3줄 요약
- Exponential View의 Azeem Azhar와 Nathan Warren이 2026년 5월 28일에 발표한 에세이로, “AI가 개인 생산성은 올렸지만 회사의 손익에는 왜 잡히지 않는가"라는 질문을 다룬다.1
- Paul David가 정리한 전기화 도입의 3단계(전구·그룹 드라이브·유닛 드라이브)를 빌려 와, AI 도입도 똑같이 단계적 J-커브를 그린다고 진단한다. 현재 대부분 기업은 워크플로 비용을 줄이는 2단계에 머무르고, 그 출력은 그대로인 의사결정 파이프라인에 쌓여 congestion(정체) 을 만든다.
- 3단계로 가려면 기능을 더 빨리 만드는 것이 아니라 워크플로 사이의 의사결정 속도를 재설계해야 한다. AI가 신호를 직접 받아 판단·실행하는 새로운 인지 레이어가 필요하며, 관리 감독의 역할도 다시 짜야 한다.
누가, 언제, 무엇을 말하는가
- 저자: Azeem Azhar(Exponential View 발행인), Nathan Warren 공저.
- 발표: 2026년 5월 28일, Exponential View 뉴스레터. 유료 구독자 대상으로 후반부(“3단계로 가는 법”)는 페이월 뒤에 있다.
- 주제: AI 도입이 개인 생산성에는 분명한 효과를 주지만 기업 단위 ROI로는 좀처럼 환원되지 않는 생산성 퍼즐을 일반목적기술(GPT) 채택의 단계 모델로 푼다.
자료를 여는 일화부터 정확히 옮겨 둔다.
지난달 잘 알려진 상장 기술 기업의 한 임원과 차를 마셨다. 그녀 휘하에는 약 1,000명의 엔지니어가 있고, 거의 모두가 Claude Code를 쓴다. 코드 줄 수도, PR 수도, 처리량도 늘었다. 개인의 생산성은 올라갔는데, 조직 차원에서는 그만큼이 보이지 않는다. 그녀의 말로는 “1 더하기 1 더하기 1 더하기 1이 1.5가 된다.”
Uber COO Andrew Macdonald도 비슷한 결을 공개적으로 인정했다. “암묵적으로는 더 많은 것이 배포되고 있을지 모르지만, 그 통계와 ‘우리가 실제로 25% 더 유용한 소비자 기능을 만들어 내고 있다’는 결론 사이에 선을 긋기는 매우 어렵다.”2
한편 Anthropic 매출은 같은 기간 폭발적으로 커졌다 — 2년 전 연 100만 달러 이상을 Claude에 쓰는 고객은 12곳뿐이었지만 지금은 1,000곳을 넘었고, 평균 기업 고객의 지출은 지난 한 해 5배가 되었다.3 그런데도 AI가 ROI 기대치를 충족했다고 답한 경영진은 27%에 불과하다(Oliver Wyman Forum 조사).4 나머지 73%는 기대가 너무 높은 것일까, 낮은 것일까, 아니면 잘못된 종류의 기대를 가지고 있는 것일까.
생산성 퍼즐, 다시 짚기
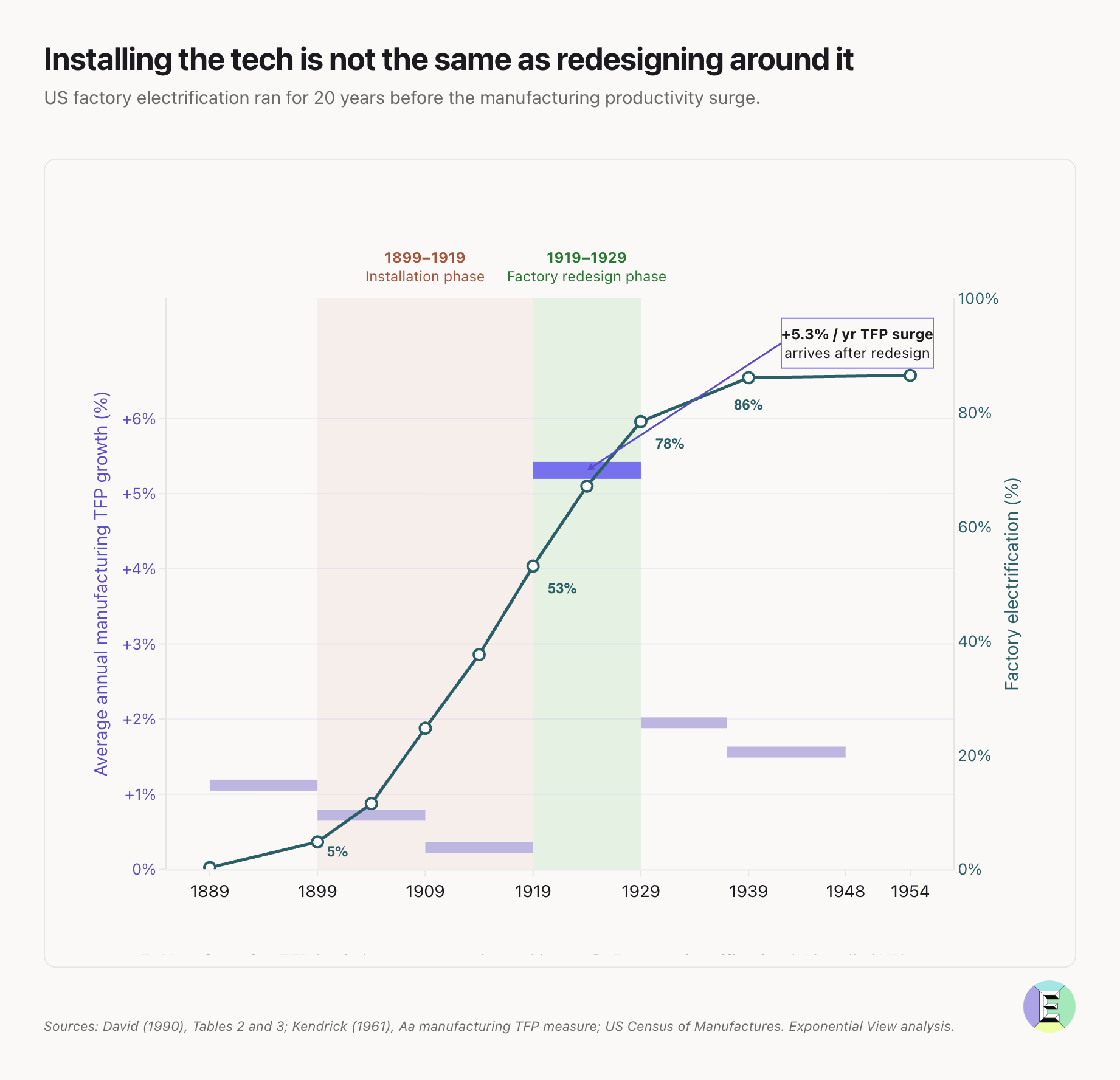
1987년 Robert Solow는 “컴퓨터 시대는 도처에서 보이는데, 생산성 통계에서만 안 보인다"고 했다.5 몇 년 뒤에는 통계에서도 보이기 시작했다. Paul David는 이것이 일반목적기술(general-purpose technologies, GPT) 의 일반적인 양상임을 정리했다.6 GPT는 초기 단계에 측정된 생산성을 오히려 끌어내린다 — 회사가 하드·소프트 노하우 양쪽에 보완 투자를 끝내야 비로소 효과가 나타나기 때문이다. Erik Brynjolfsson은 이를 생산성 J-커브라고 부른다.7
이 글은 Paul David의 1990년 전기화 논문을 길게 끌어와 AI 단계를 매핑한다. 3단계 구조를 한 장으로 정리하면 다음과 같다.

Stage 1 — The lightbulb (전구)
전기가 공장에 처음 들어왔을 때 가장 단순한 역할은 조명이었다. 가스등보다 안전하고 기름등보다 깨끗했다. 하지만 사람–기계–샤프트–벨트로 흐르던 작업 순서는 그대로였다. 작업자의 환경이 개선됐을 뿐, 공장의 작동 논리는 바뀌지 않았다.
ChatGPT가 처음 풀렸을 때도 같은 일이 벌어졌다. 이메일을 더 빨리 쓰게 되고, 어떤 과업에서는 개인이 빨라졌지만 회사가 빨라지진 않았다. 오늘날 대부분의 AI 제품은 여전히 개인 생산성에 머문다. ChatGPT나 Claude의 엔터프라이즈 플랜이 있지만, 작업 단위는 여전히 개인의 손에 있는 과업이다. 엔터프라이즈 플랜은 단지 사내 스킬 저장소에 빠르게 접근하게 해 줄 뿐이다.
Stage 2 — The group drive (그룹 드라이브)
전기 채택의 다음 단계는 생산성보다는 비용 절감이 목표였다. Louis Bell은 1891년 대규모 중앙 증기 발전이 작은 엔진보다 석탄 효율이 5~7배 좋다고 적었다.8 공장은 중앙 발전소에서 전력을 사 와 전동 모터로 기존 샤프트와 벨트를 돌렸다.9
뒤이어 전기공학 교수 F. B. Crocker와 동료들이 다른 응용을 찾아냈다.10 전기는 공장 바닥을 샤프트로부터 해방시킨다. 기계가 더는 샤프트 아래 평행으로 늘어설 필요가 없어졌다. 그러면 모터를 도구마다 하나씩 두느냐, 도구 묶음마다 하나씩 두느냐 — 후자가 group drive다. 하나의 모터가 공유 샤프트를 통해 여러 기계를 돌리는 방식이다.

그룹 드라이브는 기존 레이아웃을 보존하고, 매몰자본을 재활용하며, 모터 수를 줄이면서 전기의 이득을 공장을 다시 짓지 않고도 얻게 해 줬다. 저렴하고 쉬워서 1890년대부터 1차 세계대전까지 공장을 지배했다.
AI 에이전트는 챗봇보다 낫다. 단일 과업이 아니라 워크플로 전체를 다룰 수 있다. 하지만 그룹 드라이브처럼 기존 조직 기하학에 매달려 있다. 전기에서는 그 기하학이 공장 바닥 레이아웃이었다면, AI에서는 LLM이 등장하기 한참 전에 회사들이 설계한 프로세스의 그물망이다.
AI 채용 에이전트는 사람과 ATS가 함께하던 과정을 빠르게 해 준다. 채용 파이프라인이 몇 주에서 몇 시간으로 줄 수 있다. 고객지원 에이전트는 지원팀이 처리하던 것보다 더 많은 티켓을 받아낸다. 이 사례들의 논리는 본질적으로 비용 절감 — 더 적은 인원으로 더 많은 티켓을, 같은 헤드카운트로 더 많은 후보를 거른다. 회사가 더 빨리 중요한 의사결정을 내리는 것은 아니다. 이것이 Stage 2, 같은 샤프트 위에서 기계가 더 빨리 도는 그룹 드라이브다.
Stage 3 — The unit drive (유닛 드라이브)
공장의 조직 논리가 비용 절감에서 처리량(throughput) 으로 옮겨 가고 나서야, 비로소 유닛 드라이브 — 기계 하나에 모터 하나 — 의 깊은 가치가 보였다. 1913년 Ford의 Highland Park 공장은 기계와 작업자를 샤프트와 벨트의 기하학이 아니라 작업 흐름을 중심으로 배치하기로 결정했다. 그 뒤 10년(1919~1929)간 유닛 드라이브가 더 많은 공장에 퍼지면서 미국 제조업 노동생산성은 연 5.4% 성장했다.11

저자들은 AI 도입의 패턴이 정확히 같은 모양을 그릴 것이라 본다.
Stage 1은 개인을 빠르게 하고, Stage 2는 워크플로를 빠르게 하며, Stage 3은 회사 그 자체를 빠르게 한다.
사다리 — 역량 등급이 아닌 조직 논리
이 글의 모델은 Carnegie Mellon의 CMM 같은 역량 성숙도 모델과 다르다. 성숙도 모델은 각 단계를 “고정된 일을 얼마나 잘하느냐"의 등급으로 본다. 이 글의 사다리는 단계마다 조직이 추구하는 목표(organizing logic) 자체가 달라진다.
전구를 단 작업장은 Ford 공장보다 못한 곳이 아니었다. 다른 목표 — 작업장 바닥을 안전하게 비추는 것 — 를 추구하고 있었을 뿐이다. 전구를 더 많이 단다고 컨베이어 벨트가 나오지는 않는다.

여기서 글의 가장 날카로운 진단이 나온다. 회사는 모든 축에서 한 칸씩 균일하게 올라가지 않는다.
- AI 도구로 50% 더 생산적인 개인 개발자는 전통적 리뷰 사이클 앞 대기열에 서게 된다.
- 어느 때보다 빨리 프로토타입을 만드는 프로덕트 팀은 결재를 기다리며 기능 백로그를 쌓는다.
- AI 작성 제안서로 무장한 영업팀은 법무 리뷰보다 빠르게 딜을 닫아 버린다.
실행이 Stage 2로 옮겨 가는데, 결정이 내려지는 방식인 관리층은 그대로다. 저자들은 이 어긋남을 congestion(정체) 이라 부른다. 개인과 팀의 산출물이 갈 곳을 찾지 못해 쌓이는 현상이다.
Stage 3 기업이 되려면, 개별 워크플로의 속도가 아니라 워크플로들 사이의 의사결정 속도를 중심으로 회사를 다시 짜야 한다. 이미 정체에 시달리고 있다면, 막힌 의사결정 파이프라인에 워크플로와 산출물을 더 얹는 것은 사태를 악화시킬 뿐이다.
저자들은 자기 팀(Exponential View, 인원 8명) 에서도 같은 일이 벌어졌다고 적어 둔다. 기능을 만드는 속도가 릴리스 프로세스보다 빨라졌고, 그 격차를 해소하는 방법을 지금 찾고 있다.
의사결정을 빠르게 — 새로운 인지 레이어
저자들이 제시하는 방향은 분명하다. 의사결정을 빠르게 하려면 AI가 의사결정 자체를 내려야 한다. 관리 감독의 역할이 사이클 시간을 줄이는 마지막 장벽일 수 있다는 것이다.
AI에는 새로운 인지 레이어 가 필요하다 — 회사가 작업자를 매개로 거치지 않고 신호를 직접 해석하는 층. 글이 드는 예시는 다음과 같다.
고객이 기능 요청을 고객지원에 보내면, 보통 지원 담당자를 거쳐 PM에게 가고, PM이 로드맵에 올릴지 결정하고, 그러고도 몇 주 또는 몇 달 후 개발자가 코딩한다. AI와 함께라면, 그 신호를 에이전트가 직접 관찰한다. 로드맵과 코드베이스에 비춰 방향을 잡는다. 그 기능을 작성할 가치가 있는지 결정한다. 그리고 만든다. 몇 주가 아니라 몇 시간이다. 이것이 Stage 3 기업, 유닛 드라이브다.
이 지점에서 글의 무료 공개분은 끝난다. “어떻게 Stage 3로 옮겨 갈 것인가"의 처방은 유료 구독자 대상이다.
가장 흥미로운 지점
전기화 비유 자체보다, “성숙도 모델이 아니라 조직 논리가 단계의 본질"이라는 재정의가 가장 묵직하다. CMM 식의 성숙도 사다리는 같은 일을 더 잘하라고 권하지만, 이 글의 사다리는 지금 뭘 하려고 하는지를 바꾸라고 한다. 전구를 더 많이 단다고 컨베이어 벨트가 나오지 않는다는 한 줄이 글 전체의 무게를 떠받친다.
또 하나, congestion이라는 명명이 좋다. 막연히 “AI 도입이 더디다"고 말하던 현상에 왜 더딘지를 가리키는 단어를 붙였다. 개인이 빨라지고 워크플로가 빨라져도 결재·리뷰·법무 같은 의사결정 파이프라인이 그대로면, 산출물은 그저 쌓이고 어떤 단계에서는 더 쌓을수록 더 늦어진다. 이건 단순한 비유가 아니라 큐 이론에 가까운 사고방식이다.
세 번째로, 저자들이 자기 팀(8명) 에서도 같은 일이 일어났다고 솔직하게 적어 둔 점이 인상 깊다. 이 정체는 대기업의 관성 문제가 아니라 AI 도입 자체의 구조적 부작용이라는 신호로 읽힌다.
페이월 너머에 있는 “Stage 3로 가는 법"이 궁금하다. 의사결정을 AI에 위임하라는 방향이 명확한 만큼, 어디까지 위임할 것인가, 어떻게 검증·롤백 체계를 둘 것인가가 처방의 핵심이 될 것이다. 그 부분은 인사이트 아티클로 따로 이어가 보고 싶다.
출처
- 저자: Azeem Azhar, Nathan Warren
- 발행: Exponential View, 2026년 5월 28일
- 원문: https://www.exponentialview.co/p/why-ai-isnt-showing-up-on-your-bottom-line
- 본 다이제스트는 무료 공개분(Stage 1~3 정의와 congestion 진단까지)을 정리한 것이다. “How to move to Stage 3” 섹션은 유료 구독 영역이라 다루지 않았다.
원문: https://www.exponentialview.co/p/why-ai-isnt-showing-up-on-your-bottom-line ↩︎
자료 설명: Rapid Response, “Uber’s swerve on gas prices, hotels & a driverless future”: https://mastersofscale.com/episode/ubers-swerve-on-gas-prices-hotels-a-driverless-future/ ↩︎
자료 설명: Anthropic Series G 공식 발표와 Dealroom 인터뷰 요약: https://www.anthropic.com/news/anthropic-raises-30-billion-series-g-funding-380-billion-post-money-valuation, https://app.dealroom.co/news/note/the-250m-to--30b-rocket-ship-anthropic-s-cfo-pulls-back-the-curtain ↩︎
자료 설명: Oliver Wyman Forum, The CEO Agenda 2026: https://www.oliverwymanforum.com/ceo-agenda/how-ceos-navigate-geopolitics-trade-technology-people.html ↩︎
자료 설명: Robert Solow, We’d Better Watch Out: http://digamo.free.fr/solow87.pdf ↩︎
자료 설명: Paul David, The Dynamo and the Computer: https://www.almendron.com/tribuna/wp-content/uploads/2018/03/the-dynamo-and-the-computer-an-historical-perspective-on-the-modern-productivity-paradox.pdf ↩︎
자료 설명: Erik Brynjolfsson 외, NBER Working Paper w25148: https://www.nber.org/system/files/working_papers/w25148/w25148.pdf ↩︎
자료 설명: Louis Bell (1891), 중앙 발전 효율 인용 경로: https://www.osti.gov/servlets/purl/6774921/ ↩︎
자료 설명: Warren D. Devine Jr., “From Shafts to Wires”: https://www.cambridge.org/core/services/aop-cambridge-core/content/view/500078D9B4764BA1109A7967437CF226/S0022050700029673a.pdf/from-shafts-to-wires-historical-perspective-on-electrification.pdf ↩︎
자료 설명: F. B. Crocker 외 (1895), “Electric Power in Factories and Mills”: https://books.google.com/books/about/Transactions_of_the_American_Institute_o.html?id=ll9VAAAAYAAJ ↩︎
자료 설명: David E. Nye, “What Was the Assembly Line?”: https://tidsskrift.dk/temp/article/view/24974 ↩︎