3줄 요약
- Stanford의 Mohri·Duchi·Hashimoto가 2026년 5월 발표한 사전학습 데이터 필터링 연구다. Common Crawl 풀과 DCLM-Baseline·RefinedWeb 등 5개 표준 필터를 비교했다.
- 충분한 compute가 주어지면 어떤 필터도 무필터(CC pool)에 진다. 무작위 문자열·셔플된 단어 같은 “junk” 데이터를 +800%까지 주입해도 큰 모델은 오히려 이득을 본다.
- 240T 토큰 DCLM-Pool 전체가 RefinedWeb을 이기는 compute 임계점은 ~1e30 FLOPs로 추정된다 — 현재 프런티어 5e26보다 4 자릿수 위이지만, 2030년경 도달 가능한 영역이다. 데이터 필터링이 Sutton의 “bitter lesson"을 따르고 있다는 증거다.
자료 개요
- 제목: A Bitter Lesson for Data Filtering
- 저자: Christopher Mohri, John Duchi, Tatsunori Hashimoto (Stanford University)
- 발표: arXiv:2605.19407v1 [cs.LG], 2026-05-191
- 코드: https://github.com/chrismohrii/bitter-lesson-data-filtering2
제목은 Rich Sutton의 2019년 에세이 “The Bitter Lesson” — “결국 인간이 설계한 prior가 단순한 compute scaling에 의해 압도된다"는 논점 — 의 데이터 필터링 버전이다.
1. 컴퓨트가 늘면 필터링이 손해다
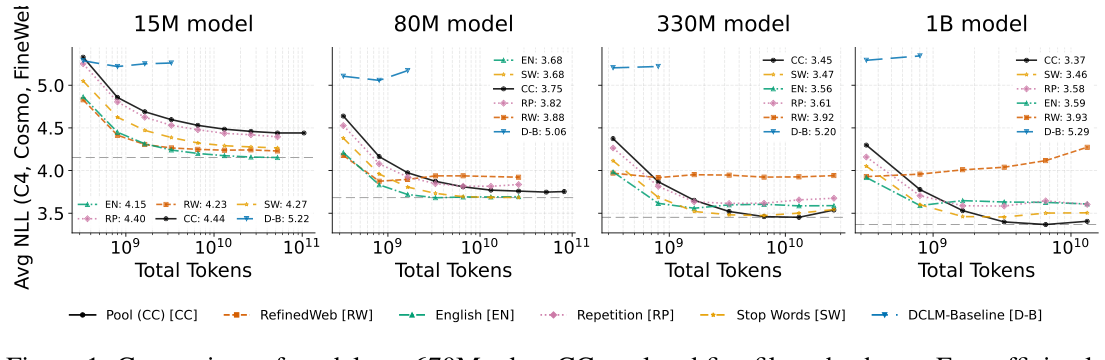
저자들은 5개 필터를 적용한 CC 서브셋과 무필터 CC pool을 비교했다. 작은 모델(15M)에서는 필터링이 우세하지만, 모델이 커질수록 무필터 풀이 우세해진다.
이 모든 필터(컬러)를 이긴다.")
비교한 필터:
| 필터 | CC 대비 잔존 | 특징 |
|---|---|---|
| English | 28.2% | fastText 영어 분류기 + 임계값 |
| Repetition | 45.3% | Gopher 출신, 중복 비율 임계값 |
| Stop Words | 50.4% | 영어 stop word 2회 이상 포함 |
| RefinedWeb | 13% | 위 3개 + 추가 휴리스틱 |
| DCLM-Baseline | 2.1% | RefinedWeb + dedup + 품질 분류기 |
670M 풀 1B 모델 기준 최종 NLL은 CC pool 3.37 vs RefinedWeb 3.93. DCLM-Baseline은 5.29로 가장 나빴다 — 가장 공격적인 필터가 가장 나쁜 결과를 냈다.
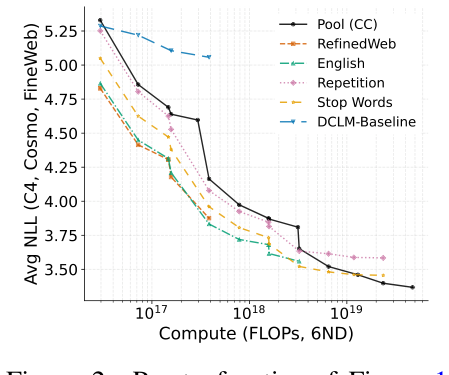
compute-performance Pareto frontier로 보면, compute가 늘수록 무필터가 최악에서 최선으로 전이한다. Repetition 필터는 어느 compute 수준에서도 다른 두 데이터셋보다 좋지 않아 frontier에 한 번도 올라오지 못한다.
2. junk 데이터마저 도움이 된다
여기까지는 “필터가 너무 공격적이었나"로 해석할 수 있다. 그래서 저자들은 반대 방향 실험을 했다 — CC pool에 고의로 저품질 데이터를 주입한다.
두 종류의 junk:
- Random strings: a-z 알파벳에서 3~8자 단어 1만 개를 무작위 추출하여 공백으로 이어붙인 문서
- Shuffled words: CC 문서의 단어 순서를 무작위로 섞은 문서
. 아래 — shuffled words 주입(+100~800%). 330M+ 모델에서는 junk를 섞은 데이터셋이 pool만 사용한 경우보다 *낮은* loss에 도달한다.")
330M 모델에서 shuffled-word를 +400% 주입한 데이터셋은 NLL 3.36으로 pool만 사용한 3.40보다 좋다. +20% random string도 NLL 3.38로 약간 좋다. +800% shuffled (원본 10%만 남기고 셔플) 도 큰 모델에서는 거의 따라잡는다. random 가비지를 1배 추가해도 큰 모델 성능은 거의 떨어지지 않는다.
저자들의 직관: shuffled 문서는 unigram 분포는 그대로 유지하므로 “France"와 “Paris"의 공기(共起) 같은 약한 신호를 여전히 제공한다. 모델이 크면 그 약한 신호도 흡수할 능력이 있다는 것이다.
3. 240T 토큰 풀이 필터를 이기려면 — 1e30 FLOPs
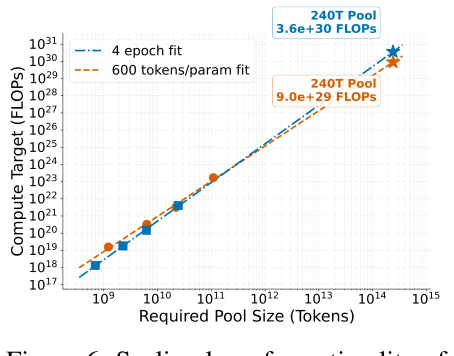
작은 풀(670M~10B)에서 본 효과가 240T 토큰 규모에서도 성립할까? 저자들은 풀 크기 m, 모델 크기 M, 학습 스텝 N의 3차원 공간에서 crossing point(N*) — pool이 RefinedWeb을 처음 이기는 시점 — 를 측정하여 스케일링 법칙을 만든다.

두 가지 방식으로 scaling law를 적합한다:
- 600:1 token-per-parameter 비율 (DeepSeek V4 기반)
- 4 epoch 제약 (Muennighoff et al. 2025 기반)
비교 기준:
- 현재 프런티어 사전학습 compute (xAI 등): ~5e26 FLOPs
- 2030년 예상 (Owen, 2025): 1e29 FLOPs 규모
- 이 논문 예측 임계점: 1e30 FLOPs
1e30은 현재의 2,000배다. 그러나 "~2030 직후"로 표시되는, 결코 황당한 외삽이 아닌 거리다.
4. 그러면 진짜 해로운 데이터는 무엇인가
저자들은 모든 데이터가 무해하다고 주장하지 않는다. 가설은 명확하다 — 언어 모델은 covariate shift(입력 분포 변화)에는 강건하지만, 조건부 분포가 잘못된 데이터에는 취약하다. 예시: “프랑스의 수도는 코펜하겐이다"가 충분히 반복되면 모델은 잘못 학습한다.
이런 종류의 데이터가 Common Crawl에 얼마나 있나? 저자들은 MMLU 카테고리(world_religions·astronomy·college_biology·medical_genetics)의 키워드와 매칭되는 CC 문서를 추출하여 GPT-5-mini로 분류했다.
| MMLU 카테고리 | Support | Refute | Related | Unrelated |
|---|---|---|---|---|
| world_religions | 5.89 | 0.00 | 13.22 | 7.50 |
| astronomy | 2.03 | 0.14 | 10.14 | 17.41 |
| college_biology | 2.67 | 0.17 | 11.07 | 13.40 |
| medical_genetics | 2.80 | 0.23 | 14.30 | 11.23 |
지지 문서 수가 반박 문서 수보다 평균 한 자릿수 이상 많다. 즉 적극적으로 해로운 비사실 콘텐츠는 CC에서 매우 드물다는 것이다.
또 하나의 미세한 패턴 — shuffled 데이터로 훈련한 모델은 문서 첫 토큰 예측에서는 pool보다 좋지 않다. shuffling이 시작 분포를 바꿔놓기 때문이다. 다만 대부분의 활용은 첫 토큰만 보지 않으므로 실용적 영향은 작다.
5. 왜 그런가 — 저랭크 행렬 분해 직관
§7에서 저자들은 가장 단순한 신경망 — 1-hidden-layer 선형 모델, 즉 저랭크 행렬 분해 — 으로 직관을 제시한다.
모델 rank r가 task 수 k 이상이면 무관한 task(주입된 junk)는 직교 부분공간으로 분리되어 손실에 기여하지 않는다. r < k면 task들이 간섭하여 성능이 떨어진다.
대형 transformer가 junk 데이터를 그냥 흘려보낼 수 있는 별도 회로를 충분한 capacity로 갖춘다는 가설과 일치한다. 작은 모델에는 그 여유가 없어 결국 noise에 잠식된다.
atom 트리에서의 연관 — Simula의 정반대 결론과 어떻게 화해할 것인가
이 논문의 결론은 atom에 누적된 다른 카드들과 흥미로운 긴장을 만든다.
- Chinchilla 20:1 비율은 추론 효율 때문에 이탈 — Llama 3가 37:1, MoE는 8:1로 분기 중이며, 본 논문이 사용한 600:1은 이 흐름의 극단이다. “작은 모델·많은 토큰” 전략 위에서 어떤 토큰이냐를 다시 묻는 게 본 연구의 위치다.
- Simula — 데이터 스케일링은 양이 아닌 속성의 함수 — Simula는 합성 데이터의 다양성·복잡도·품질이 양보다 중요하다고 주장한다. 본 논문은 자연 데이터 필터링에서 “양이 더 중요하다"고 답하는 것처럼 보인다. 그러나 자세히 보면 두 주장은 층이 다르다 — Simula는 합성 데이터를 어떻게 만들 것인가에 대한 처방이고, 본 논문은 자연 데이터를 얼마나 솎아낼 것인가에 대한 진단이다. 합성 데이터는 분포 꼬리를 인위적으로 좁히기 쉽고(아래 카드 참조), 자연 데이터는 꼬리가 풍부하므로 무필터가 안전하다.
- 합성 데이터는 분포 꼬리를 소실시킨다 — Shumailov 등의 Nature 논문. 합성 데이터로 반복 재훈련하면 저빈도·고정보량 꼬리가 사라진다. 본 논문이 자연 데이터에서 “low-quality 문서"라 불리는 꼬리를 보존해야 한다고 말하는 것과 짝을 이룬다.
- gibberish 62% 데이터로도 +5.7pp 향상 (SSD) — 사후학습 단계에서도 같은 패턴이 보고됐다. 데이터 품질 자체보다 분포 재형성이 핵심이라는 결론과 본 논문의 “shuffled-word도 도움이 된다"는 결과는 같은 가족이다.
가장 흥미로운 지점
내가 가장 흥미롭게 본 부분은 §6의 “covariate shift는 괜찮지만 조건부 분포 오류는 해롭다"는 진단이다. 이것은 “더러운 데이터를 더 넣어도 된다"는 결론을 무한정 일반화하지 않게 막는 안전 장치이다. “프랑스의 수도는 코펜하겐"이 반복되면 모델은 잘못 학습한다. 다행히 CC에는 그런 비사실이 매우 드물다. 이 미세한 경계가 향후 합성 데이터 시대에 어떻게 옮겨갈지 — AI가 만든 비사실 콘텐츠가 어느 비율에서 임계점을 넘는지 — 가 후속 연구의 자리일 것이다.
그리고 Repetition 필터가 어느 compute 수준에서도 frontier에 한 번도 올라오지 못한다는 §3의 작은 발견. Gopher 시대부터 “반복은 무정보 콘텐츠와 연관된다"는 직관으로 깔려 있던 필터가 — 어떤 시점에서 보아도 — 가장 비효율적이라는 결과는 휴리스틱 필터링의 한계를 가장 짧게 요약한다.
출처
- 저자: Christopher Mohri, John Duchi, Tatsunori Hashimoto (Stanford University)
- 발표: arXiv:2605.19407v1 [cs.LG], 2026-05-19
- 라이선스: CC BY 4.0