3줄 요약
- AttentionViz는 트랜스포머의 query·key 벡터를 함께 한 평면에 사영(joint embedding)해, 단일 문장의 bipartite 그래프 시각화로는 보이지 않던 다수 입력에 걸친 전역 어텐션 패턴을 헤드 단위로 비교하게 만든 인터랙티브 도구다. Harvard·Google Research(Catherine Yeh 외 5인) 작품이며 IEEE TVCG 2023에 게재되었다.12
- 핵심 기법은 query 벡터에 $1/\sqrt{d}$ 정규화를 거쳐 t-SNE/UMAP/PCA로 query·key를 같은 공간에 사영하는 것. 거리와 어텐션 가중치 사이에 강한 음의 상관(BERT 평균 -0.938, GPT-2 -0.792, ViT -0.873 ~ -0.884)이 발생하여 “가까운 점 = 강한 어텐션"이라는 직관이 성립한다.
- 도구는 Matrix View(전체 144개 헤드 일람) → Single View(헤드 줌인) → Sentence/Image View(단일 입력 상세)의 3단 줌 구조다. 이로 BERT의 나선형 위치 패턴·induction head 후보, ViT의 hue/brightness 특화 헤드, GPT-2의 query-key norm 격차와 “첫 토큰에 몰리는” 이상 어텐션 등 기존 단일-입력 도구에서 드러나지 않던 현상이 보고된다.
자료의 정체
이 다이제스트는 세 갈래의 자료를 묶어 정리한다.
- 도큐 페이지 — https://catherinesyeh.github.io/attn-docs/ (시각·UX 설명, 데모 영상 8편)3
- 페이퍼 — Yeh et al., AttentionViz: A Global View of Transformer Attention, IEEE TVCG 2023. arXiv:2305.03210 (11페이지)4
- GitHub 리포 — https://github.com/catherinesyeh/attention-viz (Vue·TypeScript 프런트엔드 + Python/Flask 백엔드, BERT·GPT-2·ViT-16/32 사전 처리 데이터 동봉)5
저자: Catherine Yeh, Yida Chen, Aoyu Wu, Cynthia Chen, Fernanda Viégas, Martin Wattenberg. 소속: Harvard University (전원), Google Research (Viégas·Wattenberg 겸직). 실 데모: http://attentionviz.com/

풀고자 한 문제
기존 어텐션 시각화의 대부분(BertViz, exBERT, attention rollout 등)은 단일 입력 시퀀스의 어텐션을 bipartite 그래프 또는 heatmap으로 그린다. 분석가가 “이 헤드가 무슨 일을 하는가"를 알려면 문장 하나씩, 헤드 하나씩, 144회 반복해 들여다봐야 한다.
페이퍼는 5명의 ML 인터프리터빌리티 연구자(E1~E5) 인터뷰에서 다음의 공통 욕구를 끌어냈다.
- G1. 셀프 어텐션이 모델 행동에 어떻게 기여하는지 전체 그림으로 이해하고 싶다.
- G2. 헤드끼리 비교하고 싶다. “이 둘이 비슷하게 동작하면 한쪽을 제거해도 되지 않을까"라는 가설을 빠르게 검정하려는 의도다.
- G3. 모델의 이상 동작을 찾고 싶다. 결과가 맞아도 잘못된 곳을 보고 있을 수 있다는 우려.
이로부터 4개 설계 과제(T1 헤드 대규모 시각화, T2 query-key 상호작용 탐색, T3 다중 레벨 어텐션 탐사, T4 모델·데이터 입력 커스터마이즈)가 도출되었다.
핵심 기법 — query·key joint embedding
각 어텐션 헤드에서 어텐션은 query·key 벡터의 스케일드 내적으로 계산된다.
$$f(x, y) = \frac{1}{\sqrt{d}}\langle W_Q x,\ W_K y\rangle$$$$\mathrm{attn}(x_i, x_j) = \mathrm{softmax}_j\bigl(f(x_i, x_1), \dots, f(x_i, x_n)\bigr)$$저자들이 노리는 직관은 단순하다 — query와 key 벡터의 norm이 동일하다면 내적이 클수록 두 벡터의 거리는 가까워진다. 따라서 거리가 어텐션의 대리 지표가 된다.
문제는 실제로는 norm이 들쭉날쭉하다는 점이다. 페이퍼는 두 “공짜 매개변수"를 활용해 거리-어텐션 관계를 강하게 만든다.
- Key translation. softmax는 translation-invariant다. 모든 key 벡터에 동일 상수 $a$를 더해도 어텐션은 변하지 않는다. 이 자유도로 query·key의 중심점을 정렬해 두 분포를 겹친다.
- Query scaling. 모든 query에 상수 $c$, 모든 key에 $c^{-1}$을 곱해도 어텐션은 불변이다. 두 분포의 분산을 정합시켜 cosine distance와 dot product 간 weighted correlation을 최대화하는 $c$를 고른다.
두 정규화 후 동일 평면에 query(녹색)와 key(분홍색)를 t-SNE/UMAP/PCA로 사영한다(차원은 BERT·GPT-2·ViT 모두 $d=64$).
검증 결과 cosine distance와 dot product 사이 Spearman 상관은:
| 모델 | 데이터셋 | 평균 상관 |
|---|---|---|
| BERT | Wiki-Auto | -0.938 |
| GPT-2 | Wiki-Auto | -0.792 |
| ViT-32 | COCO | -0.873 |
| ViT-16 | COCO | -0.884 |
거리가 어텐션의 충분히 정확한 대리 지표라는 뜻이다. BERT layer 4 head 11의 예시는 단일 헤드 안에서 거리-내적 상관이 -0.983까지 올라간다.
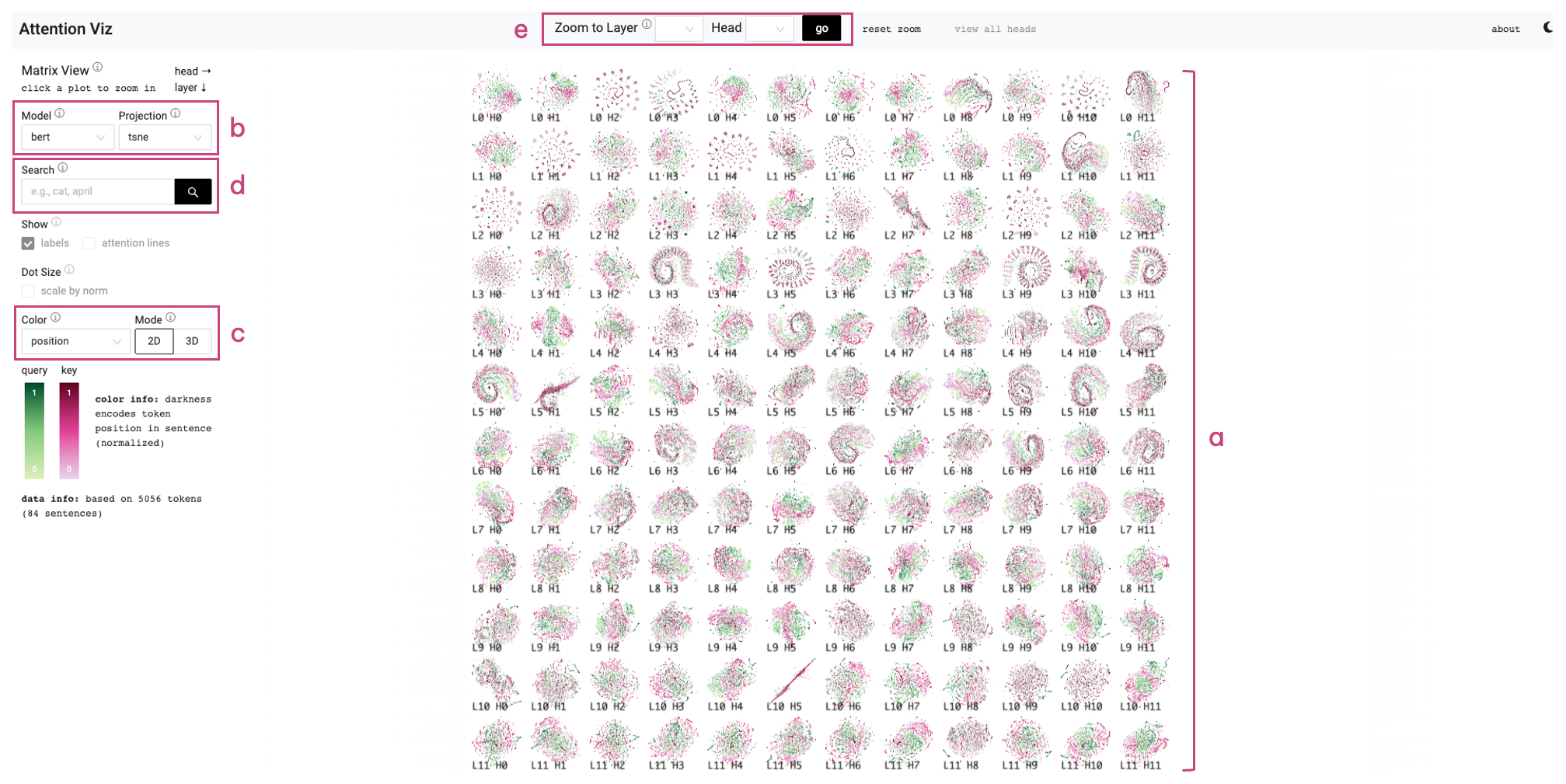
도구 — 3단 줌 구조

Matrix View (T1, T3)
행은 모델 레이어(위 → 아래), 열은 헤드 인덱스. 각 셀이 한 헤드의 joint query-key 사영도다. 12×12=144개 헤드를 한 화면에서 시각적으로 비교할 수 있다. 모델·사영법(t-SNE/UMAP/PCA)·색상 인코딩(position, type, frequency, norm 등)·2D/3D 전환이 드롭다운으로 가능하다.
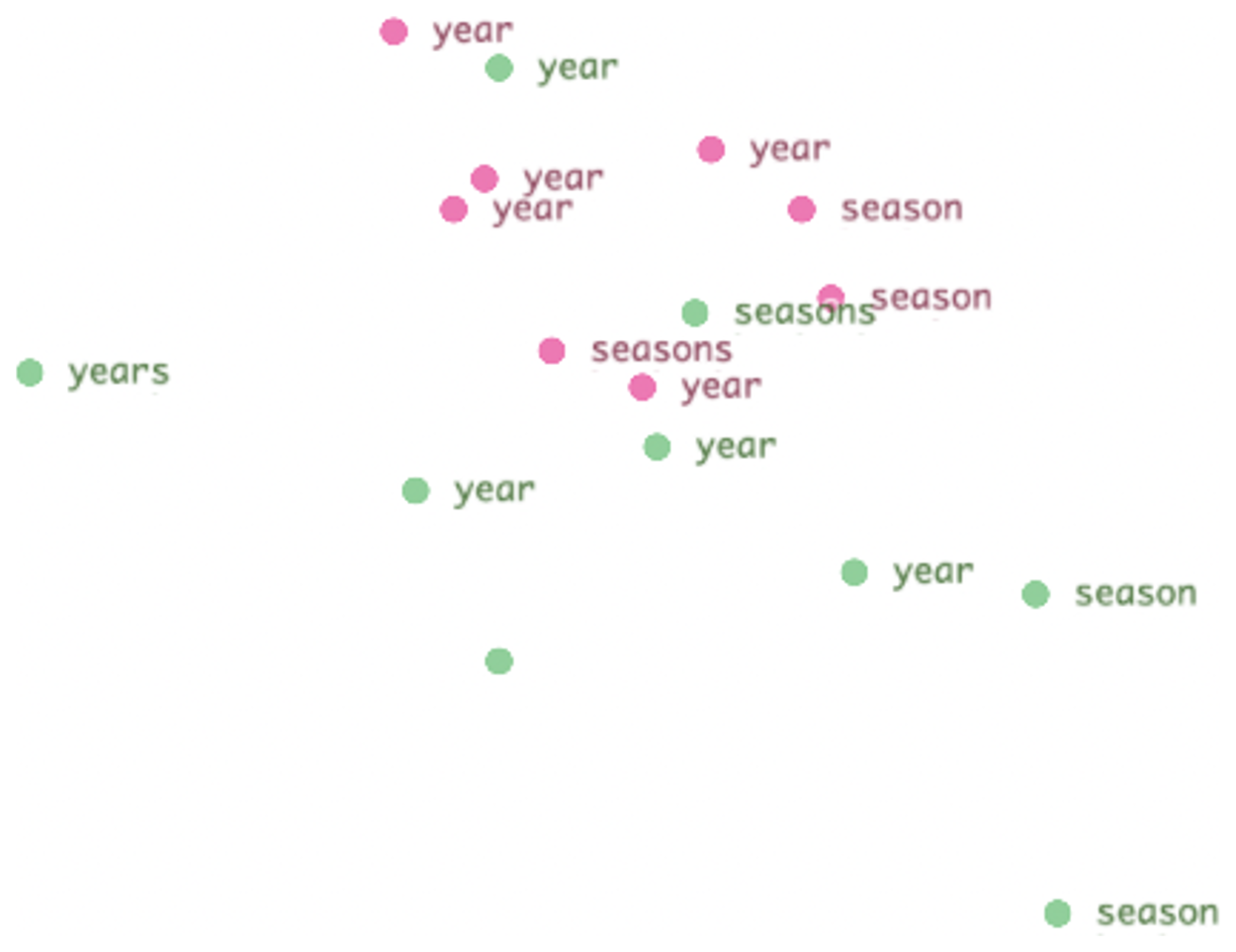
전역 검색 기능은 같은 토큰(언어) 또는 같은 객체 클래스(비전)를 모든 헤드에서 동시에 하이라이트한다. “어느 헤드가 ‘april’을 의미적으로 묶고, 어느 헤드는 위치적으로 흩는가"가 단번에 드러난다.
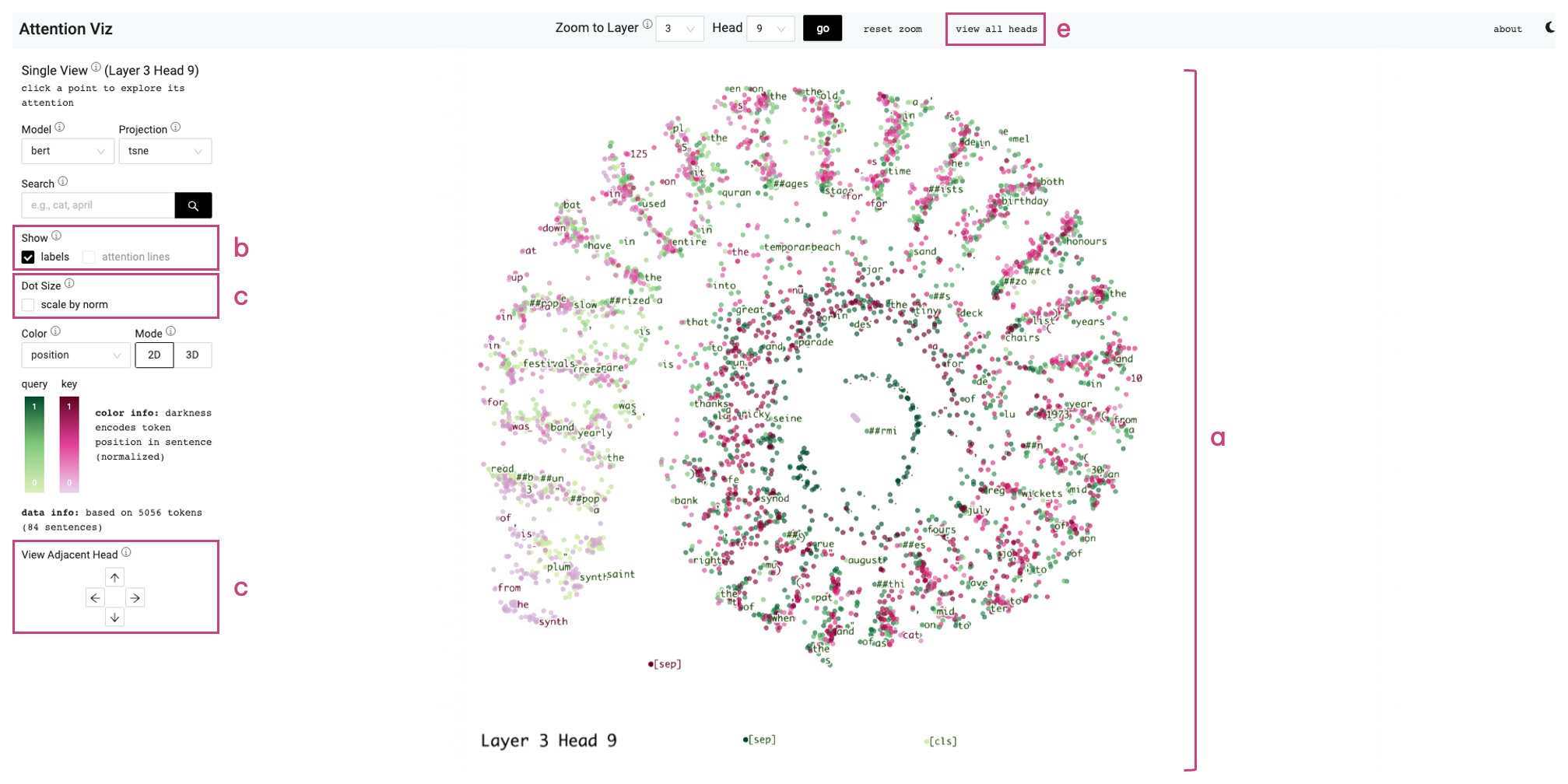
Single View (T2, T3)
Matrix View의 셀을 클릭하면 그 헤드의 사영도가 확대된다. 토큰 라벨, 어텐션 라인(상위 2개 connection), 토큰 norm으로 점 크기 조절, 인접 헤드로의 방향 키 이동 등이 추가된다.
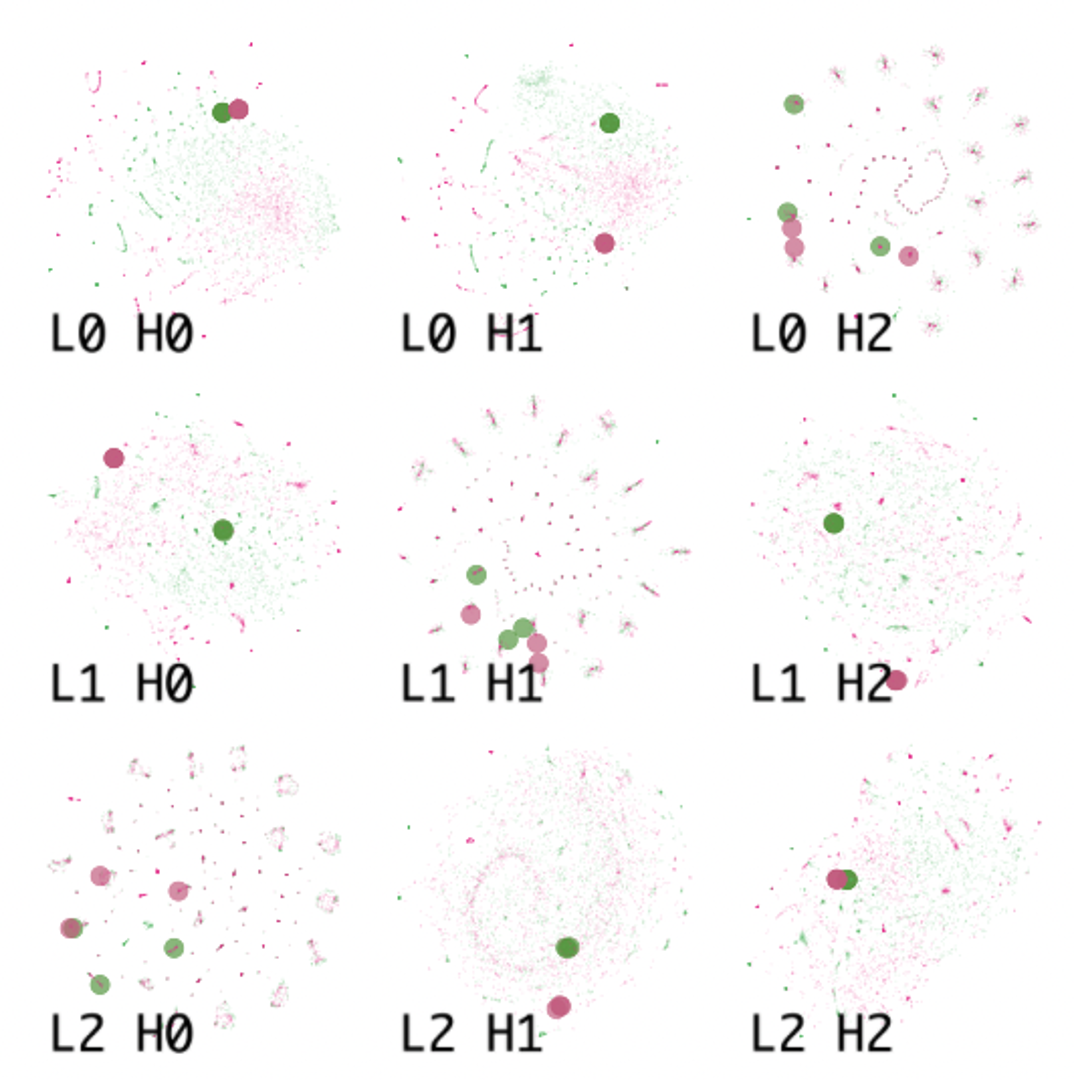
토큰 라벨을 켜면 의미 클러스터가 그대로 드러난다. 아래 BERT 헤드는 “broadcast(방송)“라는 의미 묶음과 “stanley/finals(스포츠)” 묶음이 query-key 간에 의미적으로 연결된 모습이다.
Sentence View (T2, T3)
Single View의 한 점을 클릭하면 우측 사이드바에 BertViz 풍의 bipartite 시각화가 열린다. 클릭된 토큰의 어텐션 라인이 메인 사영도에도 동기화된다. [cls]/[sep] 같은 특수 토큰 필터, 헤드 평균 aggregate 뷰가 추가 기능이다.
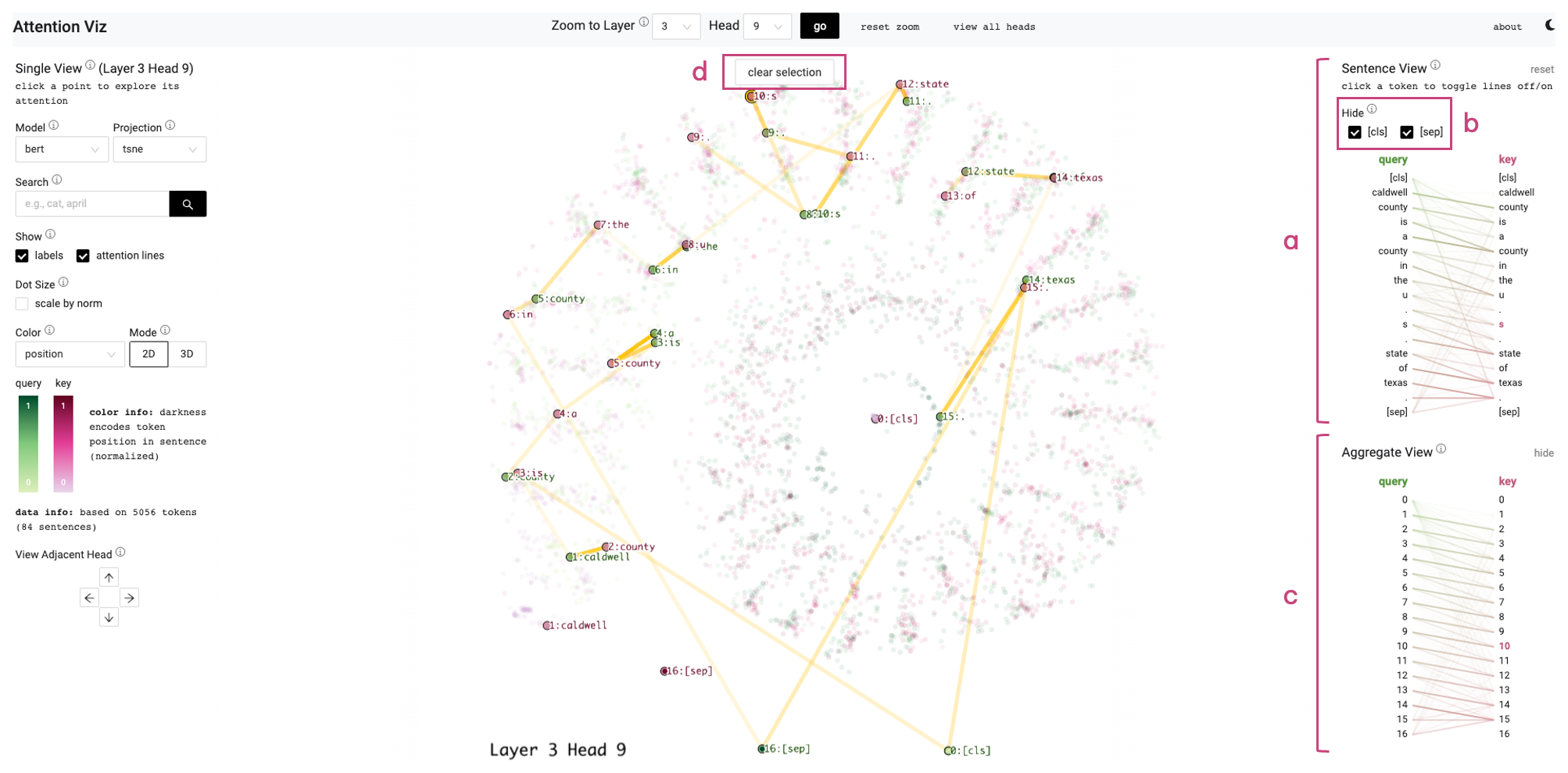
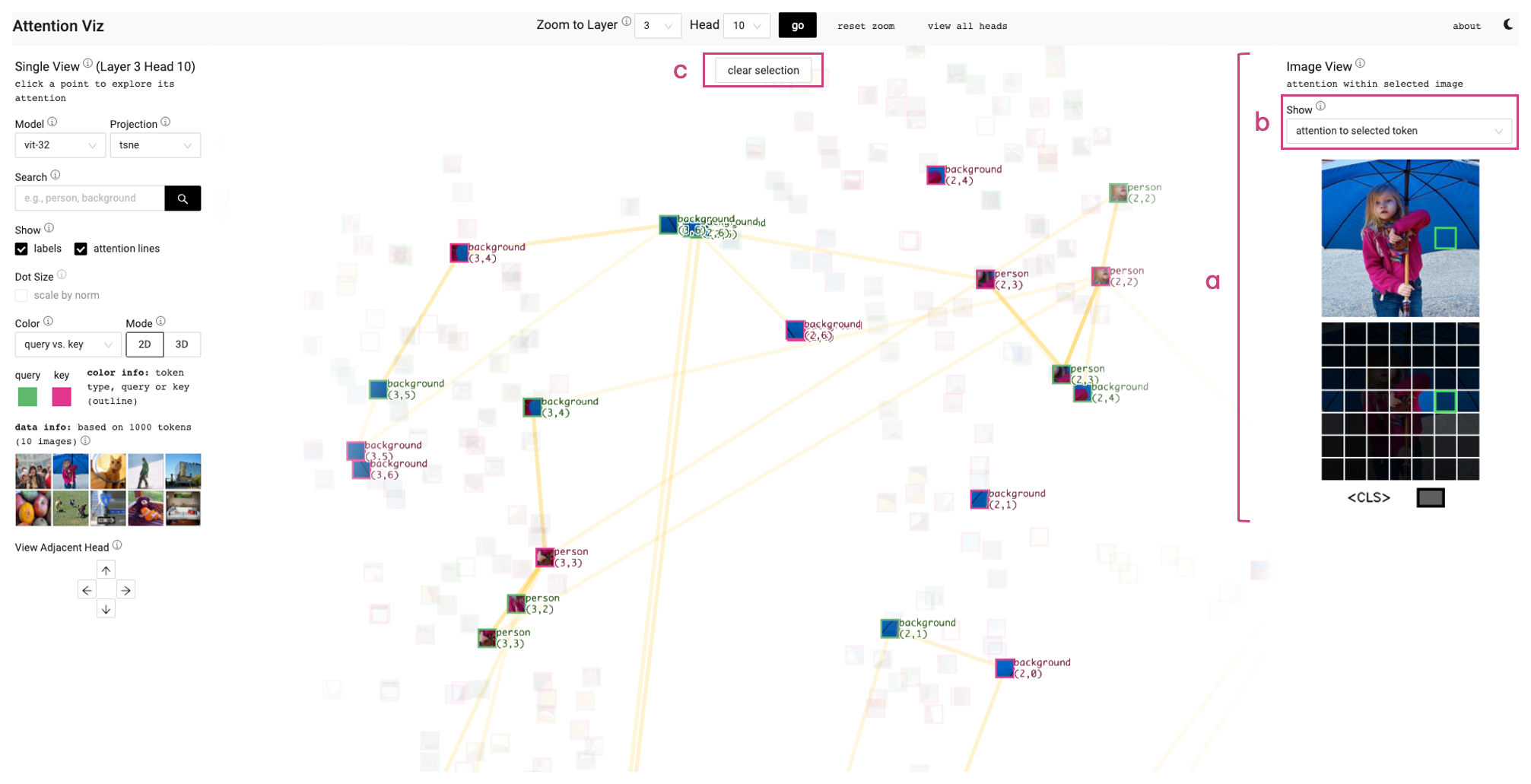
Image View (T2, T3)
ViT의 경우 같은 자리에 이미지가 들어온다. 패치 클릭 → 어텐션 heatmap, “각 토큰의 최강 어텐션 화살표”(simplified bipartite), “0.1 이상 모든 강한 연결”(comprehensive view) 세 옵션을 제공한다. 자기 자신에 대한 어텐션은 원형 화살표, [cls] 토큰 어텐션은 사각형 아이콘으로 표시된다.

발견된 사례
페이퍼 §7과 도큐의 “Example findings” 섹션에서 보고된 발견을 정리한다.
BERT — 위치의 시각적 흔적
BERT layer 3에는 나선형(spiral) 사영도가 줄지어 등장한다. 위치 인덱스로 색을 입히면 나선 바깥에서 안쪽으로 갈수록 토큰 위치가 증가한다. Sentence View는 이 헤드가 “다음 토큰(next-token)에 주의를 보내는” 패턴임을 확인해 준다.
비슷하게 layer 2에는 작은 덩어리(clump) 패턴이 있다. 위치 모듈로 5로 색을 입히면 이산적 위치 패턴이 드러난다. “나선"과 “덩어리"의 차이는 “한 칸 떨어진 토큰에만 주의하는가, 여러 오프셋에 주의하는가"의 차이로 해석된다.
ViT — hue·brightness·angle 특화 헤드
ViT-32에 합성 컬러·밝기 그라디언트 이미지를 입력해 Matrix View를 훑으면, 색이 없는 헤드(layer 0 head 10, 밝기로 정렬)와 컬러풀한 헤드(layer 1 head 11, hue로 정렬)가 두드러진다. 이미지 내 패치의 원위치와 무관하게 같은 색·밝기 패치가 joint embedding에서 한자리에 모인다. Image View의 attention heatmap이 이를 확인해 준다 — 토큰이 자기와 동일 색/밝기 토큰에 가장 큰 어텐션을 보낸다.
주파수·각도가 다른 사인파 패턴 이미지로 같은 실험을 반복하면, x축은 공간 패턴 주파수로, y축은 각도로 토큰을 정렬하는 헤드도 발견된다(ViT-32, Fig. 9). CNN의 정사각 필터와 달리 트랜스포머는 “행 단위, 열 단위” 처리에 가까운 어텐션 흐름을 보인다.
BERT — induction head 가능성
Induction head는 GPT-2 같은 단방향 트랜스포머에서 in-context learning의 메커니즘으로 알려져 있다(Anthropic, 2022). 페이퍼는 양방향 BERT에서도 induction-like 동작을 발견한다.6
- Layer 8 head 2 — 표준 induction. 토큰 A(예:
-)가 이전 등장에서 자기 앞에 있던 토큰 B(예:8,10)에 주의를 보낸다. BERT는 양방향이므로 양쪽 방향 모두 가능하다. - Layer 9 head 9 — “역방향” induction. 토큰 A가 이전 등장에서 자기 뒤에 있던 토큰 B에 주의를 보낸다.
저자들은 “추가 검증이 필요"라고 못박지만, 양방향 트랜스포머에서도 induction-like 회로가 존재할 가능성을 시각적으로 제기한다.
GPT-2 — norm 격차와 “첫 토큰에 몰리는” 이상
Matrix View에서 GPT-2 초기 레이어는 query 클러스터가 작고 가볍게 떠 있고 key 클러스터가 크고 짙게 깔리는 비대칭이 자주 보인다. norm 색상 인코딩으로 확인하면 query·key norm 간 차이가 평균 -4.59까지 벌어진다(BERT는 0.41에 그친다). 5명의 인터뷰 전문가 누구도 이 현상의 이유를 설명하지 못했다 — “query와 key가 왜 그렇게 다른 norm을 가져야 하는지 모르겠다” (E6).
이 관찰 직후 발표된 Bondarenko et al., 2023은 GPT-2의 out-of-control한 query/key norm이 훈련 불안정성의 원인이라고 보고했다. 페이퍼는 이를 들어 자신들의 §5.1.1 스케일링 정규화가 우연이 아닌 필연이었다고 주장한다.
또 하나, GPT-2의 후기 레이어에서 어텐션이 대부분 첫 토큰에 몰린다. 어텐션의 “null position"으로 첫 토큰이 쓰인다는 일부 추측이 있지만 페이퍼는 이 현상의 광범위함을 시각적으로 정량화한다 — 5명의 전문가 모두 이 현상에 놀랐다고 보고한다.
ViT-32 — “자기 자신을 본다(look at self)” 헤드
ViT-32 초기 레이어에서 사영도가 흩어진 군집으로 나오는 헤드들이 있다(Fig. 13a). 줌 인하면 동일 토큰의 query와 key가 거의 겹쳐 있다 — 즉 이 헤드는 모든 어텐션을 자기 자신에 보낸다. 학습된 query·key projection layer의 파라미터 상관을 직접 측정하니 선형 상관 0.94로 거의 동일한 사영을 학습했다(Fig. 13d). 모델 프루닝 후보가 될 수 있다는 의미다.
시스템 구현
- 백엔드: Python/Flask. Hugging Face Transformers + PyTorch. 사전학습된 BERT·GPT-2(small)·ViT-16/32를 Google·OpenAI 가중치로 로드.
- 프런트엔드: Vue + TypeScript. Deck.gl로 사영도 렌더링.
- 데이터 전처리: BERT/GPT-2는 200문장(~10k 토큰), ViT는 10장(1000 토큰, ViT-32) 또는 4장(1576 토큰, ViT-16) 단위.
- 사전 처리 시간: BERT/GPT-2 데이터셋당 ~3시간 (NVIDIA A100), ViT-32는 ~30분.
- 데이터 로딩: NLP 데이터셋 ~6초, ViT-16 ~10초.
리포는 그대로 클론·pip install -r requirements.txt·npm run serve 9단계로 로컬 실행이 가능하다. 데이터 폴더는 Google Drive 링크로 별도 다운로드.
전문가 평가 — 7명의 인터뷰
설계 단계의 5명(E1~E5) 외에 평가 단계에서 2명(E6 interpretability researcher, E7 vision science Ph.D.)이 추가되었다.
Matrix View의 가치. 다수의 전문가가 “여러 임베딩을 한 번에 보고 비교할 수 있다는 것 자체가 새로운 능력"이라고 평가했다. “하이퍼파라미터 튜닝 없이 빠르게 비교하기에 좋다”(E6), “작은 규모의 시각화는 직접 만들 수 있지만, 대규모에서 비교는 훨씬 어렵다”(E7).
Joint query-key embedding의 응용. E3·E7은 미학습·손상된 트랜스포머의 어텐션 변화 추적, E2는 fine-tuning 과정의 어텐션 흐름 추적, E3는 인과 추적(causal tracing) 결합 등을 제안했다.
투영의 신뢰 문제. E3는 t-SNE/UMAP의 왜곡을 우려했다 — “내가 보는 것을 어떻게 신뢰하는가?” 시각적 가설을 반드시 검증 가능한 메커니즘과 묶어야 한다는 지적이다. 페이퍼는 이를 한계로 명시한다.
유연성-사용성 트레이드오프. E2는 “매우 사용 가능하고 커스터마이즈 가능"이라 평했지만, E6은 *“기능과 헤드를 다 보여주는 건 압도적일 수 있다”*고 우려했다. E7은 feature visualization처럼 더 추상화된 요약을 원했다.
한계와 후속 방향
페이퍼가 직접 적시한 한계.
- 데이터 사전 계산 시간·메모리 — 큰 데이터셋에서 새 입력을 즉시 추가하기 어렵다.
- 사영 왜곡 신뢰 — t-SNE/UMAP은 의미를 왜곡할 수 있다. 시각적 발견은 별도의 검증 회로(인과 추적, 어블레이션)와 묶일 때 의미를 가진다.
- Value 벡터 미반영 — 현재는 query·key만 다룬다. 어텐션은 value도 함께 가중하므로 value 시각화가 후속 작업으로 남는다.
- 다른 어텐션 메커니즘 — cross-attention, encoder-decoder attention 등은 본 기법의 직접 적용 대상이 아니다(수정 필요).
- 일반화 — semantic·syntactic 패턴 외에 part-of-speech 등 NLP 메타데이터를 더해 분석 차원을 넓힐 여지가 있다.
가장 흥미로운 지점
내가 가장 인상 깊게 본 것은 *“scaling은 unchanged하지만 cosine distance에는 nontrivial effect”*라는 §5.1.1의 단서다. 두 “공짜 매개변수”(translation, scaling)는 어텐션 값을 한 비트도 바꾸지 않는다. 그런데도 그 자유도를 어떻게 쓰느냐에 따라 시각화의 가독성이 극적으로 달라진다.
이는 시각화 도구의 본질을 잘 보여준다 — 시각화는 데이터를 바꾸지 않는다. 단지 데이터의 어느 자유도를 어디에 사용할지를 고르는 작업이다. 그 선택이 잘 들어맞으면 BERT의 나선이 보이고, GPT-2의 norm 격차가 보이고, ViT의 hue 헤드가 보인다. 잘 들어맞지 않으면 144개 헤드가 모두 그저 “분홍·녹색 점 무더기"로 남는다.
또 한 가지 — 페이퍼가 “induction head를 BERT에서 발견했다"고 주장하지 않고 “induction-like 패턴을 시각적으로 찾았으니 검증해 보라“고 제기한 점도 인상적이다. 시각화 도구의 본분이 결론 도출이 아니라 가설 생성임을 분명히 한다. E3의 *“내가 보는 것을 어떻게 신뢰하는가”*라는 질문에 대한 저자들의 솔직한 답이기도 하다.
출처
본문에 인용한 이미지는 도큐 페이지의 PNG를 다운로드해 사용했다. 저자: Catherine Yeh et al., Harvard University / Google Research.
후속 검증: Bondarenko, Yelysei et al. Quantizable Transformers: Removing Outliers by Helping Attention Heads Do Nothing, 2023 — AttentionViz가 시각적으로 짚은 GPT-2의 query/key norm 격차가 훈련 불안정성의 원인임을 정량화. ↩︎
Yeh, Catherine et al. AttentionViz: A Global View of Transformer Attention. IEEE Transactions on Visualization and Computer Graphics (TVCG), 2023. DOI: 10.1109/TVCG.2023.3327163. arXiv: 2305.03210v2 (2023-08-09). ↩︎
GitHub 리포: https://github.com/catherinesyeh/attention-viz ↩︎
관련 자료: Anthropic, In-context Learning and Induction Heads (2022). ↩︎