3줄 요약
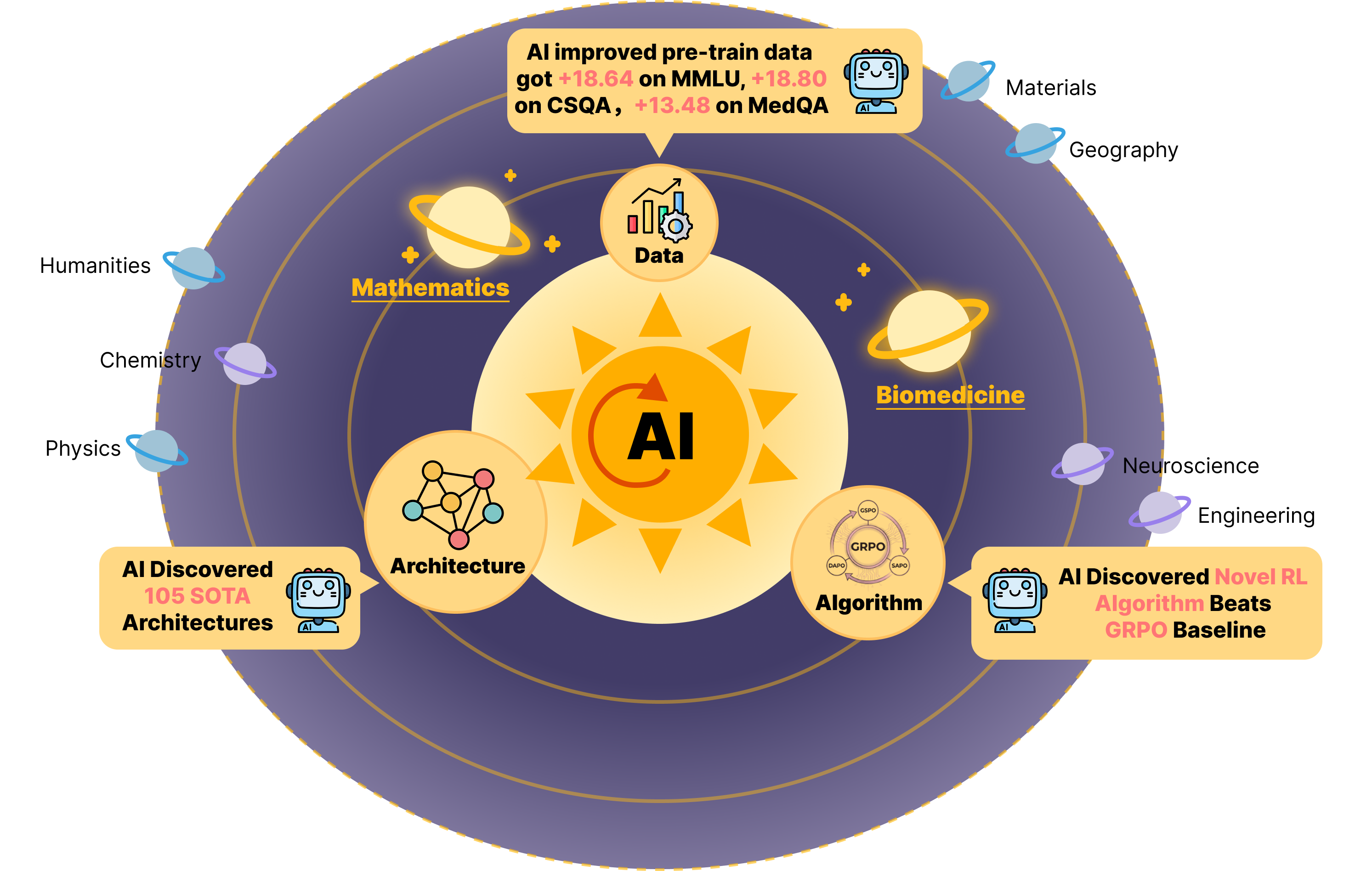
- SJTU/SII-GAIR 팀이 발표한 ASI-EVOLVE는 Learn–Design–Experiment–Analyze 순환으로 AI 개발의 세 기둥(아키텍처, 데이터, 학습 알고리즘)을 자동 탐색하는 에이전틱 진화 프레임워크다.
- 선형 어텐션 아키텍처 105개 SOTA 발견, 프리트레이닝 데이터 큐레이션에서 MMLU +18.64점, RL 알고리즘 설계에서 GRPO 대비 최대 +12.5점을 달성했다.
- 핵심은 두 가지 — 인간 사전지식을 주입하는 Cognition Base(cold-start 가속)와 다차원 실험 결과를 인사이트로 증류하는 Analyzer(지속 개선) — 가 기존 진화적 프레임워크와 차별화되는 지점이다.
문제의식: 기존 AI-for-Science 시스템의 한계
AI가 과학 연구를 자동화하는 시도는 단계적으로 발전해 왔다.
- 과학 QA: GPQA, HLE, SciMaster — 실험 없이 답을 맞추는 수준
- 구조화된 태스크 실행: MLE-bench, SWE-bench, AI Scientist — 명확한 목표 하의 최적화
- 경량 발견: AlphaEvolve, FunSearch — 진화 탐색으로 실제 수학/알고리즘 발견, 하지만 단일 함수 수준
진짜 AI 연구 루프는 이보다 훨씬 어렵다. 대규모 코드베이스 수정, GPU 시간 단위의 검증 비용, 다차원 피드백 해석이 필요하다.
논문은 이 난이도를 Scientific Task Length(L_task)라는 프레임워크로 정리한다:
- C_exec (실행 비용): 한 번 시도에 드는 GPU 시간과 엔지니어링 복잡도
- S_space (탐색 공간 복잡도): 열린 목표, 사전 정의된 경계 부재
- D_feedback (피드백 복잡도): 다차원 신호를 종합해야 하는 난이도
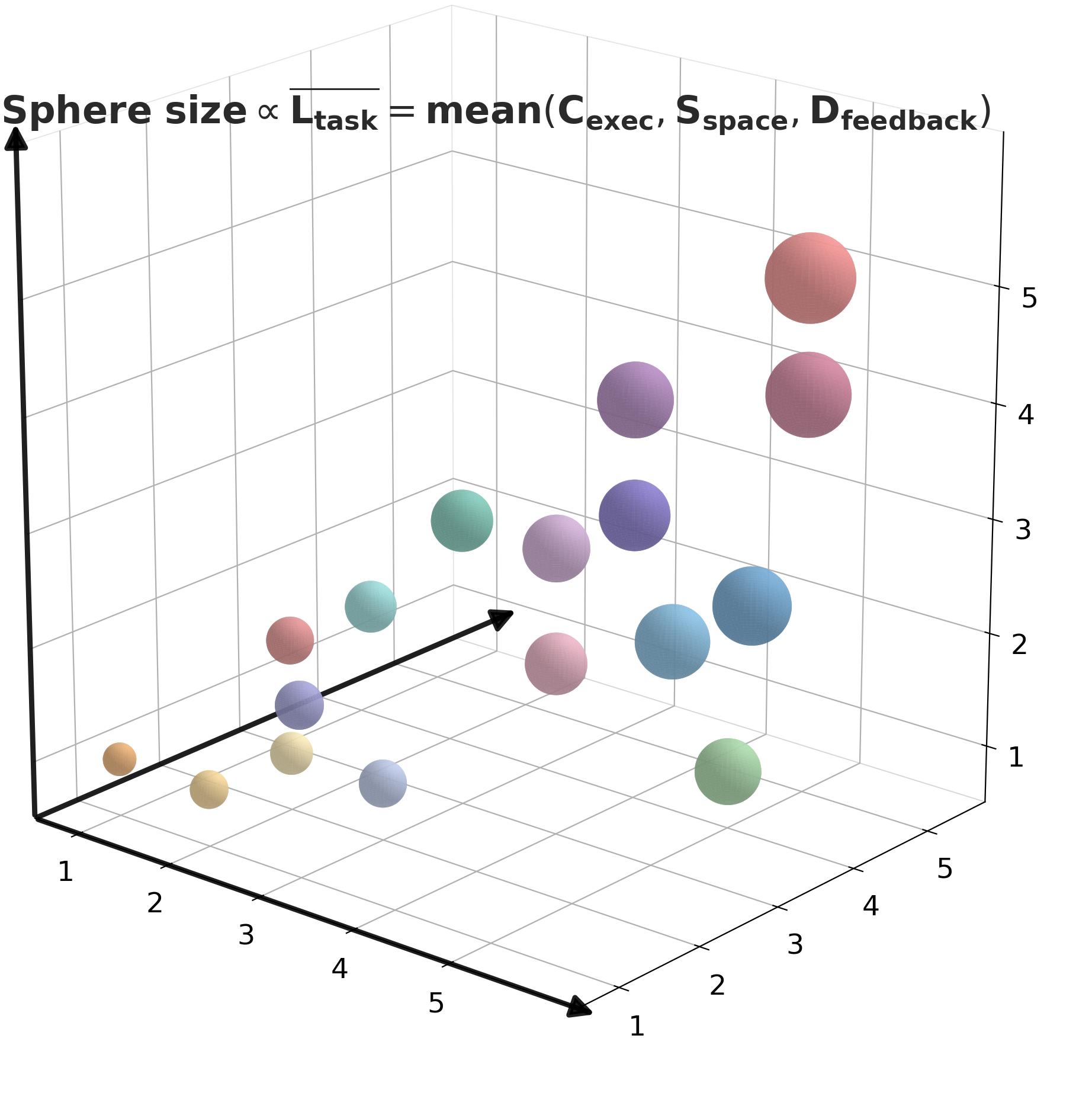
기존 시스템은 D_feedback이 낮은 영역에 머물렀다. ASI-EVOLVE는 세 축 모두 높은 영역을 최초로 다룬다.
프레임워크: Learn–Design–Experiment–Analyze
매 라운드마다 네 단계를 순환한다:
- Learn — Database에서 과거 노드를 샘플링하고, Cognition Base에서 시맨틱 검색으로 관련 사전지식을 가져온다
- Design — Researcher(LLM)가 컨텍스트를 받아 새 후보 프로그램 + 동기(motivation)를 생성한다
- Experiment — Engineer가 후보를 실제 환경에서 실행하고 정량 평가를 수행한다
- Analyze — Analyzer가 원시 로그·벤치마크·효율 트레이스를 압축된 의사결정용 보고서로 증류한다
기존 진화적 프레임워크(AlphaEvolve, OpenEvolve)가 후보 솔루션을 진화시키는 것과 달리, ASI-EVOLVE는 인지 자체를 진화시킨다. 축적된 경험과 증류된 인사이트가 다음 탐색 방향의 근거가 된다.
Cognition Base의 역할
도메인 문헌에서 추출한 휴리스틱·알려진 함정·설계 원칙을 임베딩으로 색인한다. 매 라운드 시맨틱 검색으로 관련 항목을 주입하여 cold-start 탐색 속도를 현저히 높인다.
- 아키텍처 검색: 100편 논문에서 150개 항목
- RL 알고리즘 설계: GRPO 이후 최신 10편
- 데이터 큐레이션: 카테고리별 샘플 관찰로 품질 이슈 식별
Analyzer의 역할
대규모 실험에서는 단일 스칼라 점수로는 다음 탐색 방향을 결정할 수 없다. Analyzer는 원시 로그·벤치마크 분포·효율 트레이스를 수신하여 인과 분석을 수행하고, 압축된 보고서를 DB에 저장한다. 컨텍스트 길이를 관리하면서 분석 깊이를 유지하는 것이 핵심이다.
시나리오 1: 선형 어텐션 아키텍처 설계
설정: DeltaNet을 베이스라인으로, O(N) 복잡도의 새 어텐션 레이어 설계
규모: 1,773라운드, 1,350개 후보, 105개가 DeltaNet 초과
검증 전략: 3단계 — 20M 탐색 → 340M 검증 → 1.3B 대규모(100B 토큰, 16 벤치마크)
핵심 결과:
- 최고 모델(FusionGatedFIRNet): 전체 평균 52.01%, DeltaNet 51.04% 대비 +0.97점
- 최근 인간 SOTA 개선(Mamba2의 +0.34점)의 약 3배
- 6개 OOD 벤치마크에서도 일반화 이득 유지
발견된 설계 원리: 상위 5개 아키텍처 모두 고정 할당이 아닌 적응적 다스케일 라우팅에 수렴했다. 독립 시그모이드 게이트, 학습 가능한 온도, 엔트로피 페널티 등의 기법이 공통적으로 등장했으며, 이는 “구조적 선택보다 원칙적 적응 라우팅이 핵심 레버"라는 점을 시사한다.
한계: 어텐션 메커니즘 수준의 설계이므로 하드웨어 최적화 CUDA 커널은 직접 생성할 수 없다.
시나리오 2: 프리트레이닝 데이터 큐레이션
설정: Nemotron-CC(672B 토큰)의 카테고리별 큐레이션 전략 자동 설계
방법: Cognition에 카테고리별 품질 이슈를 저장하고, Researcher가 전략을 생성하며, Analyzer가 50개 원본-정제 쌍을 평가
핵심 결과 (3B 모델, 500B 토큰):
- 전체 평균 +3.96점 (Nemotron-CC 40.17 → Nemotron-CC_ASI+ 44.13)
- MMLU +18.64점, CSQA +18.80점, MedQA +13.48점
- DCLM, FineWeb-Edu, Ultra-FineWeb을 동일 조건에서 초과
수렴한 패턴: 시스템은 처방 없이 자발적으로 “타깃 노이즈 제거 + 포맷 정규화 + 도메인별 보존 규칙” 조합에 수렴했다. 최적화/차선 전략 간 2.93점 차이는 반복 정제의 가치를 보여준다.
시나리오 3: RL 알고리즘 설계
설정: GRPO를 베이스라인으로, 어드밴티지 할당과 그래디언트 계산 메커니즘 재설계
규모: 300라운드, 10개 알고리즘이 탐색 단계에서 GRPO 초과, 3개가 14B 스케일에서 유의미한 개선
핵심 결과:
- AMC32 +12.5점 (67.5 → 80.0)
- AIME24 +11.67점 (20.00 → 31.67)
- OlympiadBench +5.04점 (45.92 → 50.96)
주목할 두 알고리즘:
알고리즘 A (쌍별 비대칭 최적화): 그룹 평균 대신 tanh 정규화된 쌍별 보상 차이로 어드밴티지를 계산한다. 비대칭 클리핑으로 PPO 윈도우를 동적 조절하고, High-Impact Gradient Dropout으로 고영향 토큰의 과적합을 방지한다.
알고리즘 B (예산 제한 동적 반경): 백분위 기반 어드밴티지 정규화와 Global Update Budget(z_cap)으로 토큰별 신뢰 업데이트 반경을 수학적으로 보장한다. exp(c) × |A| ≤ z_cap 바운드로 전체 정책 업데이트를 예산 내에 제한한다.
실증 분석
Circle Packing 벤치마크
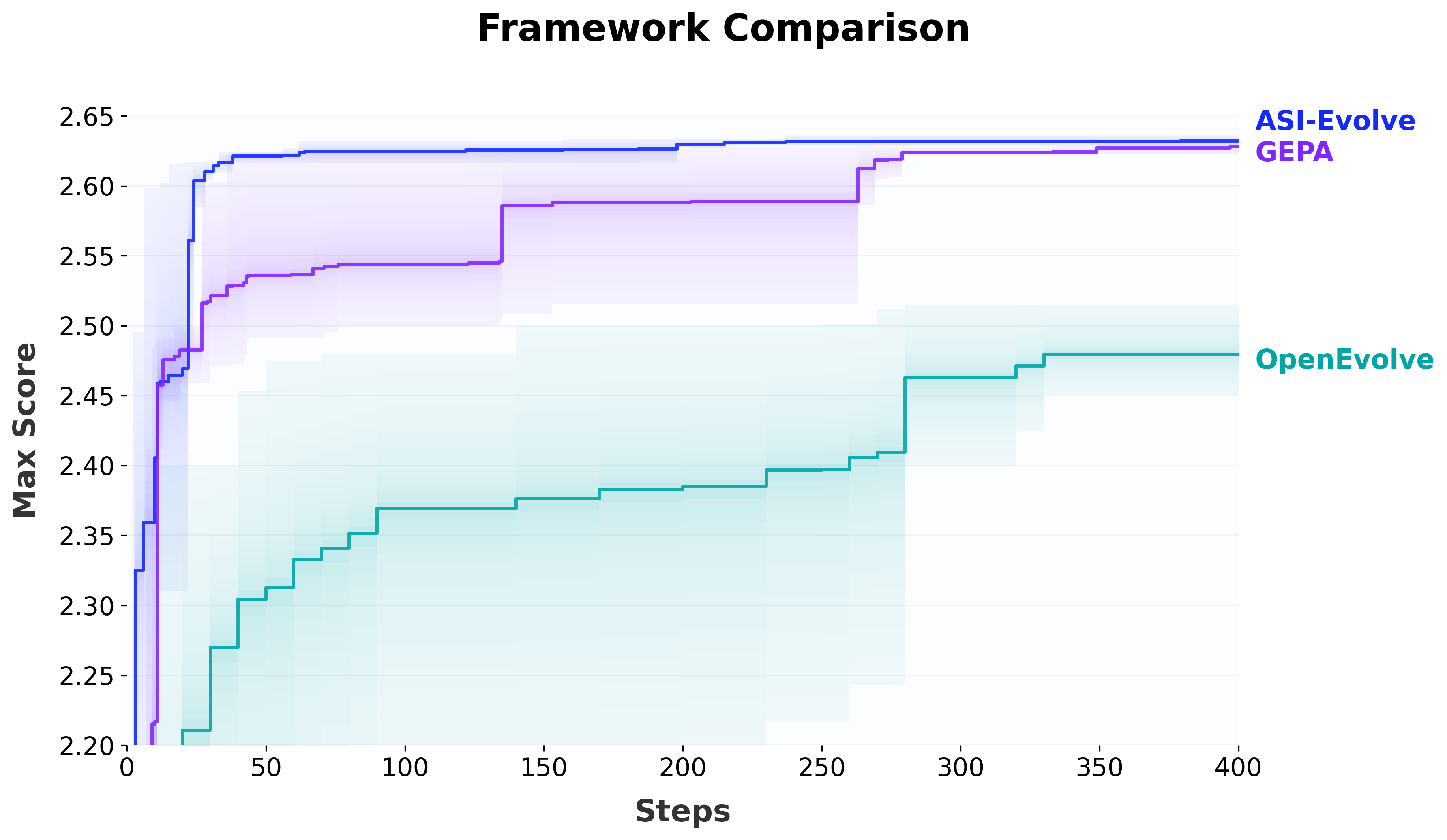
AlphaEvolve의 circle packing 태스크(26개 원, 1×1 정사각형)에서:
- ASI-EVOLVE: 17스텝만에 2.63597 달성 (SOTA급)
- OpenEvolve: 460스텝, 2.6343
- GEPA: 2.630 수렴
UCB1 샘플링 + 강한 Cognition 사전지식 조합이, 다양성 보존 샘플러(MAP-Elites)보다 빠른 수렴을 보였다. 사전지식이 이미 방향성을 제공하므로, 추가적인 다양성 강제가 오히려 비효율적이었다.
어블레이션
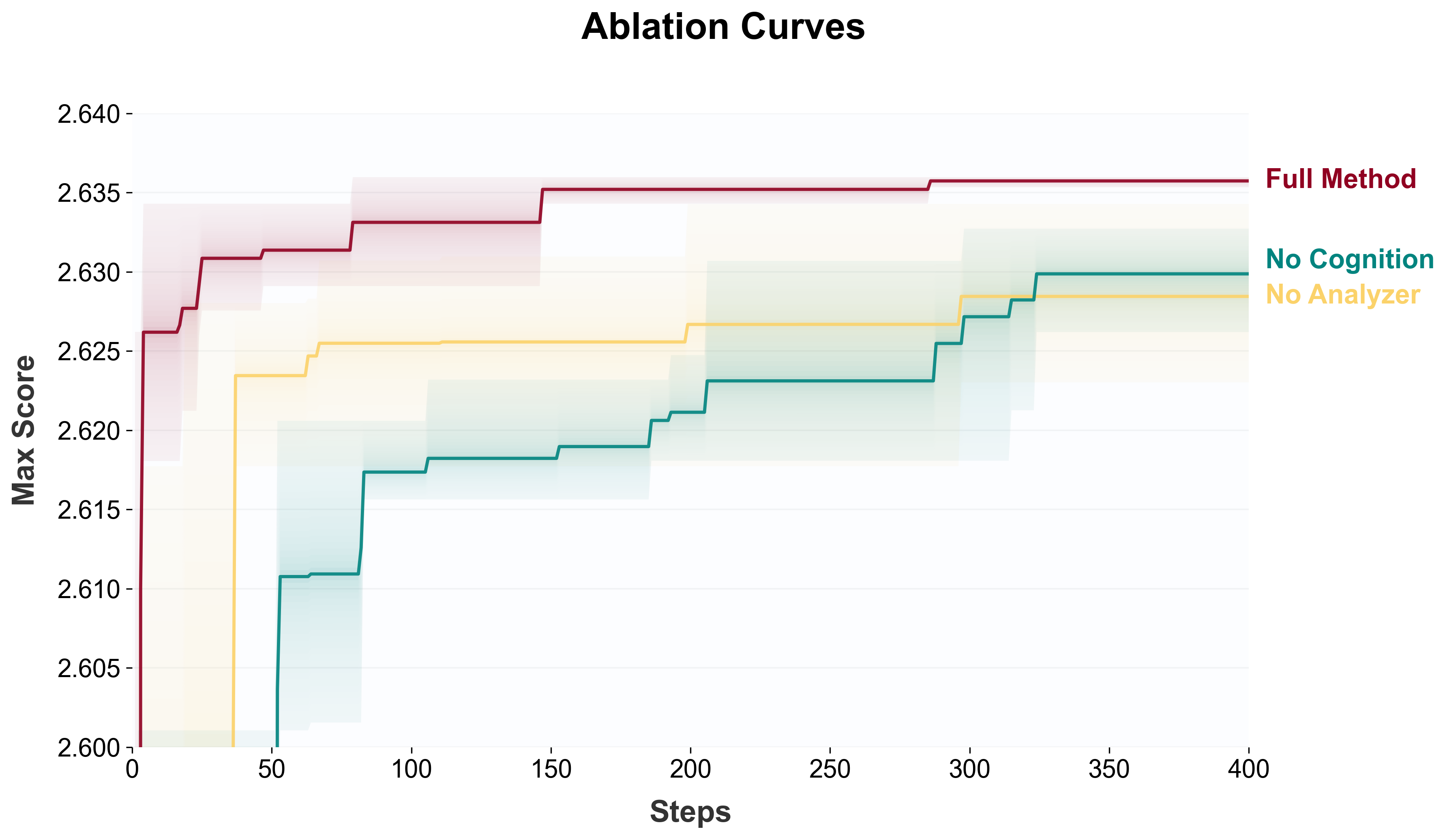
- No Analyzer: 초기 점수는 높지만(Cognition 덕분) 이후 장기 정체
- No Cognition: cold-start 비용 증가, 하지만 자기학습으로 장기 회복 가능
- 두 컴포넌트는 상보적: Cognition이 cold-start를, Analyzer가 지속 개선을 담당
AI 스택 너머: 약물-표적 상호작용 예측
DrugBAN을 시드로 DTI 아키텍처를 진화시켰다:
- Cold-start 시나리오(미지 약물): AUROC +6.94점
- 이중 cold-start(미지 약물+단백질): +4.36점
- Sinkhorn 어텐션(최적 전송 기반), 도메인별 주변화, Top-k 희소 게이팅이 핵심 혁신
가장 흥미로운 지점
이 논문에서 가장 인상 깊은 것은 “솔루션이 아니라 인지를 진화시킨다"는 관점의 전환이다. 기존 AlphaEvolve 등이 코드 조각을 진화시키는 반면, ASI-EVOLVE는 “왜 이 방향이 유망한가"에 대한 지식 자체가 라운드마다 축적되고 갱신된다. Analyzer가 다차원 실험 결과에서 인사이트를 증류하고, 이것이 다음 탐색의 컨텍스트가 되는 구조다.
어블레이션에서 보이는 패턴도 시사적이다. Cognition 없이도 시스템은 결국 자기학습으로 회복하지만, Analyzer 없이는 장기 정체에 빠진다. 이는 “사전지식 주입"보다 “실험 결과의 구조화된 해석"이 지속적 개선의 더 핵심적인 병목이라는 점을 보여준다.
출처
SJTU / SII-GAIR, 2026년 3월 31일 저자: Weixian Xu, Tiantian Mi, Yixiu Liu, Yang Nan, Zhimeng Zhou 외 원문: https://arxiv.org/abs/2603.29640 코드: https://github.com/GAIR-NLP/ASI-Evolve