
3줄 요약
- Anthropic의 Thariq Shihipar와 Sid Bidasaria가 Claude Code에 새로 출시된 동적 워크플로우(dynamic workflows) 를 소개한다. Claude가 작업마다 JavaScript 하니스를 즉석에서 작성하여, 각자 자기 컨텍스트 윈도우와 모델·worktree를 가진 서브에이전트를 spawn하고 조율하는 메커니즘이다.
- 단일 컨텍스트의 3대 실패 모드 — agentic laziness, self-preferential bias, goal drift — 를 별도 컨텍스트 윈도우로 우회하는 것이 핵심 모티브다. Opus 4.8의 지능 향상이 use case별 맞춤 하니스의 자동 작성을 가능케 했다.
- 6가지 합성 가능한 패턴(classify-and-act, fan-out-and-synthesize, adversarial verification, generate-and-filter, tournament, loop-until-done)과 10가지 활용 사례를 카탈로그로 정리한다. 다만 토큰을 많이 쓰므로 평범한 코딩 작업에는 과한 도구임을 저자도 인정한다.
동적 워크플로우란
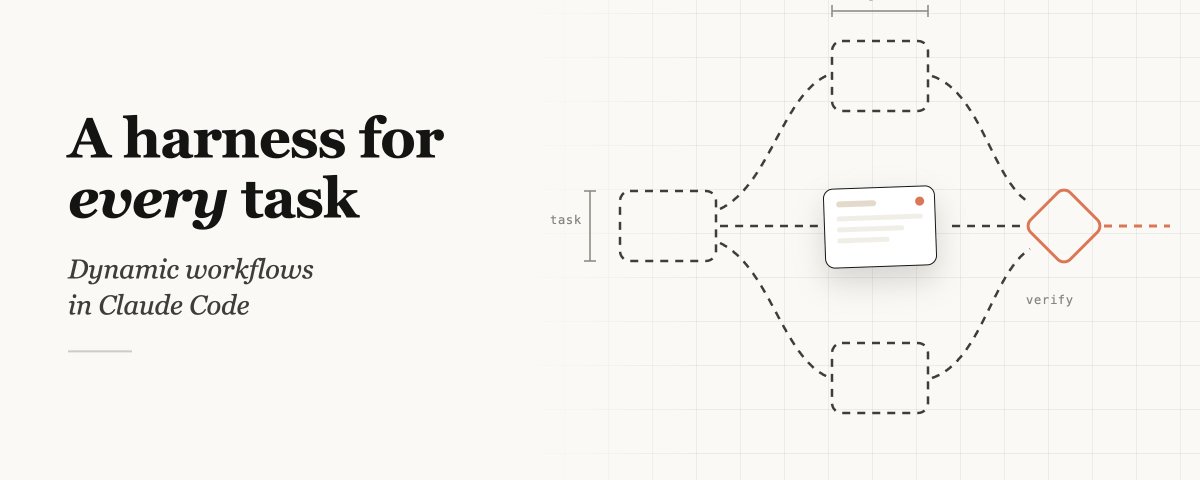
Claude can now write its own harness on the fly, custom-built for the task at hand.
동적 워크플로우는 Claude Code 안에서 작업별 하니스를 즉석에서 만들어내는 기능이다. 기본 Claude Code 하니스는 코딩 작업을 위해 설계되어 있고, 마침 다른 많은 작업도 코딩과 비슷한 형태를 띠기에 두루 쓸 수 있다. 그러나 리서치·보안 분석·에이전트 팀·코드 리뷰처럼 최고 성능이 필요한 영역에서는 그동안 Claude Code 위에 별도의 맞춤 하니스를 매번 쌓아 올려야 했다.
동적 워크플로우는 그 맞춤 하니스를 Claude가 스스로 짜게 한다.
동작 방식
워크플로우는 JavaScript 파일을 실행하며, 서브에이전트를 spawn하고 조율하는 몇 가지 특수 함수와 함께 표준 JSON·Math·Array 같은 일반 JS 기능을 모두 사용한다. 워크플로우 자체가 어떤 모델을 쓸지, 서브에이전트를 별도의 worktree에 격리할지를 결정할 수 있어 Claude가 지능 수준과 격리 정도를 작업마다 고를 수 있다. 사용자 종료나 터미널 종료로 중단된 워크플로우는 세션을 재개하면 그 자리에서 이어 받는다.
진입
워크플로우는 두 가지 방식으로 시작된다.
- Claude에게 명시적으로 “워크플로우를 만들라"고 요청한다.
- 프롬프트에 트리거 워드
ultracode를 넣어 워크플로우 생성을 강제한다.
정적 워크플로우와의 차이
이미 Claude Agent SDK나 claude -p로 여러 Claude Code 인스턴스를 엮는 정적 워크플로우를 만들어 본 사람이라면 차이가 궁금할 것이다. 정적 워크플로우는 모든 엣지 케이스를 한 코드에서 처리해야 하므로 일반화 경향이 짙다. 동적 워크플로우는 Claude Opus 4.8의 지능이 use case별 맞춤 하니스를 즉석에서 작성할 만큼 충분해진 시점에 가능해진 접근이다.
왜 분할하는가 — 단일 컨텍스트의 3대 실패 모드
기본 Claude Code 하니스는 계획과 실행을 같은 컨텍스트 윈도우에서 처리한다. 많은 코딩 작업에는 이게 잘 듣지만, 장시간·대규모 병렬·고도로 구조화된 적대적 작업에서는 다음 세 가지 실패 양상이 점점 두드러진다.
| 실패 모드 | 정의 |
|---|---|
| Agentic laziness | 복잡한 다단계 작업을 끝내기 전에 부분 진행만으로 완료를 선언하는 경향. 보안 리뷰 50개 항목 중 20개만 처리하고 작업 종료를 알리는 식. |
| Self-preferential bias | Claude가 자기 출력·발견을 선호하는 경향. 자기 결과를 루브릭에 맞춰 검증·심판하라고 시키면 후하게 평가한다. |
| Goal drift | 많은 턴이 누적되면서 원래 목표에 대한 충실도가 점진적으로 떨어지는 현상. 특히 compaction(요약) 단계가 lossy하기 때문에 엣지 케이스 요구나 “don’t do X” 같은 제약이 잘 사라진다. |
워크플로우는 각자 자기 컨텍스트 윈도우와 좁은 목표를 가진 별도의 Claude들을 오케스트레이션함으로써 이 세 모드에 구조적으로 대응한다.
6가지 워크플로우 패턴
Claude가 워크플로우를 짤 때 자주 쓰거나 조합하는 패턴 6종을 저자가 직접 정리했다.
| 패턴 | 동작 |
|---|---|
| Classify-and-act | 분류 에이전트가 작업 유형을 판단해 그에 맞는 에이전트·로직으로 라우팅. 또는 마지막 단계에 분류기를 두어 출력 타입을 결정. |
| Fan-out-and-synthesize | 작업을 다수 하위 단계로 쪼개 각각 별도 에이전트로 실행한 뒤, 합성 단계가 배리어 역할을 하며 모든 fan-out 에이전트의 구조화된 출력을 하나로 병합. 단계 간 컨텍스트 교차 오염을 막는 데 특히 유용. |
| Adversarial verification | spawn된 에이전트마다 별도의 검증 에이전트를 붙여 루브릭·기준에 따라 적대적으로 출력을 검증. |
| Generate-and-filter | 주제에 대해 다수 아이디어를 생성한 뒤 루브릭·검증으로 거르고 중복을 제거해 가장 품질 높은 아이디어만 반환. |
| Tournament | 같은 작업을 N개의 에이전트가 서로 다른 접근으로 시도하고, 심판 에이전트가 pairwise로 결과를 비교하며 우승자를 가린다. 분할이 아니라 경쟁으로 품질을 끌어올리는 방식. |
| Loop-until-done | 작업량을 미리 알 수 없는 상황에서 고정 횟수 대신 종료 조건(새 발견 없음·로그에 더 이상 에러 없음 등)이 충족될 때까지 에이전트를 반복 spawn. |
활용 사례
저자는 워크플로우가 기술적 작업뿐 아니라 비기술적 작업에서 오히려 더 유용한 경우가 많다고 강조한다.
마이그레이션과 리팩터
Bun이 Zig에서 Rust로 다시 쓰인 사례가 워크플로우 기반이었다. 핵심은 작업을 callsite·실패 테스트·모듈 같은 단위로 분해하고, 단위마다 worktree에서 수정 서브에이전트를 띄운 뒤 다른 에이전트가 적대적으로 리뷰하고 머지하는 흐름이다. 리소스 집약적 명령을 피하라고 미리 지시해 두면 머신 리소스가 마르지 않게 병렬을 최대화할 수 있다.
딥 리서치
Anthropic은 동적 워크플로우를 쓰는 /deep-research 스킬을 Claude Code 안에서 함께 출시했다. 웹 검색을 fan-out하고, 소스를 가져와 주장을 적대적으로 검증한 뒤 인용된 보고서로 합성한다. 같은 패턴이 슬랙에서 상태 보고서를 모으거나 코드베이스를 깊이 탐색해 기능 동작을 조사하는 일에도 적용된다.
딥 검증
반대 방향도 있다. 보고서의 모든 사실 주장을 출처와 함께 검증하고 싶다면, 주장 추출 에이전트가 사실 항목을 모두 골라낸 뒤 항목마다 출처 확인 서브에이전트를 spawn하는 워크플로우를 만들 수 있다. 출처 자체의 품질을 또 다른 검증 에이전트가 점검하는 다단 구조도 가능하다.
정렬 (Sorting)
Comparative judgment is more reliable than absolute scoring.
지원 티켓을 버그 심각도로 정렬하는 식의 질적 평가 기반 정렬은 한 프롬프트에 1000개 이상을 넣으면 품질이 망가지고 컨텍스트도 넘친다. 대신 토너먼트나 pairwise 비교 에이전트 파이프라인을 돌리거나, 병렬 버킷 랭킹 후 머지하는 방식이 권장된다. 각 비교는 자체 에이전트가 담당하므로, 결정적 루프는 진행 순서만 컨텍스트에 들고 있게 된다. 절대 점수보다 쌍대 비교가 신뢰성이 높다는 원칙이 명시적으로 강조된다.
메모리와 규칙 준수
CLAUDE.md에 넣어도 Claude가 자꾸 빠뜨리는 규칙이 있다면, 규칙 목록을 검증자 에이전트들이 각각 점검하는 워크플로우를 만든다. 규칙당 한 명의 검증자. 거짓 양성을 막기 위해 회의주의자 페르소나 서브에이전트가 규칙 자체의 타당성을 검토하게 두는 것도 좋다.
역방향도 작동한다. 최근 세션과 코드 리뷰 코멘트에서 반복해서 고치는 부분을 채굴하고, 병렬 에이전트로 클러스터링하고, 후보마다 이 규칙이 있었다면 실제 실수를 막았을까? 를 적대적으로 검증한 뒤 살아남은 규칙만 CLAUDE.md로 옮기는 흐름이다.
근본 원인 조사
디버깅은 독립 가설 여럿을 동시에 시험할 때 가장 잘 작동한다. 단일 컨텍스트에서는 self-preferential bias가 끼어들기 쉽다. 워크플로우는 증거 출처를 분리해 — 로그·파일·데이터 등 — 출처별로 가설 에이전트를 띄우고, 각 가설을 검증자·반박자 패널이 다투게 한다. 이 접근은 코드뿐 아니라 매출 하락 원인 분석이나 데이터 파이프라인 실패 같은 사후 분석 일반에 적용된다.
대규모 트리아주
어떤 팀이든 사람이 다 처리하지 못하는 지원 큐·버그 리포트·백로그를 가지고 있다. 트리아주 워크플로우는 각 항목을 분류하고, 이미 추적 중인 것과 중복을 제거하고, 수정 시도 또는 사람에게의 에스컬레이션으로 조치한다.
여기서 특히 두드러지는 보안 패턴이 quarantine 이다. 신뢰할 수 없는 공개 콘텐츠를 읽는 에이전트에게는 고권한 액션을 허용하지 않는다. 실제 행동은 별도 에이전트가 처리한다. 프롬프트 인젝션·악의적 입력의 영향 범위를 권한 분리로 차단하는 방식이다.
트리아주 워크플로우는 /loop와 결합해 정기 간격으로 연속 운영할 수 있다.
탐색과 취향
디자인이나 작명처럼 취향 기반 작업에는 다수 안을 탐색하게 한 뒤 좋은 안의 기준 루브릭을 가진 리뷰 에이전트를 붙인다. 토너먼트나 루브릭 기반 선택으로 후보를 추리는 방식.
평가 (Evals)
worktree에서 별도 에이전트로 결과를 만들고, 비교 에이전트로 채점하는 가벼운 평가 루프를 짤 수 있다. 직접 만든 스킬을 특정 기준으로 평가·다듬는 데 유용하다.
모델 라우팅
작업별 분류기 에이전트가 사전 조사를 거쳐 Sonnet과 Opus 중 어느 모델로 본 작업을 돌릴지 결정한다. 예를 들어 “auth 모듈이 어떻게 작동하는지 설명하라"는 작업의 최적 모델은 auth 모듈의 파일 수와 코드베이스 형태에 달려 있다. 분류기가 그 정보를 먼저 확인한 뒤 라우팅한다.
쓰지 말아야 할 때
Most traditional coding tasks do not need a panel of 5 reviewers.
워크플로우는 새로운 도구이고, 분명 큰 이득을 주는 경우가 많지만 모든 작업에 필요한 것은 아니다. 토큰을 상당히 더 쓰기 때문에 평범한 코딩 작업이라면 panel of 5 reviewers는 과하다. “정말 이 작업이 더 많은 compute를 필요로 하는가?“를 먼저 묻는다.
사용 팁
- 상세한 프롬프팅 이 가장 큰 차이를 만든다. 위에서 정리된 패턴 용어를 그대로 인용해 지시하면 결과가 좋아진다.
- 큰 작업에만 쓰는 도구가 아니다. “quick workflow"로 가정 하나에 대한 적대적 리뷰만 빠르게 돌릴 수도 있다.
/goal·/loop와 결합. 반복 가능한 워크플로우(트리아주·리서치·검증)는/loop로 정기 실행,/goal로 완료 요건을 굳힌다.- 토큰 예산 명시. “use 10k tokens” 같은 캡을 프롬프트에 넣어 한도를 둔다.
- 저장과 공유. 워크플로우 메뉴에서
s키로 저장한 JS는~/.claude/workflows에 두거나, skill 폴더의 JS 파일로 두고SKILL.MD에서 참조해 배포할 수 있다. 스킬에 들어간 워크플로우는 verbatim 실행보다 템플릿으로 다루도록 프롬프트하는 편이 유연하다.
가장 흥미로운 지점
가장 일반화 가능한 통찰은 정렬 섹션에 짧게 끼어 있는 한 문장이다 — comparative judgment is more reliable than absolute scoring. 이는 LLM 정렬 작업에 국한된 발견이 아니라 사람의 평가에도 오래전부터 관찰된 원칙이다. 워크플로우 토너먼트 패턴의 정당화에 그치지 않고, 평가 일반의 설계 지침으로 옮겨 쓸 수 있다.
두 번째는 트리아주 섹션의 quarantine 이다. 권한 분리로 프롬프트 인젝션의 영향 범위를 차단한다는 발상은 동적 워크플로우가 보안·거버넌스 패턴과 자연스럽게 맞물리는 지점을 보여준다. 정적 워크플로우에서도 가능한 패턴이지만, 워크플로우가 즉석에서 작성되는 환경에서 권한 분리를 기본 패턴으로 명시한다는 점이 의미 있다.
세 번째는 언제 쓰지 말아야 하는가 가 본문 안에 명시되어 있다는 사실 자체다. 새 기능을 출시하는 글이 그 기능의 비효율 영역을 함께 짚는 경우는 드물다. 워크플로우가 토큰을 많이 쓰는 도구임을 인정하고, “panel of 5 reviewers는 과하다"는 반례를 직접 제시한 부분은 도구의 위치를 정직하게 잡으려는 신호로 읽힌다.
출처
발신: Thariq Shihipar(@trq212)와 Sid Bidasaria(@sidbid) — Anthropic 기술 스태프, Claude Code 팀. 본문은 Anthropic 공식 블로그에 동시 게재된 글의 X(트위터) 버전.