3줄 요약
- Sakana AI와 도쿄대가 2025년 6월 공개하고 ICLR 2026에 채택된 논문(arXiv:2506.14202). 엔드투엔드 역전파가 학습 내내 모든 계층의 활성값을 들고 있어야 한다는 메모리 병목을, 네트워크를 독립 학습 가능한 블록으로 쪼개 푼다.
- 핵심 통찰은 하나다 — 트랜스포머의 잔차 연결 $z_\ell = z_{\ell-1} + f(z_{\ell-1})$이 확산 모델의 ODE를 한 스텝 이산화한 식과 같은 형태라는 것. 그래서 각 블록을 특정 노이즈 구간을 맡는 denoiser로 바꾸면 블록마다 독립으로 학습할 수 있다.
- 비전·이미지 생성·언어 등 5개 아키텍처에서 엔드투엔드에 필적하면서 학습 메모리를 블록 수만큼(3~4배) 줄였다. 의외로 적당히 쪼갠 경우(B=2, 3)는 엔드투엔드를 능가하기도 했다.
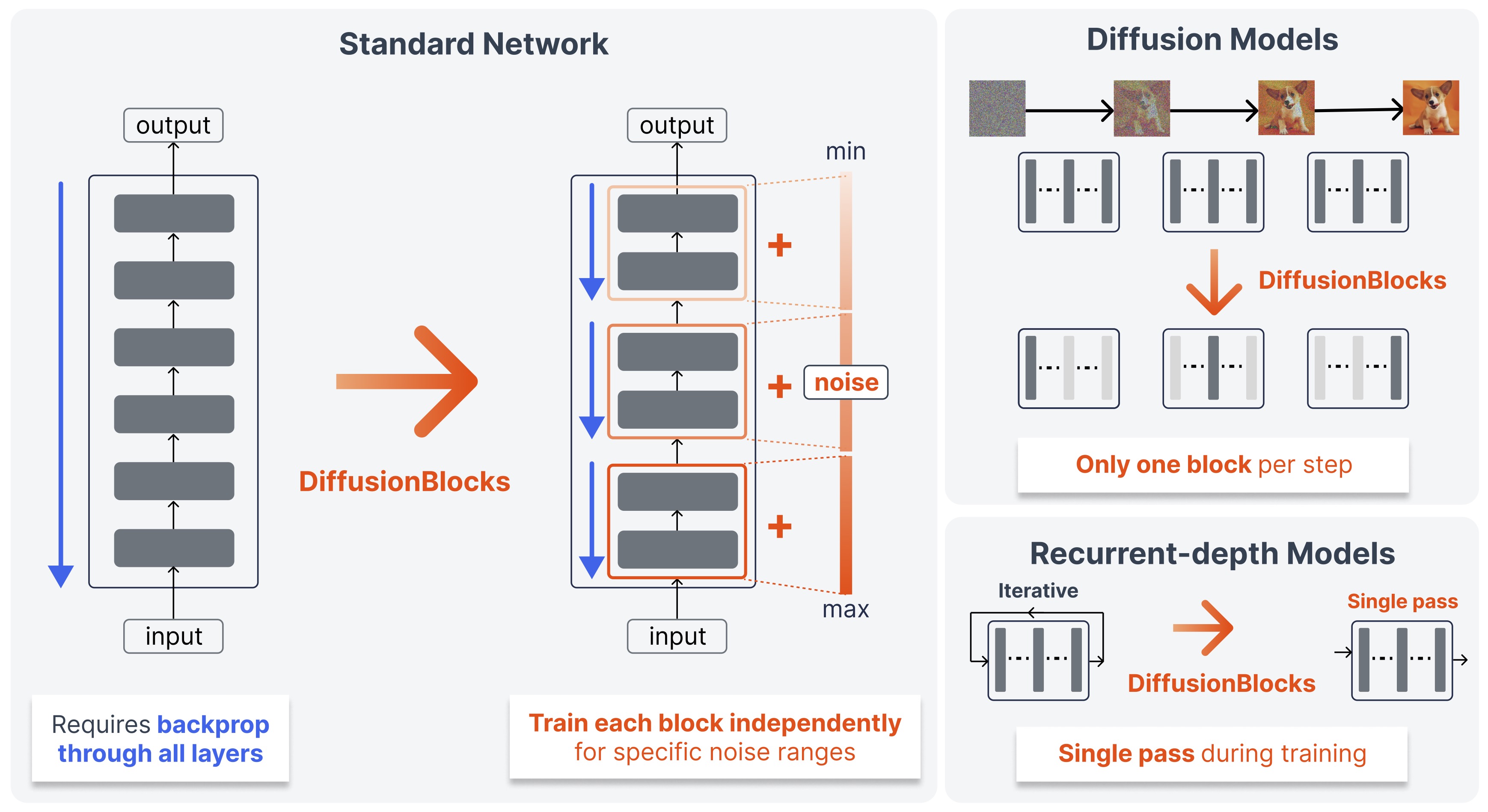
 DiffusionBlocks 개요. 출처: github.com/SakanaAI/DiffusionBlocks
DiffusionBlocks 개요. 출처: github.com/SakanaAI/DiffusionBlocks
무엇이 문제였나 — 역전파의 메모리 병목
엔드투엔드 역전파는 그래디언트를 거꾸로 흘려보내려고 순전파 때 거쳐 간 모든 계층의 중간 활성값을 메모리에 쥐고 있어야 한다. 그래서 메모리 소비가 네트워크 깊이에 선형으로 비례해 커진다. 모델을 깊게 키울수록 이 비용이 곧장 벽이 된다.
이 벽을 피하려는 오래된 아이디어가 블록 단위 학습(block-wise training)이다. 네트워크를 작은 조각으로 나눠 조각마다 따로 학습하면, 한 번에 한 조각의 활성값만 들고 있으면 되니 메모리가 극적으로 준다. 문제는 지금까지의 방법들이 두 가지 한계를 못 벗어났다는 것이다.
- 이론적 근거 부재. 블록 사이를 어떻게 조율할지에 대한 원리 없이, 그때그때 만든 국소 목적함수(ad-hoc local objective)에 기댔다. 국소적으로 잘 풀어도 전역 성능이 보장되지 않았다.
- 분류 너머로 확장이 안 됨. Forward-Forward(Hinton, 2022) 같은 대표적 방법은 대조(contrastive) 목적함수에 묶여 본질적으로 분류 과제에 한정됐고, 생성 과제로의 확장이 막막했다. 커스텀 아키텍처 위에서만 시연됐을 뿐 트랜스포머 같은 현대 구조에 적용할 체계적 절차가 없었다.
실제로 이 논문이 ViT 분류에서 Forward-Forward를 돌려 보니 정확도가 7.85%에 그쳤다(엔드투엔드 60.25%). 원리 없는 국소 목적함수가 얼마나 쉽게 무너지는지를 보여주는 대목이다.
핵심 통찰 — 잔차 연결은 확산 과정의 한 스텝이다
잔차 네트워크가 미분방정식과 닮았다는 관찰은 새롭지 않다(Neural ODE 계열). 이 논문은 그 관찰을 확산 모델 쪽으로 한 걸음 더 끌고 간다.
확산 모델은 깨끗한 데이터에 노이즈를 점점 더해 망가뜨린 뒤, 그 과정을 거꾸로 되감는 법을 배운다. 되감는 연속시간 과정은 probability-flow ODE로 적히고, 이를 오일러 방식으로 한 스텝씩 이산화하면 다음 꼴이 된다.
$$z_{\sigma_\ell} = z_{\sigma_{\ell-1}} + \frac{\Delta\sigma_\ell}{\sigma_{\ell-1}}\big(z_{\sigma_{\ell-1}} - D_\theta(z_{\sigma_{\ell-1}}, \sigma_{\ell-1})\big)$$여기서 $D_\theta$는 노이즈를 걷어내는 denoiser다. 이 갱신식을 트랜스포머의 잔차 업데이트 $z_\ell = z_{\ell-1} + f_{\theta_\ell}(z_{\ell-1})$와 나란히 놓으면 형태가 같다. 즉 계층의 순차적 업데이트를 연속시간 노이즈 제거 과정의 한 스텝으로 읽을 수 있다.
이게 왜 결정적이냐면, 확산 모델에는 기존 블록 학습에 없던 성질이 있기 때문이다 — 각 노이즈 레벨의 denoising은 다른 레벨과 무관하게 독립적으로 최적화할 수 있다. 이 독립성이 블록 분할의 이론적 근거가 된다. 네트워크를 노이즈 구간별 블록으로 나눠도, 각자 자기 구간만 잘 풀면 전체 역과정의 충실한 근사가 자동으로 따라온다. ad-hoc 목적함수가 아니라 score matching 이론에서 각 블록의 목적함수가 유도되는 것이다.
방법 — 신경망을 DiffusionBlocks로 바꾸는 3단계
논문은 잔차 구조를 가진 네트워크(특히 트랜스포머)를 최소 수정으로 변환하는 레시피를 제시한다.
- 블록 분할. $L$개 계층을 $B$개 블록으로 묶는다.
- 노이즈 구간 할당. 노이즈 분포 $p_\text{noise}$(log-normal 권장)를 정하고 노이즈 범위 $[\sigma_\text{min}, \sigma_\text{max}]$를 $B$개 구간으로 나눠 블록마다 하나씩 맡긴다.
- 노이즈 조건화 증강. 입력을 $\tilde{x} = (x, z)$로 확장하고 AdaLN 등으로 노이즈 레벨을 조건화해, 각 블록이 자기 구간의 denoiser 역할을 하게 만든다.
이렇게 바꿔도 잔차 구조는 거의 그대로 보존된다. 변환 뒤 각 블록은 자기 노이즈 구간에 한정된 score-matching 목적함수로 학습되며, 이전 계층의 출력을 기다릴 필요가 없다. 활성값과 그래디언트를 활성 블록(전체의 $L/B$ 계층)에 대해서만 저장하면 되니, 학습 메모리가 블록 수 $B$에 비례해 줄어든다.
Equi-probability 분할 — 어려운 노이즈에 용량을 집중한다
노이즈 구간을 어떻게 나눌지가 중요한 설계 선택이다. 단순히 균등 간격으로 나누면 노이즈 레벨마다 난이도가 다르다는 사실을 놓친다. 그래서 논문은 누적 확률 질량이 같도록 나눈다.
$$\int_{\sigma_b}^{\sigma_{b-1}} p_\text{noise}(\sigma)\, d\sigma = \frac{1}{B}$$log-normal 분포는 확률 질량이 중간 노이즈 레벨에 몰려 있는데, 바로 그 구간이 denoising이 가장 어렵고 생성 품질에 가장 크게 기여하는 곳이다. 누적 확률 질량으로 나누면 어려운 중간 레벨에는 좁고 촘촘한 구간이, 매우 높거나 낮은 레벨에는 넓은 구간이 배정된다. 블록 간 학습 난이도와 파라미터 활용이 균형을 이루는 셈이다. 실험에서 이 전략은 균등 분할을 일관되게 앞섰다(CIFAR-10 FID 38.03 대 43.53).
실험 — 5개 아키텍처에서 엔드투엔드에 필적
논문은 변환된 네트워크(블록 단위 학습)를 원본 네트워크(엔드투엔드 학습)와 비교했다. 메모리 절감 배수는 블록 수 $B$다(한 번에 $L/B$ 계층만 그래디언트가 필요).
| 아키텍처 / 데이터 | 지표 | 엔드투엔드 | DiffusionBlocks | 메모리 |
|---|---|---|---|---|
| ViT / CIFAR-100 | 정확도 ↑ | 60.25 | 59.30 | 3× |
| DiT / ImageNet | FID(test) ↓ | 12.09 | 10.63 | 3× |
| MDM / text8 | BPC ↓ | 1.56 | 1.45 | 3× |
| AR(Llama-2형) / LM1B | MAUVE ↑ | 0.50 | 0.71 | 4× |
| Recurrent-depth(Huginn) / LM1B | MAUVE ↑ | 0.49 | 0.70 | 단일 패스 |
두 가지가 특히 눈에 띈다.
- denoising-native가 아닌 자기회귀(AR) 모델도 변환된다. AR 모델은 본래 다음 토큰 예측용이지 노이즈 제거용이 아니다. 그런데도 12층 Llama-2형 트랜스포머를 $B$=4 블록으로 변환해 생성 품질을 유지했다. 프레임워크가 확산 native가 아닌 구조에도 적용됨을 보인 결과다.
- recurrent-depth 모델의 반복 학습을 단일 패스로 갈아치웠다. 같은 파라미터를 여러 번 반복 적용하는 recurrent-depth 모델(Huginn)은 시간축 역전파(BPTT)가 비싸다. DiffusionBlocks는 학습 스텝당 단일 순전파만 요구해 32회 반복을 통째로 제거하면서 오히려 성능을 높였다.
동시기에 나온 backprop-free 기법 NoProp과 비교하면, DiffusionBlocks는 연속시간 정식화와 블록 단위 학습을 동시에 결합한 유일한 방법이었고 모든 NoProp 변종을 앞섰다(CIFAR-100 정확도 46.88 대 NoProp-DT 46.06).
가장 흥미로운 지점
가장 의외인 결과는 블록 수를 늘렸을 때의 곡선이다. ImageNet에서 블록 수 $B$를 바꿔 가며 FID를 재 보니:
| 블록 수 $B$ | FID ↓ | 블록당 계층 $L/B$ | 상대 속도 |
|---|---|---|---|
| 1 (엔드투엔드) | 12.09 | 24 | 1.0× |
| 2 | 9.90 | 12 | 2.0× |
| 3 | 11.11 | 8 | 3.0× |
| 4 | 11.90 | 6 | 4.0× |
| 6 | 14.43 | 4 | 6.0× |
메모리를 아끼려고 도입한 블록 분할이, $B$=2, 3 구간에서는 오히려 엔드투엔드(B=1)보다 나은 FID를 냈다. 저자들은 그 이유를 단정하지 않고 가설로 둔다 — 블록별 목적함수가 타깃과 직접 연결되는 최적화 구조, 노이즈 구간별 특화 효과, 그리고 난이도 균형 분할이 만드는 일종의 커리큘럼 학습 효과다. 다만 $B$가 더 커지면 블록당 용량이 줄어 품질이 점차 하락하니, 이 이득은 적당히 쪼갰을 때의 이야기다. “효율을 위한 제약이 때로 성능까지 끌어올린다"는 흥미로운 현상이지만, 같은 표 안에 반례($B$=4, 6)가 함께 있다는 점도 잊지 말아야 한다.
한계
저자들이 직접 밝힌 한계가 솔직하다.
- 입력·출력 차원이 같아야 한다. 그래서 차원이 바뀌는 U-Net류 구조에는 아직 적용이 막힌다.
- 오일러 이산화만 사용했다. 잔차 연결과 맞추려는 선택이었고, 다른 확산 샘플러는 향후 과제다.
- from-scratch 학습만 검증됐다. 그리고 검증 규모가 ViT 12층·DiT·12층 Llama-2형 수준으로, 오늘날의 대형 모델에 비하면 작다.
저자들이 가장 유망하게 꼽은 방향도 여기서 나온다 — 대형 모델로의 확장, 그리고 사전학습된 대형 모델을 처음부터 다시 학습하는 대신 fine-tune으로 DiffusionBlocks로 변환하는 길이다. 그러니 “역전파를 대체할 패러다임"이라기보다, 이론적 근거를 갖춘 블록 학습이 분류를 넘어 현대 생성 아키텍처까지 닿을 수 있음을 처음으로 체계적으로 보인 유망한 출발점으로 읽는 게 정확하다.
출처
Makoto Shing, Masanori Koyama, Takuya Akiba (Sakana AI · The University of Tokyo), “DiffusionBlocks: Block-wise Neural Network Training via Diffusion Interpretation”, ICLR 2026. 원문: https://arxiv.org/abs/2506.14202 코드: https://github.com/SakanaAI/DiffusionBlocks