3줄 요약
- KAIKAKU.AI의 Radzikowski & Chen이 한 달 전 자매 논문(Multidimensional Flavor Structure)에 이어 내놓은 후속작으로, 414만 개 다국어 레시피로 처음부터 다시 학습한 세 자매 식재료 임베딩(Cooc·Core·Chem)을 제시한다.
- 세 모델은 아키텍처·하이퍼파라미터·어휘·그래프를 전부 공유하고 오직 랜덤워크 스키마만 다르게 하여, “화학 vs 레시피-맥락"을 숨은 귀납 편향이 아닌 조정 가능한 설계 축으로 노출한다.
- 같은 300차원 공간 위에 두 연산자 패밀리 — 최근접 페어링과 SLERP 방향 회전 — 를 올려, 추천(recommendation)을 넘어 임베딩 공간의 항해(navigation) 도구로 나아간다.
자매 논문에서 무엇이 달라졌나
4월 자매 논문은 FlavorGraph의 단일 300차원 임베딩을 LLM 큐레이션으로 정제하면 맛·질감·문화·영양 등 15개 독립 차원이 이미 그 안에 들어 있음을 보였다. 발견의 논문이었다.
저자들은 그 분석이 FlavorGraph의 고정된 사전학습에 세 가지로 묶여 있었다고 진단한다.
- 영어 중심의 단일 코퍼스
- 화학 신호와 레시피-맥락 신호가 하나의 고정된 비율로 섞여 있음
- 조리법·비식품이 섞인 흩어진 식재료 어휘
Epicure는 이 세 제약을 동시에 들어내기 위해 임베딩을 처음부터 다시 학습한다. 그 결과가 한 가족의 세 자매 모델이다.
다국어 코퍼스와 1,790개 정본 식재료
11개 공개 데이터셋, 7개 언어에서 4,135,189개 레시피를 모았다. 영어 RecipeNLG(53.9%)와 중국어 XiaChuFang(37.4%)이 대부분을 차지하고, 러시아어 Povarenok(3.5%)와 베트남어·스페인어·터키어·인도네시아어·독일어·인도 영어의 소규모 코퍼스가 나머지를 채운다.
원시 개체명 추출(NER)은 약 20만 개의 식재료 문자열을 쏟아내는데, 철자 변형·브랜드명·비식품·조리 수식어가 대부분이다. LLM 정규화 파이프라인이 이를 1,790개 정본 식재료로 압축한다.
- 비영어 항목 번역과 분류: Claude Opus 계열(내부 배포 ID 4.6), 결정적 디코딩(temperature 0)
- 의미 클러스터링: Google
gemini-embedding-001 - 마지막에 수동 큐레이션 한 차례
정본 1,790개 중 USDA·FlavorDB 앵커가 매칭되어 활성 화학 엣지를 갖는 것은 523개(화학 허브)뿐이고, 나머지 1,267개는 비허브로 화합물 맥락을 간접 경로로만 받는다.
세 자매 모델: 화학 vs 레시피-맥락을 조정축으로
두 종류의 그래프가 토대다.
| 그래프 요소 | 규모 |
|---|---|
| 식재료 노드 | 1,790 |
| NPMI 동시출현 엣지 (I–I) | 203,508 |
| 유형화 화합물 노드 (15개 풍미 범주) | 2,247 |
| 유형화 식재료–화합물 엣지 (I–C) | 80,019 |
세 모델은 300차원·walks_per_node=100·walk_length=50·context=7·20 epochs·동일 시드까지 모든 설정을 공유한다. 차이는 skip-gram 목적함수가 보는 랜덤워크가 무엇이냐 하나뿐이다.
- Epicure-Cooc — 동시출현 그래프만 걷는다. 화합물 노드 없음. 순수 레시피-맥락.
- Epicure-Chem — 유형화 화합물 메타패스만 걷는다(
ii_repeat=0). 화학 극단. - Epicure-Core — 둘을 혼합. 순수 식재료–식재료 워크를
ii_repeat=10으로 주입하여 화학과 레시피-맥락을 섞는다.
세 모델은 이렇게 단일 실험 설계 안에서 “화학 ↔ 레시피-맥락” 스펙트럼을 한 점씩 차지한다. 핵심 방법론적 이동은 — walk 스키마를 바꿀 수 없는 아키텍처 상수가 아니라 이름 붙은 축으로 다룬 것이다.
기하학: 등방성과 문화권 구조
세 모델은 walk 스키마만으로 서로 다른 기하학적 성격을 갖는다.
| 모델 | Participation Ratio (등방성 ↑) | 평균 쌍별 코사인 ↓ |
|---|---|---|
| Cooc | 173.6 | 0.099 |
| Core | 94.2 | 0.349 |
| Chem | 183.1 | 0.117 |
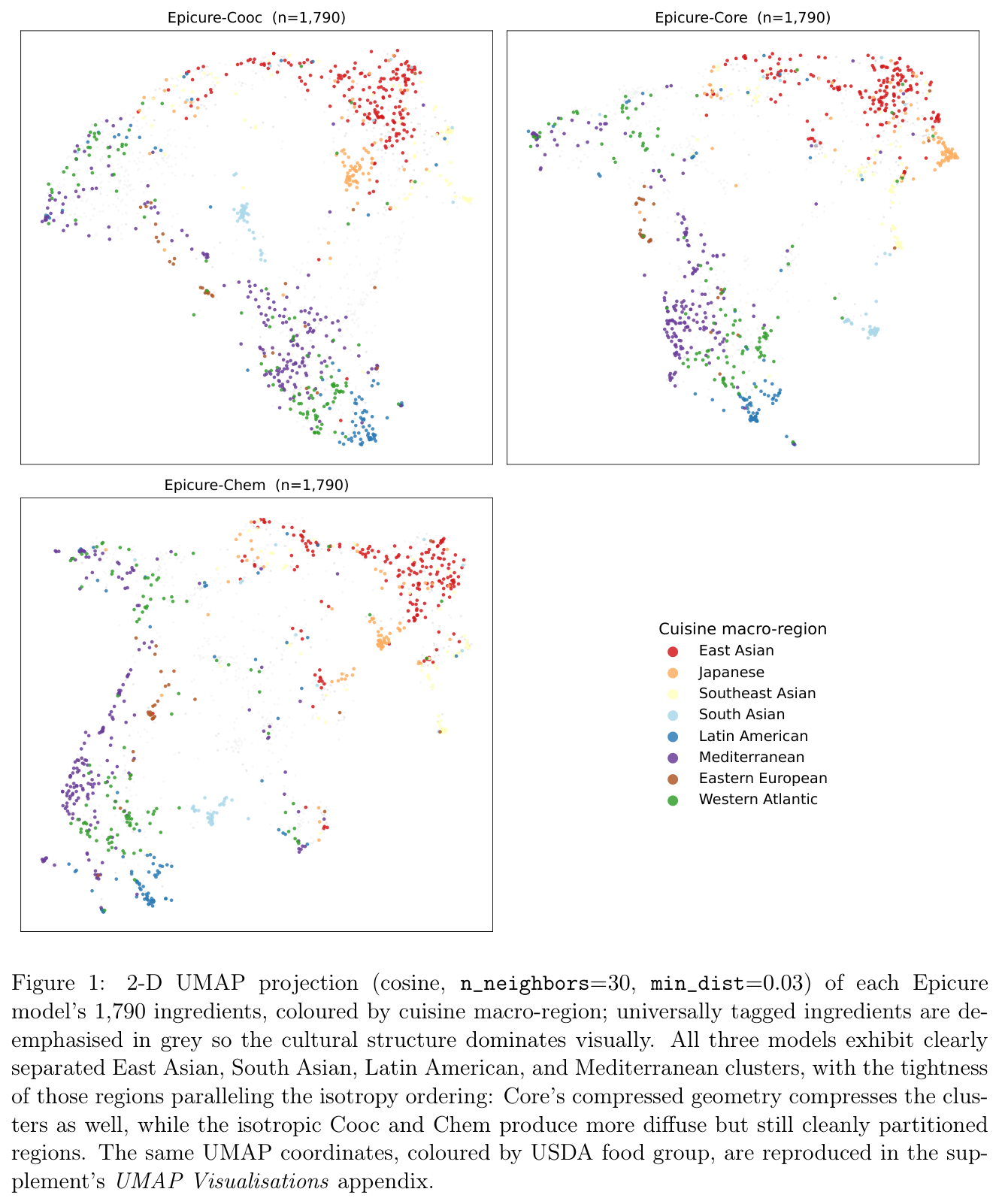
Core만 유독 공간이 집중되어 있는데, 이는 입력 데이터가 무너진 게 아니라 10배 I–I 워크 주입이 만든 의도된 결과다(강한 레시피-맥락 인력). 라벨 없이도 세 모델 모두 USDA 식품군(NMI 0.20~0.25)과 8개 요리 거대권역(soft NMI 0.43~0.46) 주위로 스스로 조직되며, 문화권이 식품군보다 약 2배 더 깨끗하게 분리된다. 문화 전통이 영양 범주보다 식재료 동시출현을 더 선명하게 빚는다는 뜻이다.

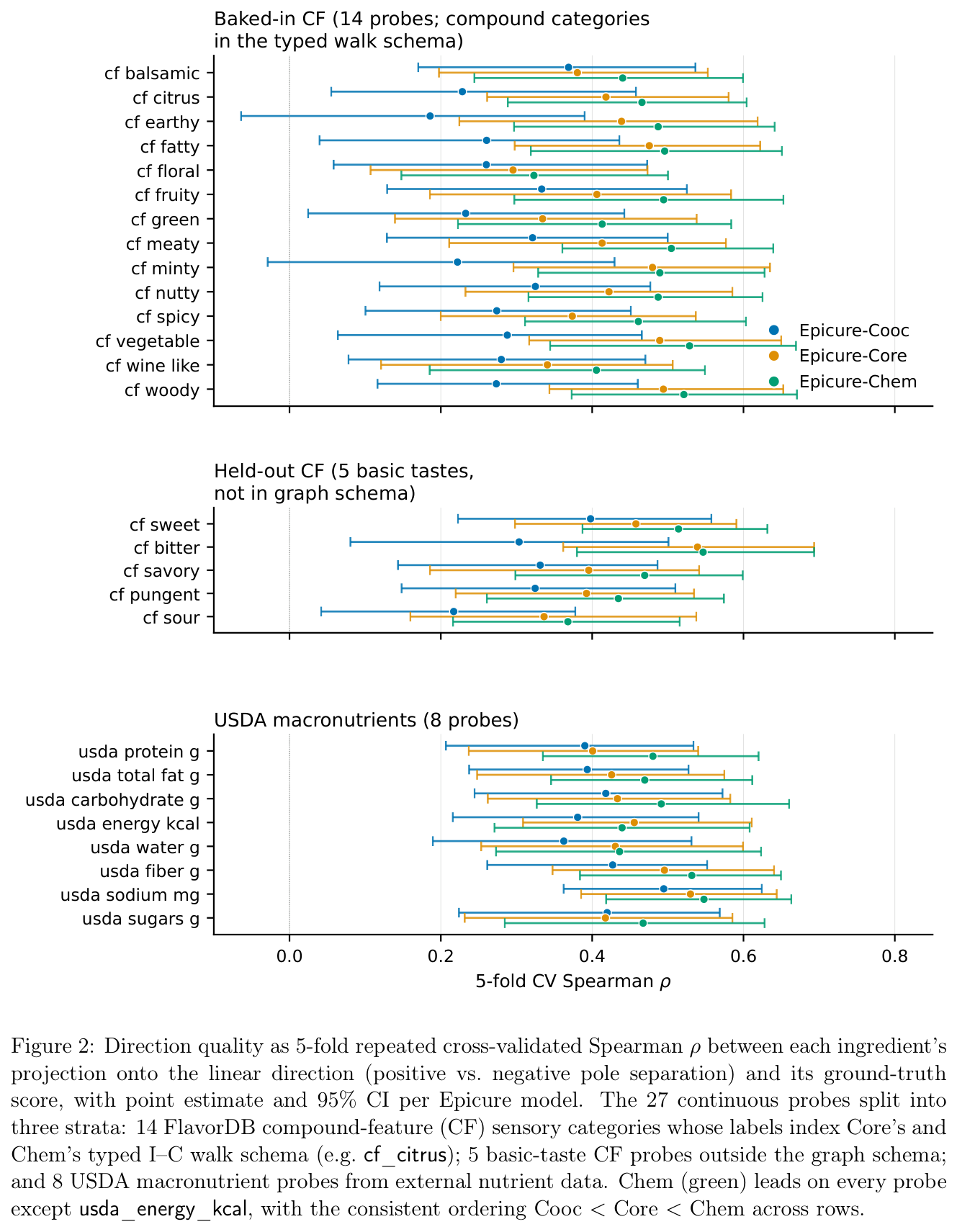
방향 품질: Cooc < Core < Chem
라벨된 요리 개념이 선형 방향으로 복원되는지를 5겹 교차검증으로 측정했다. 27개 연속 프로브와 8개 요리권 전부에서 Cooc < Core < Chem 순서가 일관되게 나타난다.
| 프로브 층 | Cooc | Core | Chem |
|---|---|---|---|
| 내장 화합물-특징(CF) 14종 (ρ̄) | 0.28 | 0.40 | 0.46 |
| 보류 기본맛 CF 5종 (ρ̄) | 0.32 | 0.42 | 0.47 |
| USDA 거시영양소 8종 (ρ̄) | 0.41 | 0.45 | 0.49 |
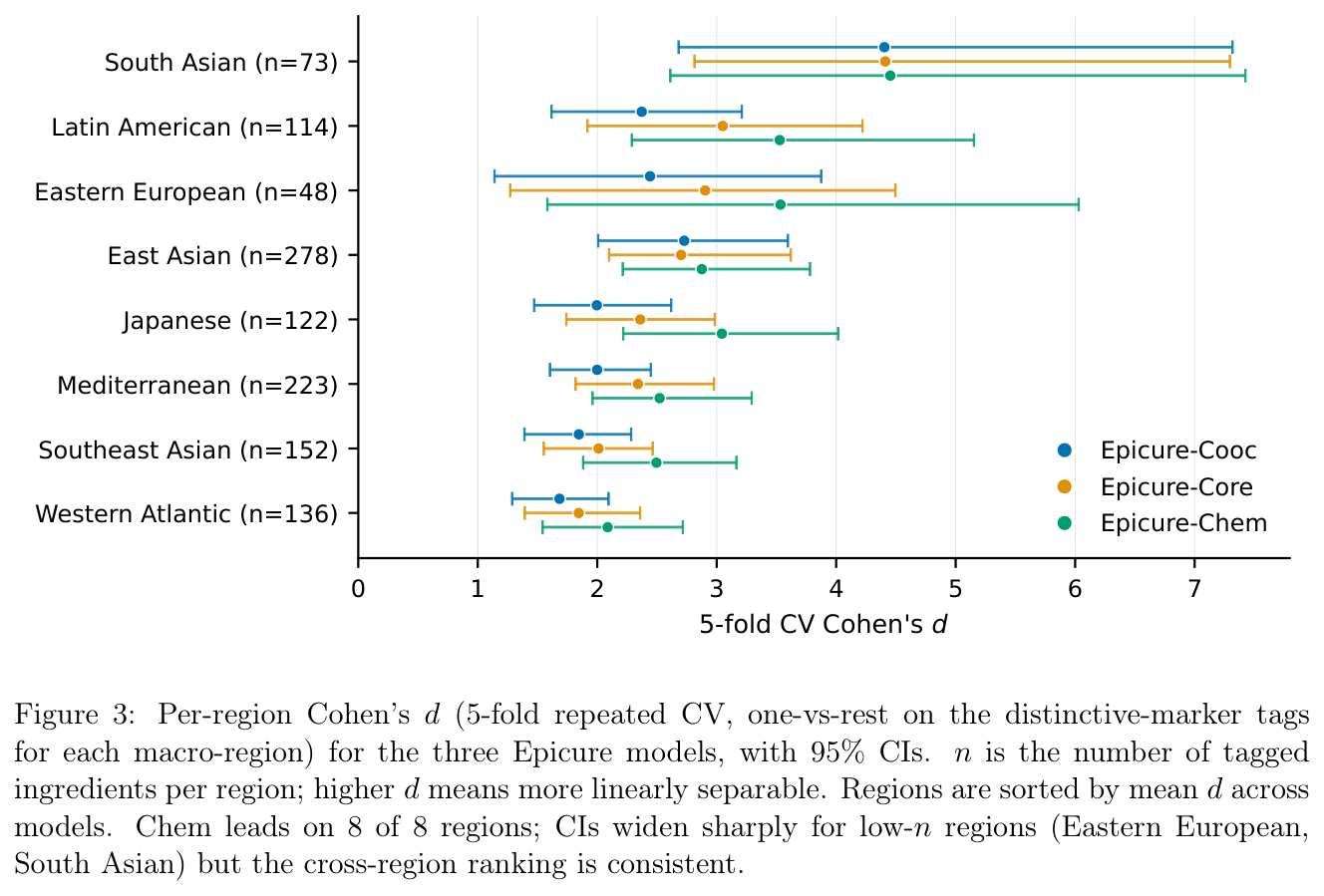
| 요리 거시권역 8종 (Cohen’s d̄) | 2.43 | 2.70 | 3.07 |
Chem은 27개 연속 프로브 중 26개에서 Core를, 27개 전부에서 Cooc를 이기고, 8개 요리권 전부를 리드한다. 주목할 점은 화학 walk 스키마가 직접 인코딩하지 않는 기본맛·USDA 영양소·요리권 프로브에서도 이 순서가 유지된다는 것이다. 즉 화학 매개 워크는 자기가 직접 보는 라벨 너머까지 미치는 구조적 prior로 작동한다.
창발적 인자와 모드
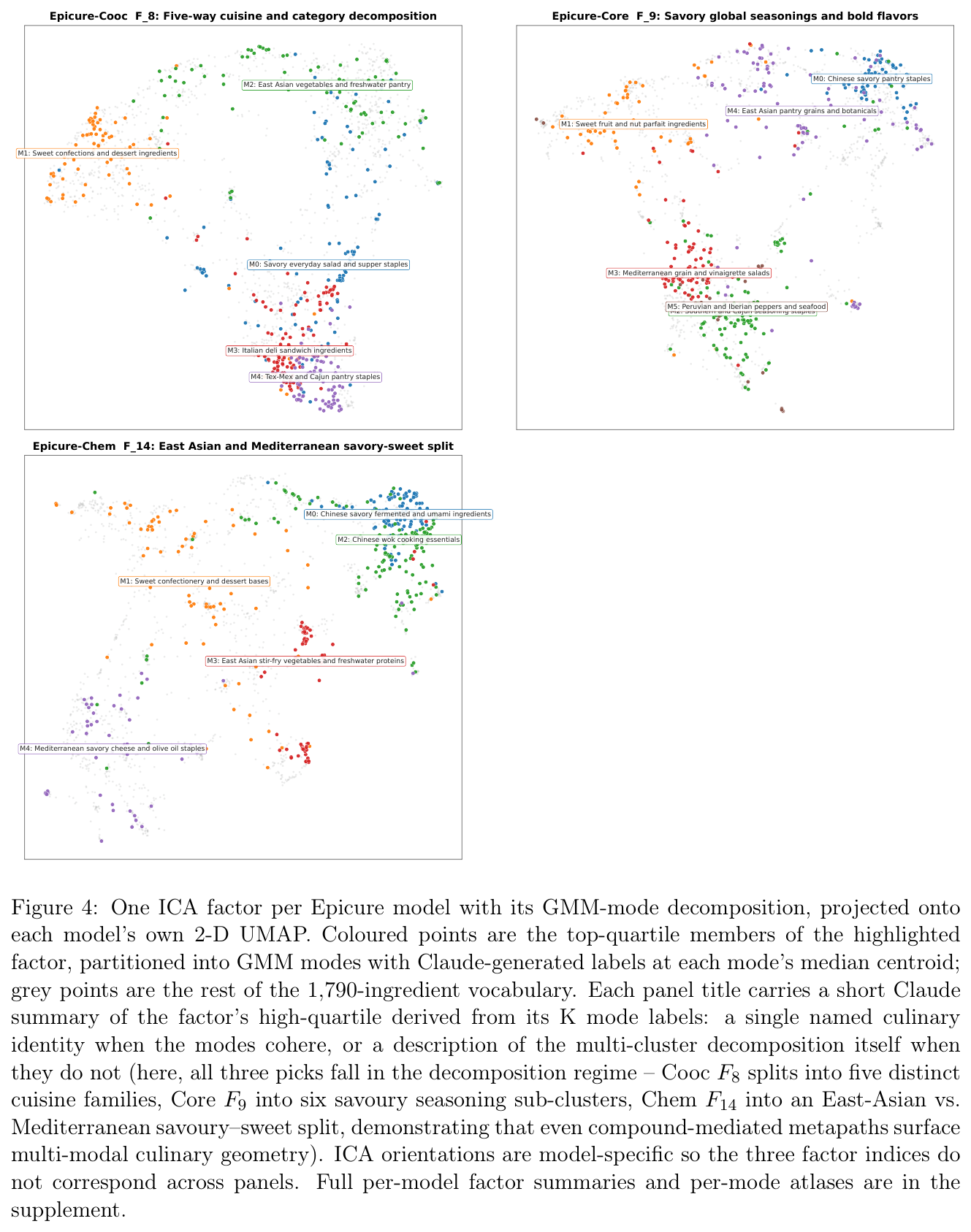
라벨을 전혀 쓰지 않고 임베딩의 자연스러운 축을 찾기 위해, 식품군 잔차에 FastICA를 적용해 모델당 20개 안정 인자를, 각 인자의 상위 사분위를 GMM으로 쪼개 모델당 150~200개 모드를 추출했다(Cooc 150개, Core 193개, Chem 200개). 각 모드는 “달콤한 베이킹·디저트 재료”, “남아시아 통향신료 블렌드”, “멕시코·라틴 팬트리"처럼 명명된 요리 이웃으로 읽힌다.
이 창발적 모드는 세 모델 모두에서 무작위 쌍 기준선 대비 5~6배 응집한다.
| 모델 | 모드 응집도 | 무작위 쌍 기준선 |
|---|---|---|
| Cooc | 0.611 | 0.097 |
| Core | 0.833 | 0.348 |
| Chem | 0.703 | 0.115 |
응집도와 기준선의 차이(tightness margin)는 세 모델 모두 약 0.5로 비슷하다. 절대 응집도는 각 모델의 집중도를 따라가서, Core의 집중된 기하학이 모드 응집과 기준선을 함께 끌어올린다.
변환: 페어링과 SLERP 항해
이 기하학 위에 두 연산자 패밀리가 올라간다.
페어링 — “X와 무엇이 어울리나”
12개 기준 재료에 대해 top-5 코사인 최근접 이웃과 가장 가까운 창발적 모드를 계산한다. 흥미로운 것은 같은 재료가 모델에 따라 다른 종류의 답을 준다는 점이다. 바질(basil)을 예로 들면:
- Cooc: 파슬리, 올리브유, 파마산 치즈, 후추, 화이트와인 → 레시피 동반자
- Chem: 타라곤, 오레가노, 로즈마리, 파스타, 펜넬 → 풍미 프로파일 peer(같은 허브류)
같은 씨앗 재료가 Cooc에서는 “함께 요리되는 것"을, Chem에서는 “풍미가 닮은 것"을 돌려준다. 비교군으로 둔 FlavorGraph는 “sourdough roll”, “kraft shredded triple cheddar cheese with a touch of philadelphia” 같은 긴 브랜드·조리 단계 문자열을 반환하는데, 1,790개 정본 어휘가 이런 잡음을 정리한다.
SLERP — 단위 구면 위의 방향 회전
씨앗 벡터를 단위 구면에서 angle θ만큼 목표 방향으로 회전시킨다. 0°는 원본 그대로, 60°에서는 씨앗과의 코사인 유사도가 0.5로 떨어져 목표의 이웃이 우세해진다. 목표 방향은 supervised pole(요리권·식품군·NOVA 가공등급) 또는 창발적 모드 pole 중에서 고른다.
rice + 남아시아30° → 커리잎, 마수르 달, 우라드 달, 차나 달, 호로파 씨corn + 라틴아메리카30° → 살사 베르데, 토마티요, 케소 프레스코, 파히타 시즈닝, 옥수수 토르티야chicken + 가공 + 서대서양60° → 스위스 치즈, 스테이크 소스, 칠면조, 사워크림, 랜치 드레싱(20세기 중반 미국 가정식)
라벨 정렬이 예측 가능하게 작동하는, 다루기 쉬운 조향 연산자다.
한계
- 코퍼스 불균형 — 절반이 동아시아, 1/10이 지중해. 남아시아·동유럽·라틴아메리카는 한 자릿수 비중이라 해당 권역 내부 해상도가 떨어진다(권역 간 순위는 안정적).
- 허브 커버리지 — 1,790개 중 523개만 FlavorDB 화학 허브. 나머지 1,267개 비허브는 화합물 맥락을 한 워크 홉 더 먼 경로로만 받는다.
- 파이프라인의 LLM 의존 — 정규화·요리권 태깅·모드 라벨 생성에 Claude를 쓴다. 다만 임베딩 자체는 LLM-free다(skip-gram이 보는 것은 워크 시퀀스뿐). 기하학은 LLM 판단에 직접 조건화되지 않지만, 노드 집합을 정의하는 정본 어휘는 LLM에 의존한다.
가장 흥미로운 지점
자매 논문이 “동시출현 통계가 셰프 암묵지의 충분통계량"이라는 발견이었다면, 이번 후속작의 통찰은 그 위에서 사용자가 무엇을 어떻게 물을지를 분해해 낸 데 있다. 저자들은 사용자 대면 연산을 세 개의 독립 선택으로 정리한다.
어느 자매를 쿼리할지(동시출현 동반자냐 풍미 프로파일 peer냐) · 어느 방향으로 회전할지(라벨 기반 pole이냐 창발적 모드 pole이냐) · 얼마나 멀리 갈지(SLERP 각도) — 이 셋이 모두 같은 300차원 임베딩 위에서 표현된다.
귀납 편향을 네트워크 선택 속에 숨기는 대신 이름 붙은 조정 가능한 축으로 끌어낸다는 이 방법론적 이동은, 앞으로 화학·영양·감각·이미지·레시피-텍스트 신호를 융합할 어떤 작업에도 그대로 적용된다. 다만 자매 논문이 인터랙티브 3D 탐색기를 공개한 것과 달리, 이번 논문의 코드와 학습 산출물은 현 시점 비공개다.
한 가지 더 눈에 띄는 것은 이 연구 자체가 데이터 파이프라인 전반 — 번역·정규화·중복 판정·요리권 태깅·방향 품질의 정답 감각 점수 — 에 Claude Opus 계열을 깊이 사용했다는 점이다. 임베딩의 기하학은 LLM-free이지만, 그 기하학이 자리 잡을 어휘의 경계는 LLM이 그었다.
출처
Jakub Radzikowski, Josef Chen (KAIKAKU.AI), 2026년 5월 원문: https://arxiv.org/abs/2605.22391 자매 논문 다이제스트: Epicure: Multidimensional Flavor Structure in Food Ingredient Embeddings
본문 도식은 원문 PDF의 Figure 1~5를 인용했다(저자 KAIKAKU.AI).