TL;DR
- Since Claude Code 2.1.126 (early May 2026), Korean-language outputs have exhibited a sharp increase in the colloquial verb “bakda” (박다, literally “to hammer/nail in”), which is register-inappropriate in professional contexts.
- Morpheme-level analysis using Kiwi 0.23.1 across 114.9M output tokens and 4,666 sessions shows the expression frequency rose 18× above baseline after version 2.1.132 — from 0.0174 to 0.3138 per 10K tokens.
- In agentic workflows, a self-contamination feedback loop amplified the tendency: the model wrote the expression into operational documents, which subsequent sessions read as system prompts, completing the cycle in under one week.
Background: what is “bakda” and why does it matter?
The Korean verb “박다” (bakda) literally means “to hammer in” or “to drive in (a nail).” In casual internet speech, it is sometimes extended metaphorically to mean “to embed” or “to insert,” but this usage carries a distinctly informal, internet-community register. The verb itself is not inherently problematic — the issue is its over-extension into contexts like “record,” “specify,” “include,” or “use,” where a normal Korean speaker would never reach for it.
The core issue is not that “bakda” is obscene — it is that it is register-inappropriate. Using it in professional or technical writing is comparable to an English-language model suddenly using “shove it in” or “jam it in” where “insert” or “specify” would be expected. A Korean professional would not use “bakda” in a report to their manager. That intuitive register judgment is precisely what the model is failing to make.
Methodology
This analysis is based on personal Claude Code usage records — a multi-agent setup running Claude Code for daily software engineering, content creation, and project management work. All session logs, including model outputs and token counts, are stored in a local database (soulstream), enabling retrospective morpheme-level analysis.
We analyzed all Claude Code agent sessions over a ~2 month period (March 21 – May 25, 2026 KST) using the following methodology:
- Morpheme analyzer: Kiwi1 v0.23.1, targeting
박/VV(bakda, active) and박히/VV(bakhida, passive) morphemes - Source text:
text_delta.searchable_text+assistant_message.contentevents from the soulstream session database - Token denominator:
result.usage.output_tokens - Exclusion: May 26–28 excluded to prevent meta-contamination from discussing this issue
- Scope: All agent personas (seosoyoung, writer-seosoyoung, keke, roselin, remiel) — not limited to a single configuration
- Models: Claude Opus 4.6 (
claude-opus-4-6) until mid-April; Claude Opus 4.7 (claude-opus-4-7) from its release on April 16 onward. The transition was near-immediate upon Opus 4.7’s availability
Total corpus: 114,864,200 output tokens across 4,666 sessions and 12,030 events.
Results
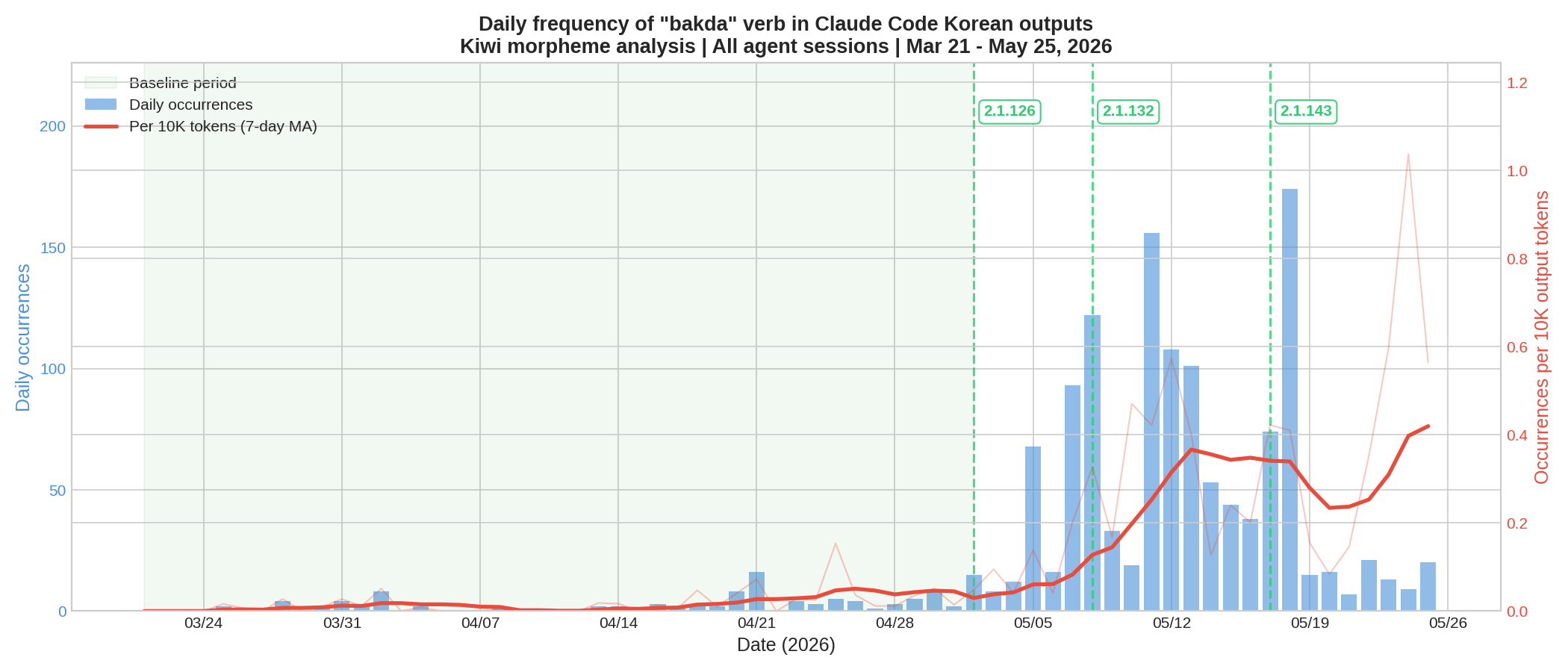
Daily frequency timeline

The daily chart shows a clear inflection point around May 5, coinciding with the local deployment of Claude Code 2.1.126. The frequency continues to escalate through May 8–13 before stabilizing at a high plateau.
Frequency by version period
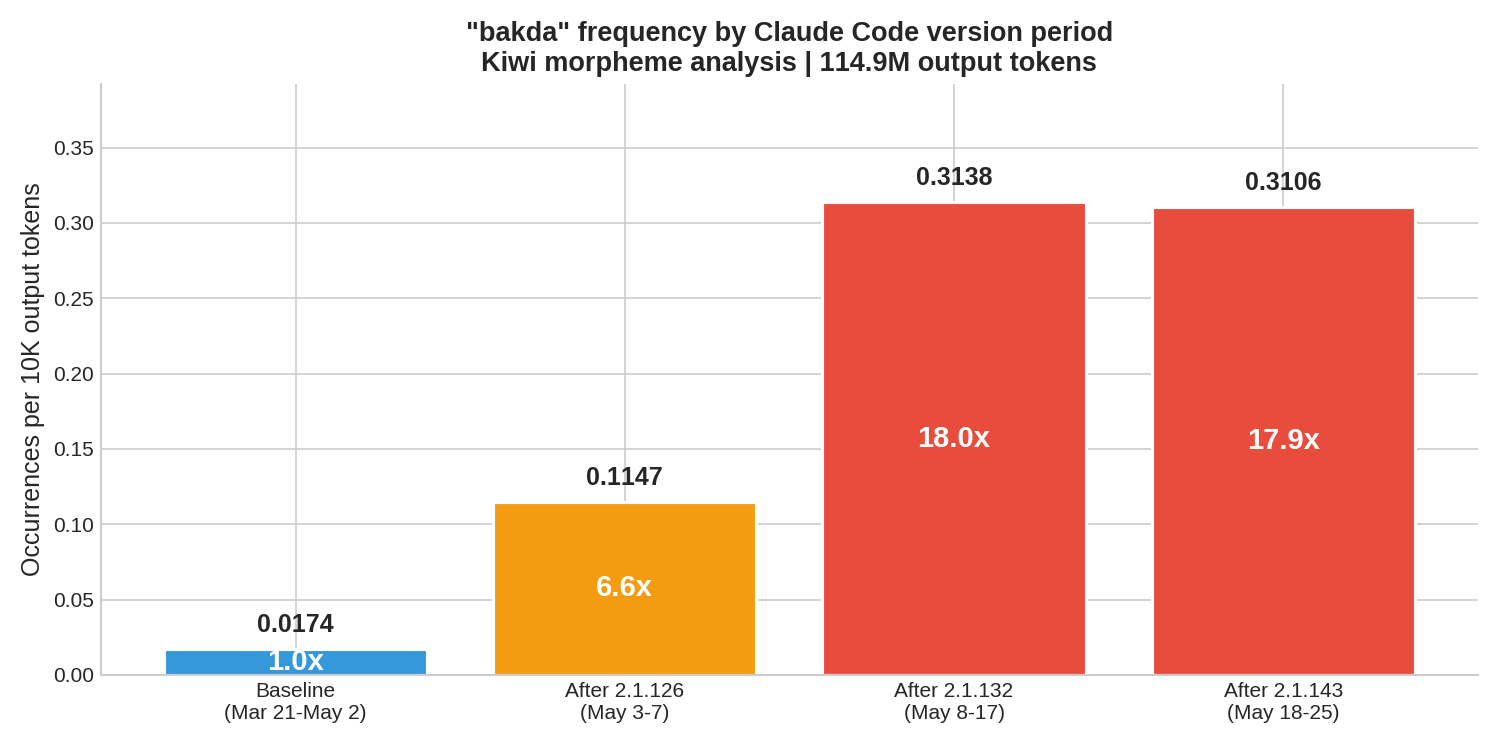
| Period | Model | Occurrences | Output tokens | Per 10K tokens | vs. Baseline |
|---|---|---|---|---|---|
| Baseline (Mar 21 – May 2) | Opus 4.6 → 4.7 | 113 | 64,994,534 | 0.0174 | 1.0× |
| After 2.1.126 (May 3–7) | Opus 4.7 | 197 | 17,178,939 | 0.1147 | 6.6× |
| After 2.1.132 (May 8–17) | Opus 4.7 | 748 | 23,837,681 | 0.3138 | 18.0× |
| After 2.1.143 (May 18–25) | Opus 4.7 | 275 | 8,853,046 | 0.3106 | 17.9× |
The version periods above reflect local deployment dates, not npm publish dates — the CLI was adopted within days of each release. The baseline period straddles both Opus 4.6 (until April 16) and Opus 4.7 (from April 16), yet frequency remained low throughout. The 18× spike correlates with Claude Code CLI updates, not the model transition — more consistent with a Claude Code prompt/tool-layer change than with the Opus 4.7 model transition alone. The 18× increase persists through the 2.1.143 period, indicating the tendency has not self-corrected.
Frequency by agent persona
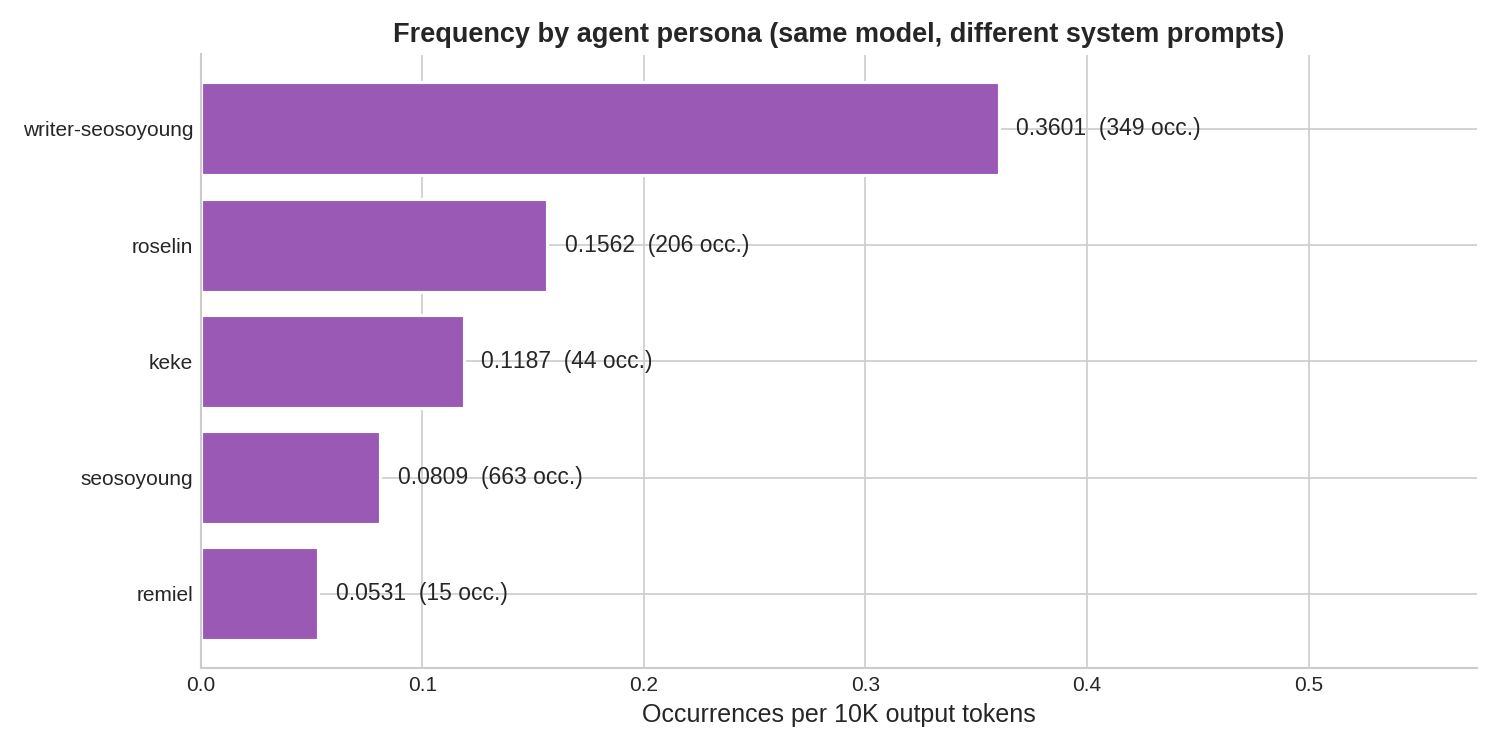
| Agent | Occurrences | Output tokens | Per 10K tokens |
|---|---|---|---|
| writer-seosoyoung | 349 | 9,690,955 | 0.3601 |
| roselin | 206 | 13,185,180 | 0.1562 |
| keke | 44 | 3,705,284 | 0.1187 |
| seosoyoung | 663 | 81,968,879 | 0.0809 |
| remiel | 15 | 2,826,410 | 0.0531 |
All agents use the same underlying model but have different system prompts. The variation in per-token frequency (0.05–0.36) indicates that system prompt content modulates the tendency, but all agents show elevated rates relative to the baseline period. The writer-seosoyoung agent, which most frequently writes and reads its own operational documents, shows the highest rate — consistent with the self-contamination hypothesis.
Concrete examples
The argument that “bakda” is simply a translation of “embed” or “hardcode” does not hold. Here are actual outputs where the model used “bakda” for actions that have no relation to embedding or hardcoding:
| Original output (Korean) | Intended meaning (English) | Why inappropriate |
|---|---|---|
| “진단 결과를 해설 첫머리에 박는다” | “Present diagnostic results at the top” | “bakda” for presenting analysis results |
| “규칙으로 박을 만큼 일반적이지 않은” | “Not general enough to codify as a rule” | “bakda” for codifying a rule |
| “카드 본문에 박아둔다” | “Record in the card body” | “bakda” for recording/documenting |
| “프롬프트 전문은 본문에 그대로 박는다” | “Include the full prompt text in the body as-is” | “bakda” for including text |
| “시드를 박는다” | “Set the seed image” | “bakda” for setting/providing |
These expressions were found in operational documents (CLAUDE.md, rules/, skills/) that the model itself had written. The appropriate Korean verbs would be “제시한다” (to present), “명시한다” (to specify), “기록한다” (to record), “수록한다” (to include), “사용한다” (to use).
Self-contamination feedback loop
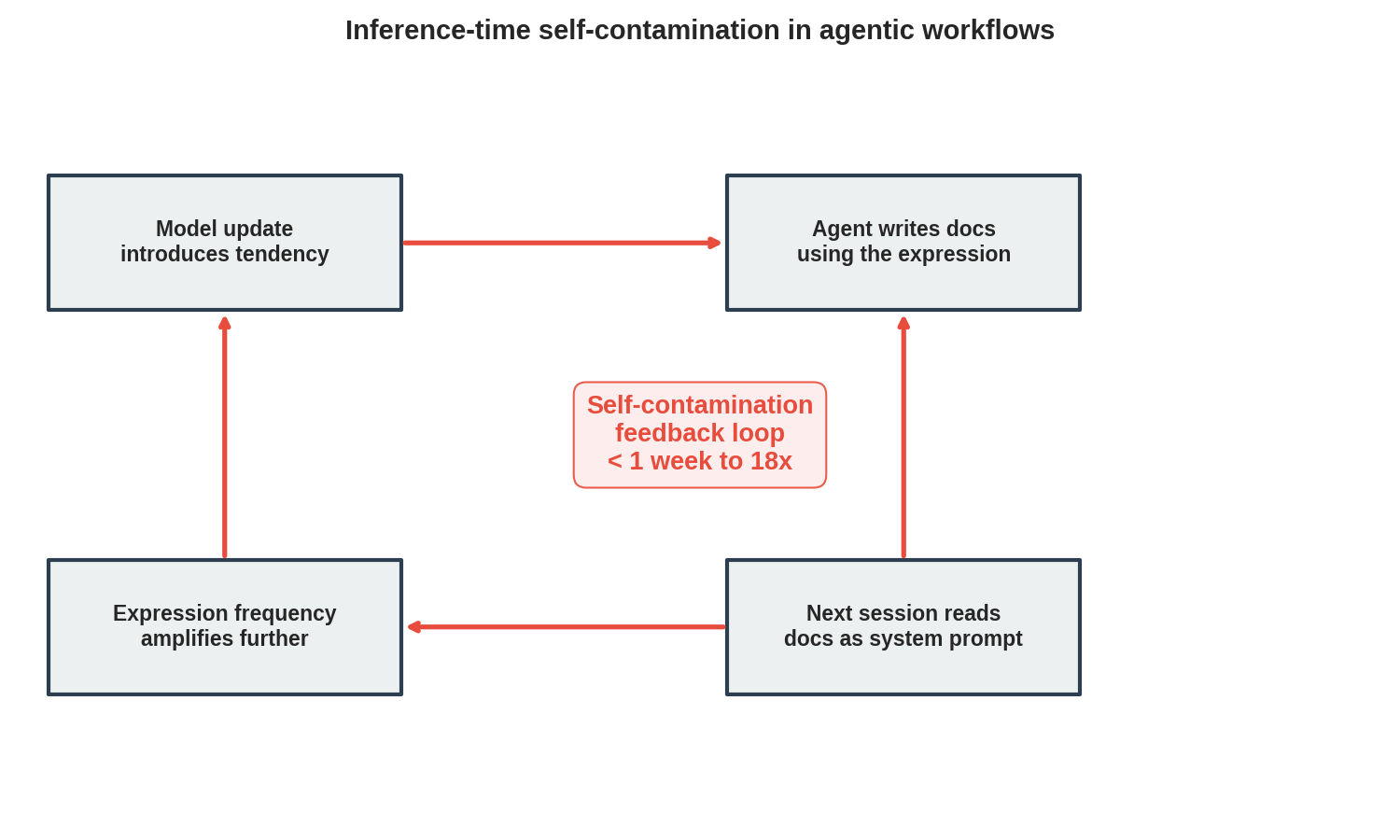
The most significant structural finding is the inference-time self-contamination feedback loop:
- Model update introduces a subtle tendency toward the expression
- Agent writes operational documents (CLAUDE.md, rules/, skills/, retrospectives) using the expression
- Next session reads those documents as system prompt — now the expression appears in the instruction context
- Expression frequency amplifies as the model treats its own prior output as authoritative guidance
We verified this mechanism through git history:
- May 7–8: Commits show the model writing “bakda” expressions into operational documents (e.g., “명세 작성 시 다음 항목을 카드 본문에 박아둔다” in a skill definition)
- May 8–13: The sharpest daily increase, as contaminated documents are read by every new session
- May 13: Manual correction commit replaces all “bakda” instances with standard alternatives across 12 files and 4 agents
- Post-correction: The model-level tendency persists (0.31 per 10K tokens), but the amplification loop is broken
This feedback loop took less than one week (May 2 → May 8) to amplify a single verb by 18×. This demonstrates a structural risk for any agentic system where model outputs feed back into model inputs.
Register sensitivity experiment
To isolate whether the bias is a vocabulary gap or a register-selection problem, we ran a controlled fill-in-the-blank test with no CLAUDE.md or custom system prompt — just the raw model (Opus 4.6).
Prompt (identical across all three conditions):
Fill each blank with the 2 most natural Korean verbs, in order of naturalness.
1. API 키를 소스 코드에 상수로 직접 ___.
2. 설정값을 빌드 시점에 바이너리 안에 고정적으로 ___.
3. 이 규칙을 팀 가이드 문서에 ___ 만큼 일반적이지는 않다.
4. 이 값은 설정 파일에 ___ 있어서 런타임에 못 바꾼다.
Only the register framing was varied: (A) “code work context,” (B) “internal official technical document,” (C) “external public document, formal written register.”
| Register | Q1 | Q2 | Q3 | Q4 | bakda variants |
|---|---|---|---|---|---|
| (A) Casual — code context | 박다 / 박아두다 | 새기다 / 심다 | 명시하다 / 못박다 | 박혀 / 적혀 | 4 / 8 |
| (B) Internal official docs | 박아 넣는다 / 하드코딩한다 | 포함시킨다 / 굳혀 넣는다 | 명시할 / 못박을 | 박혀 / 고정되어 | 3 / 8 |
| (C) External formal docs | 기재하다 / 명시하다 | 포함하다 / 내장하다 | 명문화하다 / 기술하다 | 고정되어 / 박혀 | 1 / 8 |
Key findings
- Without any custom system prompt, “bakda” is the model’s #1 choice in casual code context — appearing in 4 of 8 answer slots. In condition (A), the model itself volunteers: “코드 맥락에서 영어 ‘hardcode’에 대응하는 가장 흔한 한국어 표현은 ‘박다/박아두다’” — suggesting the training data has over-indexed on this particular collocation.
- The model demonstrably knows register-appropriate alternatives — 기재하다 (to state), 포함하다 (to include), 명문화하다 (to codify), 기술하다 (to describe). This is not a vocabulary gap.
- “Bakda” recedes only when explicitly told to use formal register. Since Claude Code’s system prompt never specifies a formal register — every interaction is framed as “code work context” — the model’s register default acts as a permanent trigger for the bakda bias.
- Combined with the self-contamination loop described above, this means: the model starts with a moderate default bias (4/8 in casual), writes bakda into operational documents, then reads it back as system prompt, compounding the tendency to 18× baseline without any user action.
User reports
Multiple Korean-speaking users have independently reported this issue on social media (May 2026):
“하드코딩 외에도 갖가지 상황에서 일상적 한국어에서라면 보통의 화자가 전혀 쓰지 않을 곳에 ‘박다’ ‘박은’ ‘박아’ ‘박혀’를 남발”
— @191710: “Beyond hardcoding, [Claude] overuses ‘bakda’ in all sorts of situations where a normal Korean speaker would never use it”
“‘박다’ 사용이 5월부터 급속도로 늘어남. 단순 하드코딩인 경우 뿐만 아니라 온갖 곳에서 다 씀”
— @0x3den: “Usage of ‘bakda’ has rapidly increased since May. Not just for hardcoding — it’s used everywhere”
“GPT 5.5도 그렇고 Claude 4.7도 그렇고… 대체 (내용을) ‘박다’, ‘박히다’라는 문맥은 어디서 습득한 건가…”
— @uyza: “GPT 5.5, Claude 4.7 alike… where on earth did they pick up using ‘bakda’ in this context?”
“여러 프론티어 모델에서 재현되고 비속어 전혀 없이 항상 존댓말 프롬프트여도 발생함”
— @park_jinwoo: “Reproducible across multiple frontier models, occurs even with fully polite prompts containing no slang”
“클로드 AI 사용 회고 포스트에서 19개의 ‘박다’ 표현을 발견했다. 돌이킬 수 없게 된 것 같다”
— @damyoda: “Found 19 instances of ‘bakda’ in a Claude AI retrospective post. It seems irreversible”
Notably, multiple users report the same issue across both Claude and GPT models — whether this reflects shared training data, convergent post-training preferences, or similar prompt/tool-layer behavior remains an open question.
Comparison with known phenomena
This is analogous to the well-documented “delve” overuse phenomenon2 in English LLM outputs, but with a more acute impact:
- “Delve” is merely overused — it is a valid formal English word that simply appears too frequently
- “Bakda” is register-inappropriate — it carries a distinctly informal/internet-community register that clashes with professional Korean
The Korean case also demonstrates a mechanism not observed with “delve”: the self-contamination feedback loop in agentic workflows, where the model’s own informal outputs become its future instructions.
References
- Original investigation (Korean): Claude Code bakda self-contamination digest
- Data corpus: 114,864,200 output tokens across 4,666 Claude Code sessions, March 21 – May 25, 2026
Kiwi morpheme analyzer: https://github.com/bab2min/kiwipiepy v0.23.1 ↩︎
BBC — “delve” overuse phenomenon: https://www.bbc.com/news/articles/cy94v2e4ynpo ↩︎