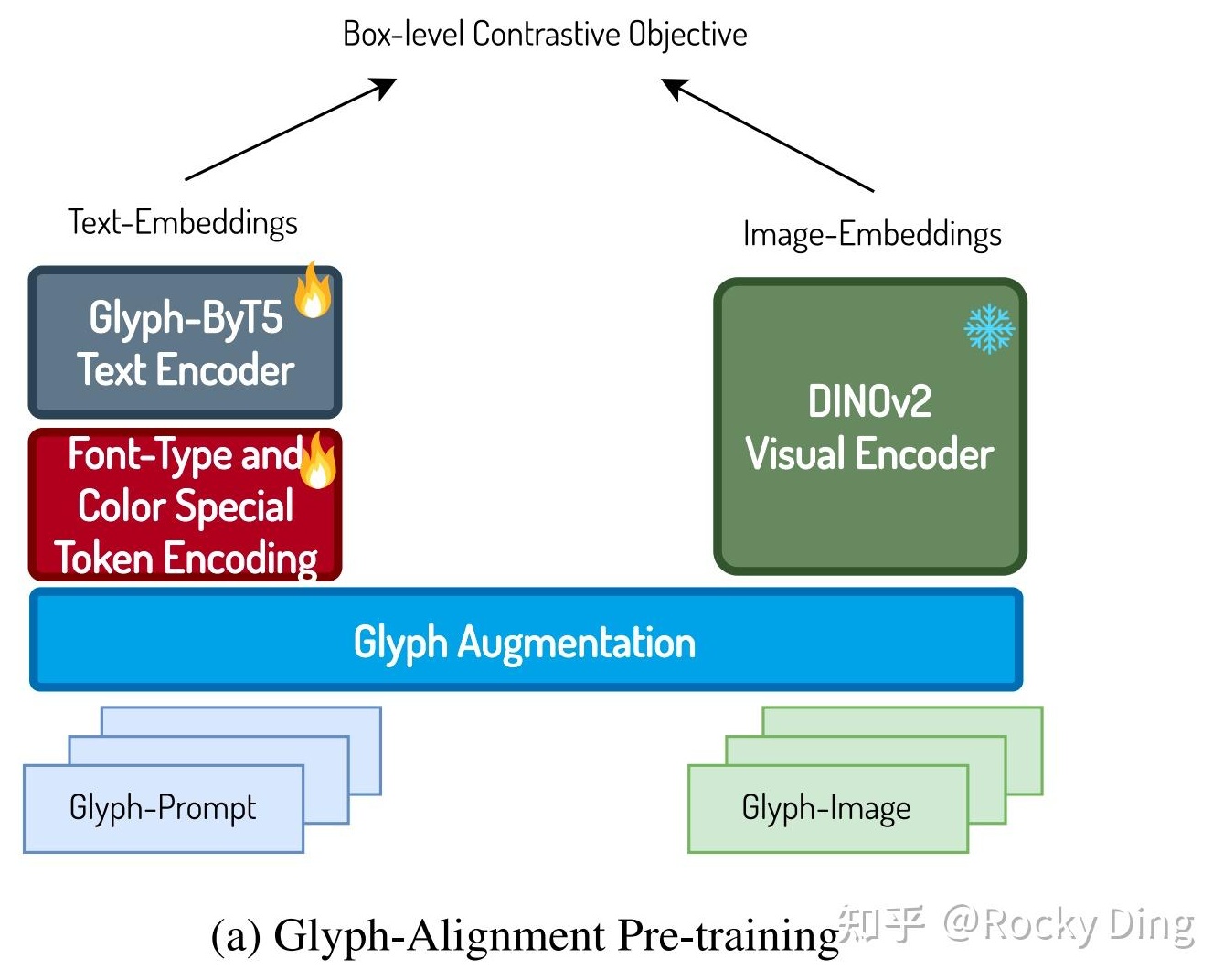
중국어·한글처럼 글자 모양이 복잡한 언어를 이미지 안에 정확히 렌더링하려면, 의미 인코더만으로는 모자라다. Seedream은 Glyph-Aligned ByT5라는 바이트 단위 글자 전용 인코더를 별도로 두고, 본 LLM 임베딩과 concat해서 DiT에 넘긴다.
학습은 네 단계로 진행된다.
- DINOv2(ViT-B/14, 86M)를 글리프 이미지에 적응시키는 사전학습.
- ByT5-Small(217M)을 DINOv2 정렬 목표로 학습.
- Box-level Contrastive Loss — “이 박스 안에는 이 글자가 있어야 한다"는 공간 정렬을 50~100만 쌍의 글리프-텍스트 데이터로 학습.
- 위에서 학습된 ByT5를 본 DiT 백본과 통합.
ByT5는 BPE 같은 서브워드 단위가 아니라 바이트 단위로 텍스트를 본다. 한자·한글 같은 비라틴 문자에 강한 이유다. 의미는 본 LLM이 잡고, 글자 모양·위치·크기는 ByT5가 잡는 식으로 역할을 나눈 셈이다.
3.3 위치 인코딩 — Scaling RoPE와 token ID 재설계
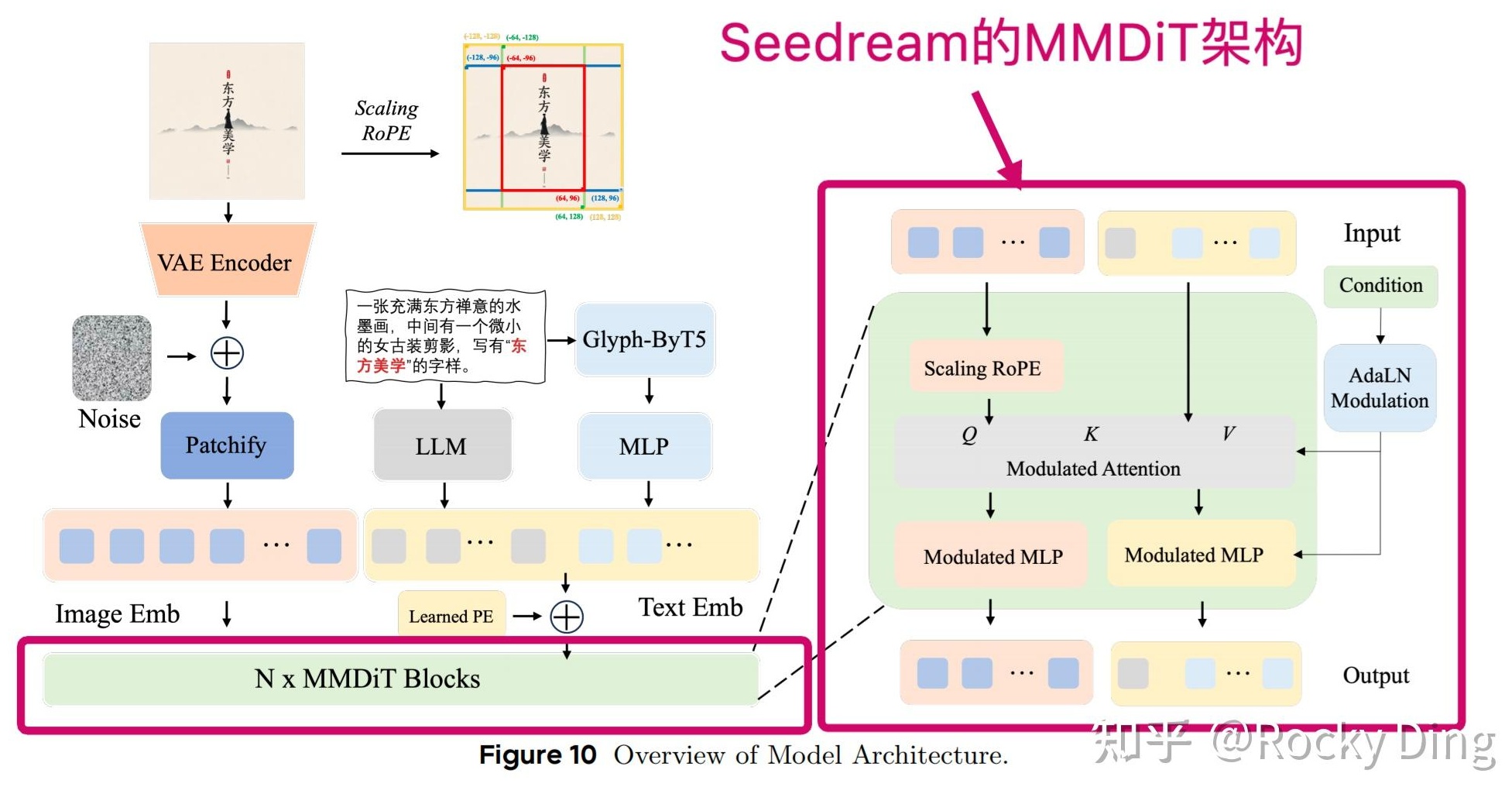
- Seedream 2.0: 이미지 토큰에 Learned PE, 텍스트 토큰에 2D RoPE. 훈련 해상도 너머로 일반화하기 위해 Scaling RoPE를 도입.
- Seedream 3.0: 이미지 토큰의 풀링 ID를
[1, L]범위의 2D RoPE로 통합, 텍스트 토큰 ID는 그 뒤에 이어붙인다. 토큰 종류·위치를 한 좌표계 안에 담는 시도. - Seedream 4.0: DiT 파라미터를 줄이는 대신 경량 VAE와 결합해, 3.0 대비 같은 해상도에서 FLOPs를 10분의 1로 낮추면서 2K 해상도를 지원한다.
3.4 데이터·Refiner·RLHF — 본 모델 밖의 노력이 더 컸다
Seedream 2.0에서 4.0까지의 개선분 중 본 DiT 자체의 변경은 일부고, 대부분의 품질 향상은 데이터 캡션 품질·RLHF·Refiner에서 왔다. 저자가 정리한 4.0의 RLHF 구성요소는 다음과 같다.
- VLM 리워드 모델: 1B에서 20B+까지 키운 시각·언어 모델로, “Yes/No” 토큰 확률 차이를 리워드 신호로 쓴다. CLIP 기반 리워드의 한계(짧은 문장만 평가)를 깬다.
- DanceGRPO / RewardDance: 동일 프롬프트에 대해 여러 이미지를 샘플링하고, 그룹 단위 Z-Score 정규화로 advantage를 계산하는 GRPO를 이미지 생성에 직접 이식.
- Base 학습과 별개로 Refiner를 RLHF 단독으로 또 한 번 정렬해, 마지막 단계의 미적·텍스트 품질을 끌어올린다.
저자는 이 결정을 두고 “Seedream 3.0 이후의 전체 품질 향상의 35% 정도는 Refiner RLHF가 책임진다"는 추정을 덧붙인다(자체 추정치).
4. Z-Image — 6B로 80B급과 경쟁한 단일 스트림 DiT
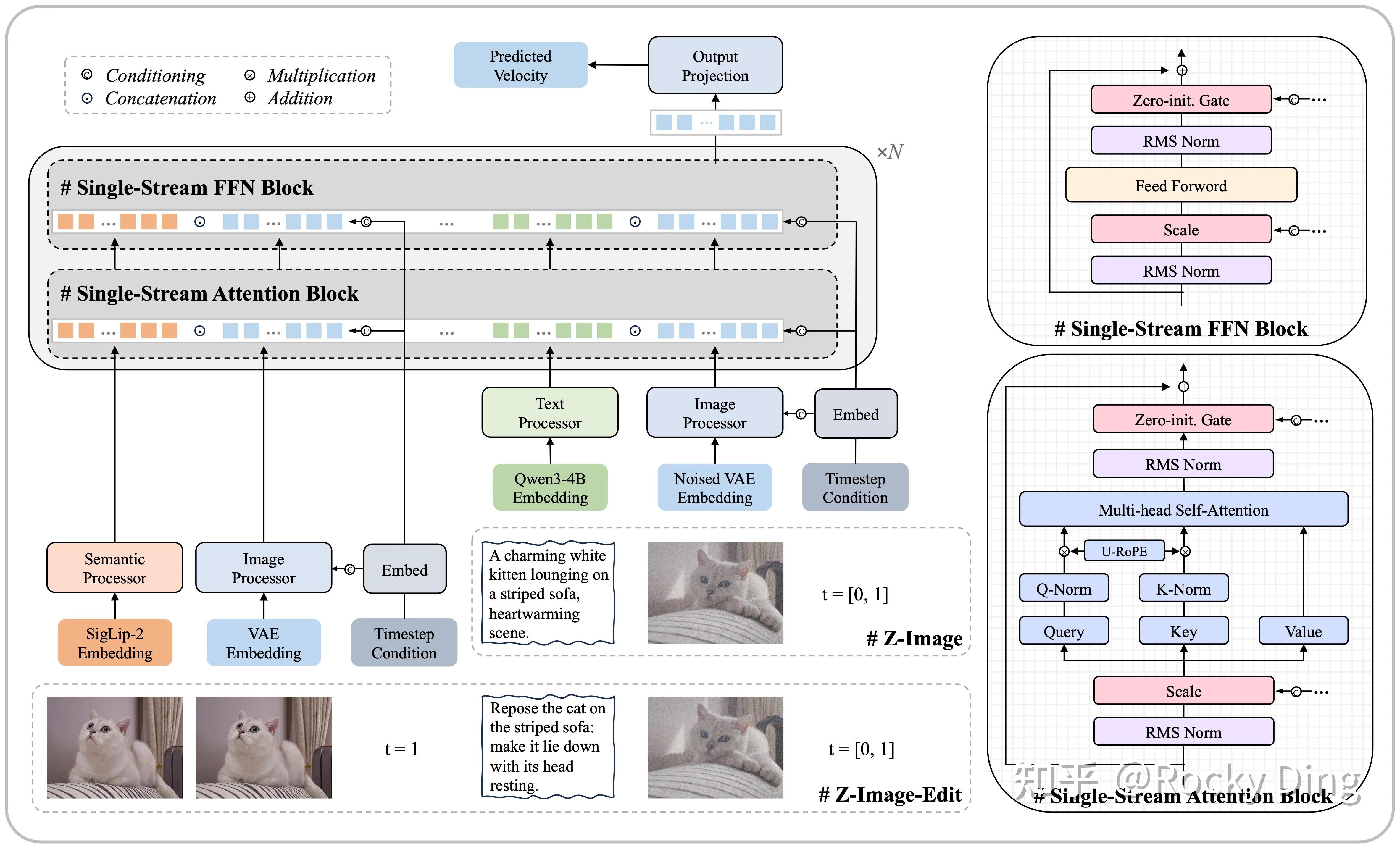
알리바바 Tongyi-MAI 팀의 Z-Image는 큰 모델로 가는 흐름과 정반대로 간다. 총 6.15B 파라미터로, 30개 Transformer 블록·히든 차원 3840·헤드 32·FFN 10240·3D U-RoPE(32, 48, 48)의 단일 스트림 DiT다. 훈련에 H800 GPU·시간으로 314K(약 63일).
4.1 S3-DiT — 텍스트·이미지·시멘틱을 한 스트림으로
FLUX의 MM-DiT나 Seedream의 MMDiT는 이미지 토큰과 텍스트 토큰을 두 개의 분리된 스트림으로 처리하다가 일부 블록에서만 교차 어텐션으로 섞는다. Z-Image의 S3-DiT(Scalable Single-Stream DiT)는 그 분리를 없앤다.
입력은 세 개의 작은 처리기를 거쳐 한 스트림으로 합쳐진다.
- Text Processor: Qwen3-4B로 의미 임베딩을 만들고, Transformer 2블록을 통과해 토큰화.
- Image Processor: FLUX.1 VAE를 그대로 빌려 와 토큰화한 뒤 Transformer 2블록 통과. — 즉 Z-Image는 VAE를 새로 짜지 않았다.
- Semantic Processor: SigLIP2의 시멘틱 임베딩을 받아 Transformer 2블록 통과. 레퍼런스 이미지가 들어올 때 그 의미를 포착하는 통로.
세 스트림이 같은 어휘 공간으로 합류한 뒤, 단일 Self-Attention + FFN 블록 30층이 차례로 받는다. 각 블록 안에는 RMS Norm, Scale 파라미터, QK-Norm, 3D U-RoPE, Zero-init Gate가 들어 있다. Zero-init Gate는 초기 학습을 0에서 시작해 안정화하는 장치다.
편집(Z-Image-Edit) 모드는 원본 이미지 VAE 토큰(t=1로 마킹)과 노이즈 VAE 토큰(t∈[0,1])을 같은 시퀀스에 함께 넣고, 3D U-RoPE로 둘의 위치를 구분한다. FLUX.2의 4D RoPE와 같은 발상 — 위치 차원에 의미를 새긴다.
4.2 데이터 파이프라인 3엔진
Z-Image 논문이 공개한 데이터 처리 파이프라인은 세 엔진으로 구성된다.
- Data Profiling Engine — pHash 중복 제거, JPEG 품질 필터, AI 생성 이미지 탐지(워터마크·아티팩트 제거), CN-CLIP 기반 미적 점수화.
- Cross-modal Vector Engine — range_search + k-NN을 H800 8장으로 10억 장 / 10분 처리. 의미 유사 이미지 군집을 관리.
- World Knowledge Topological Graph — 지식 그래프 위에 데이터를 분포시키고 VLM이 자동 레이블링. BM25 텍스트 검색 통합.
캡션은 Z-Captioner라는 CoT 기반 OCR 내장 캡션 생성기로 5단계 프롬프트를 거쳐 만든다. 특히 편집 작업의 자연어 묘사(예: “왼쪽 컵의 색을 파랑으로 바꿔라”)를 자동 생성하는 게 Z-Image-Edit 학습 데이터의 핵심이라는 점이 인상적이다.
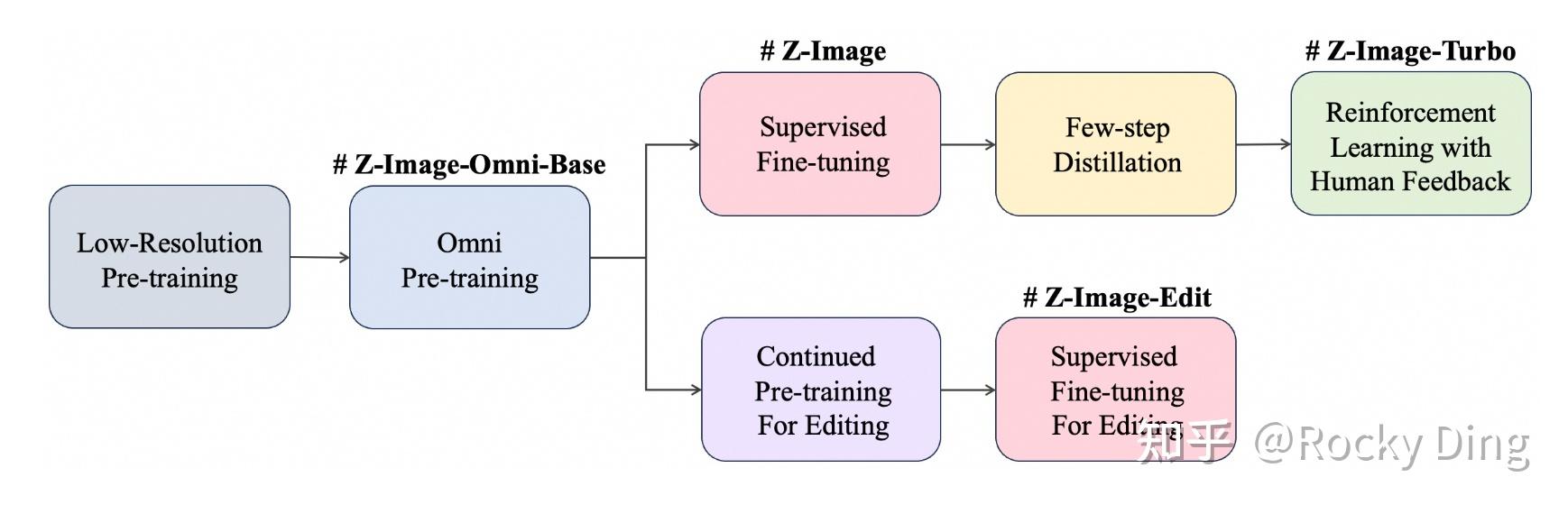
4.3 5단계 훈련 — DMDR로 100 NFE에서 8 NFE로
훈련은 다섯 단계다.
- 저해상도(256×256) 사전학습 — 50% 샘플링.
- Omni 사전학습 — 멀티모달 통합.
- PE 포함 SFT — Qwen3-4B PE 모델로 프롬프트 재작성.
- DMDR(Decoupled DMD + RL) — 100 NFE → 8 NFE 증류. DMD로 CFG를 없애고, RL로 추가 품질 보정.
- RLHF — DPO(1단계 품질 정렬) + GRPO(2단계 분포 최적화).
Z-Image-Turbo는 8 NFE로 빠른 추론을 제공하는 라인업이다. 6B 모델·8 NFE 조합이 Artificial Analysis 8개 항목에서 FLUX.2[dev] 등 더 큰 모델을 따라잡는다는 게 저자의 강조점이다.
5. GLM-Image — AR로 구조, Diffusion으로 픽셀

智谱AI(ZhipuAI)와 칭화대의 GLM-Image는 네 모델 중 가장 급진적인 아키텍처 선택을 한다. 이미지 생성을 LLM의 자기회귀 작업과 Diffusion의 픽셀 작업으로 분리한다. PyTorch가 아니라 MindSpore + Huawei Atlas 800T A2(Ascend NPU) 위에서 학습됐다는 인프라 결정도 특이하다.
5.1 5대 컴포넌트
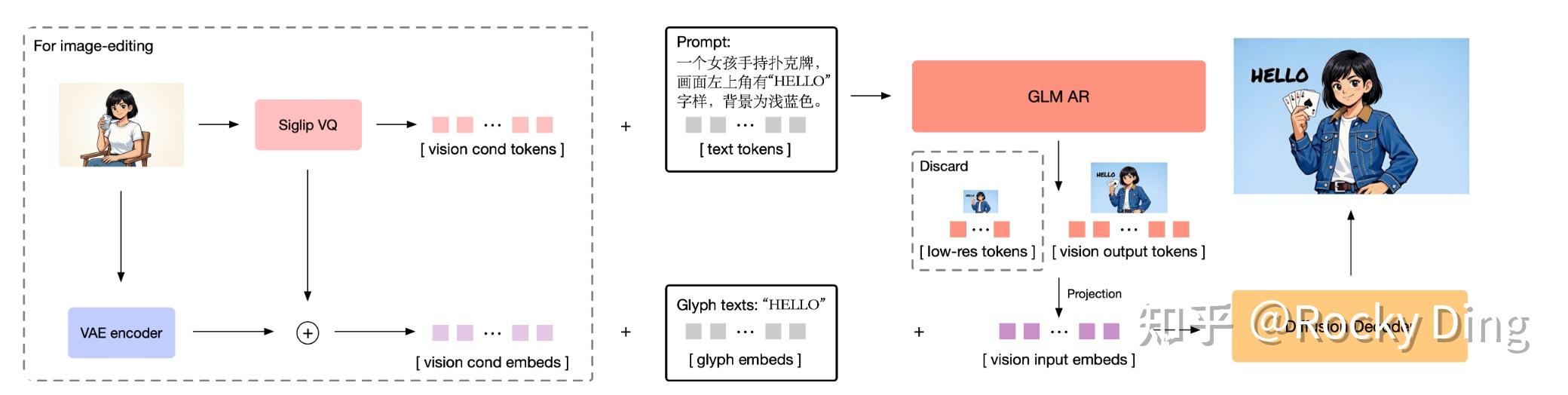
- AR Generator (9B, GLM-4-9B-0414 기반) — LLM이 텍스트 설명을 받아 semantic-VQ 토큰을 자기회귀적으로 생성. XOmni tokenizer(16×16 patch)를 쓴다. 256px → 256 토큰, 512px → 1024 토큰, 1024px → 4096 토큰, 최대 2048px. Vision LM Head와 Text LM Head를 별도로 둔다.
- Diffusion Decoder (7B, Single-Stream DiT, Flow Matching) — AR이 만든 semantic-VQ 토큰 + Glyph-byT5 임베딩 + VAE 노이즈를 받아 픽셀을 만든다. 32 DiT 블록, 2048px까지. Block Causal Attention 적용.
- VQ-VAE — XOmni tokenizer.
- Vision Encoder — 편집·레퍼런스 입력 이해.
- Glyph-byT5 — Diffusion Decoder에 글리프 임베딩을 별도 주입.
5.2 MRoPE와 단계적 생성

AR Generator는 텍스트 토큰의 1D 위치와 이미지 토큰의 2D 위치를 통합한 MRoPE(Multimodal Rotary Position Embedding)로 동작한다. 텍스트 차원과 이미지 공간 차원을 한 좌표계로 묶어, 같은 어텐션 블록이 두 종류 토큰을 모두 다룬다.
생성은 단계적이다.
- 256px에서 256 토큰으로 전체 구도를 결정.
- 512px로 확장(1024 토큰)해 세부를 추가.
- 1024px(4096 토큰)로 확장해 최종 해상도까지 끌어올린다.
이전 단계의 토큰을 다음 단계의 컨텍스트로 활용하기 때문에, 줌인할수록 디테일이 어긋나는 일이 줄어든다. 마지막 단계의 토큰이 확정되면, Diffusion Decoder가 이를 받아 픽셀로 풀어낸다.
5.3 flow-GRPO — 복합 리워드의 Z-Score 정규화
GLM-Image의 정렬 학습은 flow-GRPO로 부른다 — Flow Matching DiT 위에서 LLM의 GRPO를 그대로 돌린다. 리워드는 네 가지를 가중합한다.
- HPSv3 — 미적 점수.
- OCR — 이미지 안 텍스트 정확도.
- VLM — 의미 일치.
- LPIPS — 디테일 충실도.
그룹 내 G=16개 샘플을 뽑아 Z-Score로 정규화한 advantage를 계산하고, KL 항으로 발산을 억제한다. DeepSeek R1의 GRPO를 이미지 RLHF에 곧장 옮긴 사례 중 하나다.
6. 네 모델을 가로지르는 여섯 가지 흐름
| 흐름 | 2024 이전 | 2025~2026 |
|---|---|---|
| Text Encoder | CLIP + T5 (이중) | LLM 단일 또는 LLM + 글리프 인코더 |
| VAE 채널 | 4~16 | 16~32 (FLUX.2가 32까지, RAE는 768로 극단치) |
| DiT 구조 | MM-DiT(이중 스트림) | MM-DiT 유지(FLUX·Seedream) / 단일 스트림(Z-Image) / AR+Diffusion 분리(GLM-Image) |
| 위치 인코딩 | 2D RoPE | Scaling RoPE / 3D U-RoPE / 4D RoPE(t 차원에 의미 부여) |
| 정렬 학습 | CLIP 리워드 | VLM 리워드 → DPO → GRPO(DanceGRPO, flow-GRPO) |
| 데이터 캡션 | 수작업 + 단순 BLIP | LLM/VLM 자동 캡션 + CoT(Z-Captioner, AdaCoT) |
저자가 강조하지 않지만 눈에 띄는 것이 둘 있다. 첫째, Text Encoder의 LLM 전환은 단지 더 큰 모델을 끼우는 일이 아니라, 프롬프트 *재작성기(PE)*가 학습 파이프라인의 정식 단계로 들어오는 구조 변화와 묶여 있다. 둘째, 위치 인코딩의 차원 추가는 단지 좌표를 더 잘 표현하기 위함이 아니라, “이 토큰이 어떤 역할을 하는지” — 새로 생성될 내용인지, 참조할 내용인지, 어떤 레이어에서 들어오는지 — 를 모델에게 암묵적으로 알리는 통신 채널로 쓰이고 있다.
7. 가장 흥미로운 지점
4D RoPE에서 t 차원의 의미. FLUX.1 Kontext가 t를 1로 고정해 “레퍼런스 이미지가 있다/없다” 정도의 이진 신호로 썼다면, FLUX.2는 t를 0(새로 생성할 토큰), 10+(레퍼런스/편집 대상 토큰)처럼 연속 값으로 풀었다. 위치 인코딩이 더 이상 “이 토큰이 어디 있나"만 묻는 게 아니라 “이 토큰이 어떤 역할을 하나"를 함께 묻게 된 셈이다. Z-Image의 3D U-RoPE가 원본 이미지(t=1)와 노이즈(t∈[0,1])를 한 시퀀스에 섞을 때 쓰는 발상도 같다. 위치 인코딩이 역할 인코딩으로 의미를 넓혀가고 있다.
GLM-Image의 분리주의. GLM-Image는 “이미지 생성"을 단일한 작업으로 보지 않는다. 그림 전체의 구조는 언어 모델의 자기회귀로 짜고(“이 그림에는 고양이가 왼쪽 위, 빨간 소파가 중앙”), 그 위의 픽셀은 Diffusion이 그린다(“이 고양이 털 한 올의 그라데이션”). 9B LLM이 256개 토큰으로 256px 초안을 짜고, 같은 모델이 그걸 받아 1024 토큰으로 512px 중간본을 만들고, 마지막에 7B DiT가 픽셀로 떨군다. 이미지 생성 모델의 설계 공간이 “더 큰 DiT 하나"로 수렴하던 흐름에 역방향으로 갈라진 가장 급진적인 실험이다 — 그리고 그게 PyTorch가 아닌 MindSpore + Ascend 위에서 일어났다는 점도 의미심장하다.
출처
- 저자: Rocky Ding (공중호 WeThinkIn 운영, 2025 AIGC 알고리즘·AI 그림 면접 노트 운영자)
- 발표 시점: 2026년 3월 (zhihu)
- 원문: https://zhuanlan.zhihu.com/p/1975174691049189562
- 본 다이제스트는 원문의 기술 해설 부분(FLUX.2·Seedream·Z-Image·GLM-Image 아키텍처 비교, 섹션 2~5)을 중심으로 정리했다. 원문의 자기 강의·면접노트 홍보 섹션은 의도적으로 옮기지 않았다.