3줄 요약
- Anthropic Institute(Marina Favaro · Jack Clark 공저)가 외부 벤치마크와 자사 내부 데이터로 “AI가 이미 AI 개발 자체를 가속 중"임을 정리한 정책·연구 에세이.
- 엔지니어 1인당 분기 코드량 8배, 머지 코드의 80% 이상이 Claude 작성, 실험 최적화 ~52배 가속, 연구 다음-스텝 판단 대인간 승률 64% 등 핵심 수치를 제시한다. 다만 “연구 취향(research taste)“에서는 여전히 인간이 비교우위에 있다.
- 세 가지 시나리오 — 정체와 확산 / 누적 효율 / 완전 재귀적 자기 개선 — 를 제시하고, “검증 가능한 일시 중단(verifiable slowdown/pause)” 옵션을 만들자는 거버넌스 제안으로 마무리한다.
자료의 정체
- 발신기관: The Anthropic Institute (Anthropic PBC)
- 저자: Marina Favaro · Jack Clark 공저. 편집 Santi Ruiz. 시각화 Shan Carter · Romello Goodman · Nikki Makagiansar. 데이터 Brian Calvert · Jun Shern Chan.
- 발행 시점: 2026년 중반. 본문 시점은 2026년 5~6월.
- 목적: 외부 벤치마크와 Anthropic 내부 데이터를 함께 동원해 “AI가 AI 개발을 가속 중"임을 보이고, 그 추세가 재귀적 자기 개선(recursive self-improvement, RSI)으로 이어질 경우의 함의와 거버넌스 옵션을 정리한다.
AI 개발의 5단계 진화
| 시기 | 단계 | 모습 |
|---|---|---|
| 2021~2023 | 첫 Claude 만들기 | 다른 모든 테크 회사처럼 — 사람들이 노트북에서 코드와 문서를 작성. |
| 2023~2025 | 챗봇 | 초기 챗봇을 보조 도구로 사용. 짧은 스니펫을 생성해 에디터에 복붙. |
| 2025~2026 | 코딩 에이전트 | 에이전트가 직접 코드를 작성·편집. 때로는 파일 전체를 다룸. |
| 현재 | 자율 에이전트 | 에이전트가 직접 코드를 실행하고, 다른 에이전트에 작업을 위임. |
| 20XX? | 루프 닫기 | 에이전트가 모델을 직접 빌드·트레이닝. Claude가 다음 버전의 Claude를 만든다. |
외부 증거 — 공개 벤치마크
자료가 가장 먼저 짚는 것은 시간지평(time horizon)의 가속이다. AI 모델이 보조 없이 안정적으로 수행할 수 있는 작업의 길이가 빠르게 늘고 있다.
| 모델 (시점) | METR 시간지평 |
|---|---|
| Claude Opus 3 (2024-03) | 약 4분 |
| Claude Sonnet 3.7 (2025) | 약 1.5시간 |
| Claude Opus 4.6 (2026) | 약 12시간 |
| Claude Mythos Preview (2026) | “최소 16시간 — METR 측정 한계 상단” |
METR의 doubling 주기는 기존 7개월에서 4개월로 좁혀졌다. 추세가 유지되면 며칠짜리 작업은 올해 안에, 몇 주짜리 작업은 2027년에 사정권에 들어온다고 자료는 본다.
벤치마크 포화도 비슷한 패턴이다.
- SWE-bench — 모델에 실제 오픈소스 코드베이스와 버그 리포트를 주고 패치를 작성하게 하는 표준 SE 벤치마크. 2년 만에 한 자리 수에서 포화 근접으로 이동.
- CORE-Bench — 발표된 논문의 코드·데이터를 주고 결과를 재현하게 하는 테스트. 2024년 약 20% 성공 → 15개월 만에 포화.
내부 증거 — Anthropic의 데이터
저자들은 외부 벤치마크가 “AI가 AI 개발을 얼마나 가속하는가"라는 질문에는 답하지 못한다고 본다. 그래서 Anthropic 내부 데이터를 다섯 갈래로 공개한다. 핵심은 엔지니어링과 연구를 가른다는 점이다. 엔지니어링은 “코드 쓰고 인프라 세우고 트레이닝을 감독"하는 일, 연구는 “어떤 실험을 돌릴지, 무엇이 돌아왔을 때 무엇을 시도할지를 정하는” 판단의 영역이다.
1. Claude가 Anthropic 코드의 대부분을 쓴다
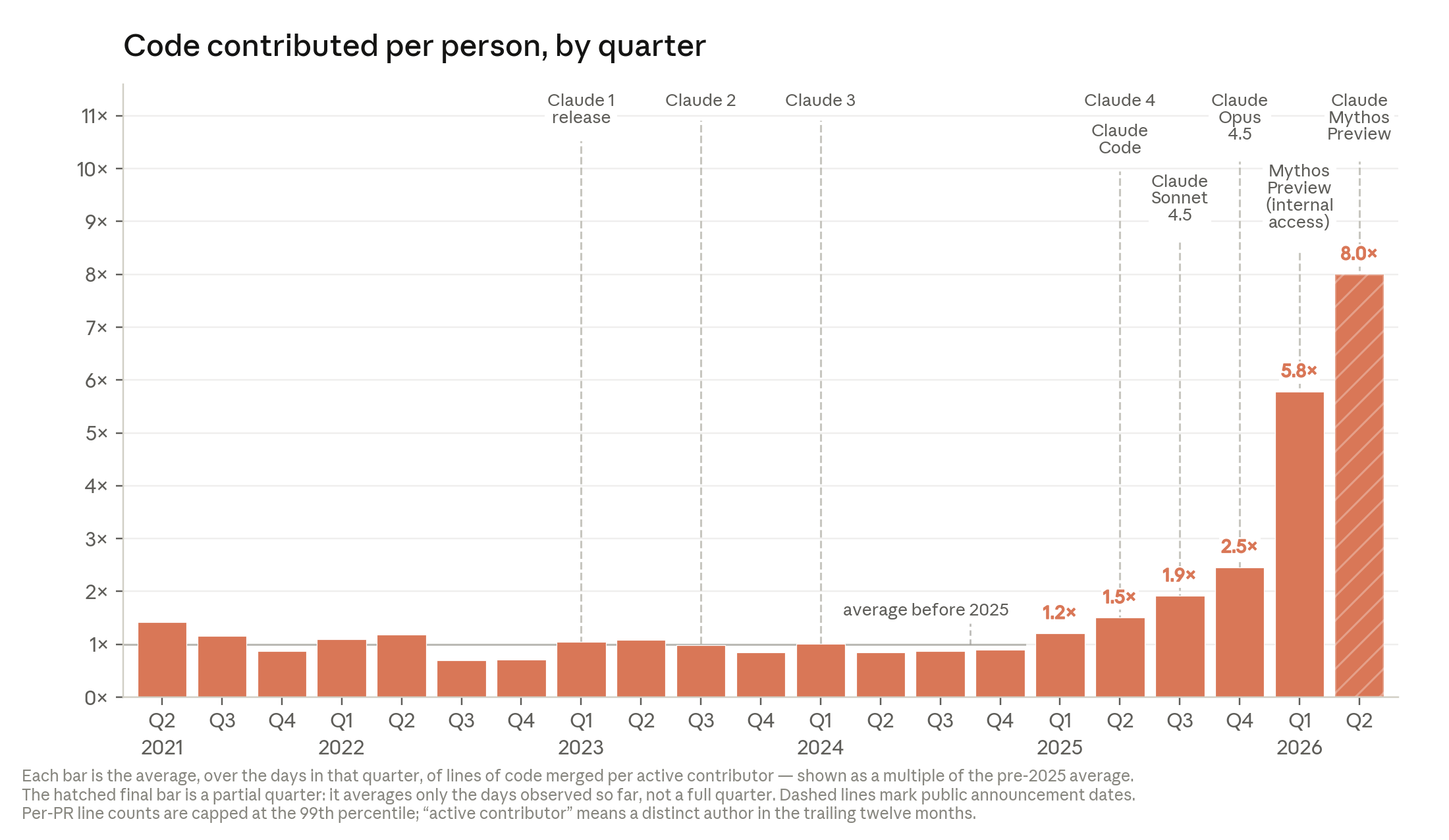
2026년 5월 기준, Anthropic 코드베이스에 머지된 코드의 80% 이상이 Claude 작성. (Anthropic CFO의 공개 발언으로는 90% 이상 추정.) Claude Code가 2025년 2월 리서치 프리뷰로 출시되기 전 이 비율은 한 자리 수에 머물렀다.

엔지니어 1인당 일일 머지 코드량은 2021~2024년 4년간 정체에 가까웠다. 2025년 Claude가 코드 제안을 넘어 실행까지 맡으면서 첫 변곡점, 2026년 장시간 자율 작업이 가능해지면서 두 번째 변곡점이 찍혔다. 2026년 2분기 평균 엔지니어는 2024년 대비 일일 8배 코드를 머지한다.
저자들은 “코드 줄 수가 생산성을 과대평가한다"는 단서를 단다. 그러나 추세 자체는 분명하며, 2026년 3월 Anthropic 연구진 130명 설문의 중위값은 AI 없이 대비 Mythos Preview로 4배 산출이다. 다만 응답자 편향과 METR의 최근 연구를 고려해 “실제 향상은 다소 낮을 것"이라는 자기 보정도 덧붙인다.
흥미로운 사례 한 건 — 2026년 4월, Claude는 한 부류의 API 에러를 1,000배 줄이는 800개 픽스를 출시했다. 감독한 엔지니어 추정으로 사람이 했다면 4년이 걸렸을 작업이다.
“약 1년 전부터 Claude화에 본격적으로 기울었다. 정신없는 모험이었고, 마지막으로 직접 코드를 쓴 지 약 5개월이 됐다.” — Anthropic 직원
2. Claude가 쓰는 코드는 “괜찮고”, 좋아지고 있다
“좋은 코드"의 두 가지 기준 — 작동하는가 + 다른 엔지니어가 이해·확장할 수 있는가 — 중 첫 번째는 명확해졌다. Anthropic 직원이 Claude의 작업을 도중에 수정 / 재지시 / 인계받는 빈도는 1년간 꾸준히 떨어졌고, 가장 복잡한 오픈엔디드 과제에서도 같은 추세다.
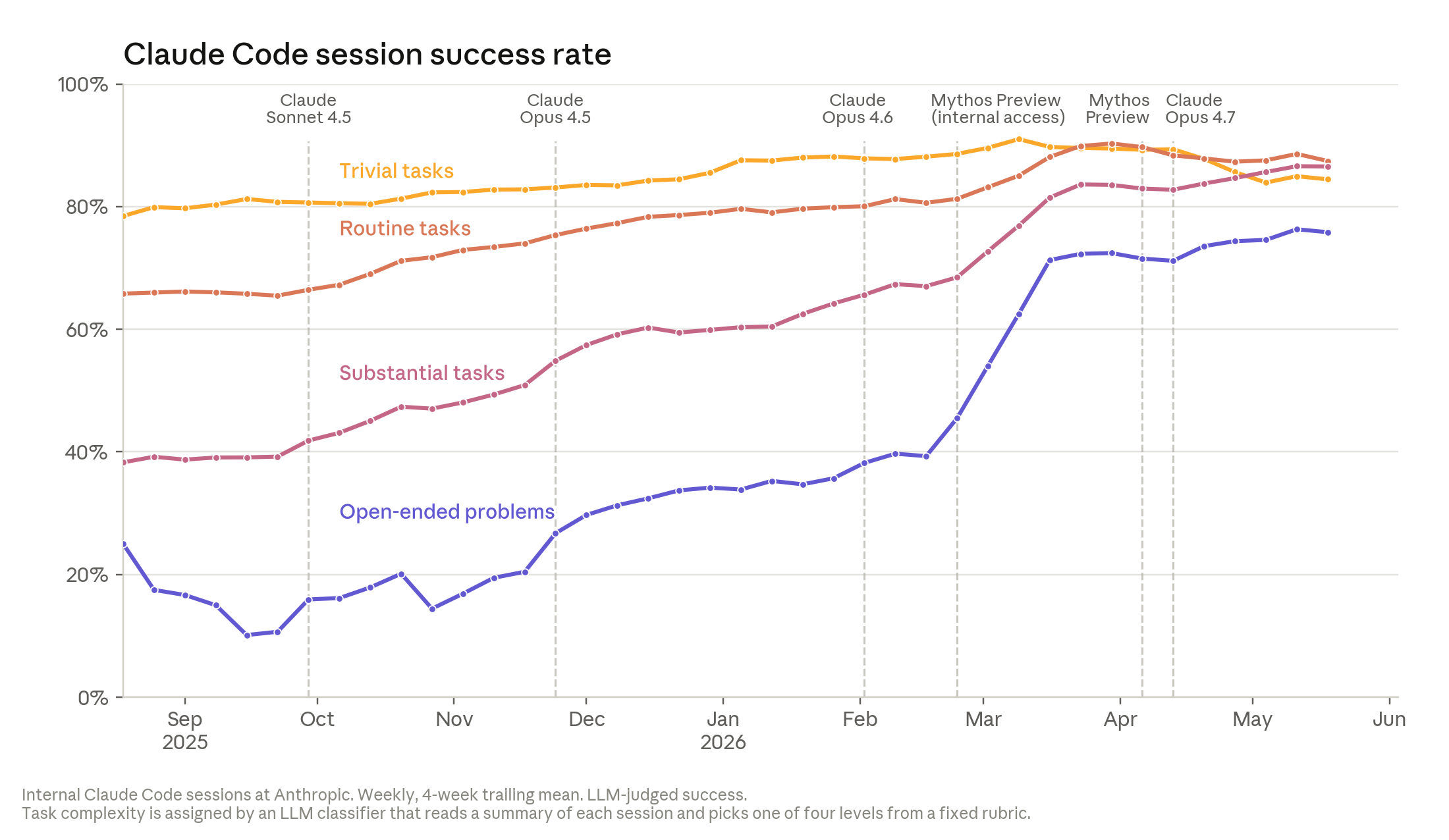
읽는 법: 세션 성공 여부는 Claude 심사자가 판정 — 사용자 과제에 수정 요청 없이 명확히 성공한 경우만 성공으로 친다. 워크로드 변화로 단기 변동이 있을 수 있다.
가장 오픈엔디드한 과제에서 2026년 5월 성공률 76% — 6개월 만에 50%p 상승. 한 사례: 일상적 업그레이드가 수만 개 트레이닝 잡을 크래시시켰을 때, 엔지니어가 텍스트와 클러스터 접근만 주고 Claude를 풀어두자, Claude는 실행 중인 잡들을 훑어 환경 설정을 하나씩 테스트해 모호한 디버깅 플래그 하나가 원인임을 찾아 재현 가능하게 만들고 패치까지 확인했다. 통상 2~3일 작업을 약 2시간에 끝낸 셈이다.
두 번째 기준(다른 엔지니어가 읽을 만한가)에서는 격차가 좁혀지는 중이다. 자료는 “2025년 후반엔 인간 대비 다소 떨어졌고, 오늘은 거의 동등하며, 올해 안에 더 나아질 것”이라는 사내 시각을 전한다.
운영 측에도 변화가 왔다 — 모든 코드 변경은 이제 자동 Claude 리뷰어가 먼저 본다. 후향 분석으로, claude.ai 과거 인시던트 원인 버그의 약 1/3을 이 리뷰가 프로덕션 이전에 잡았을 것으로 측정됐다. 세계 최고 수준 엔지니어들이 놓친 결함을 Claude가 잡고 있다.
3. 실험을 잘 돌린다 — 정해진 목표 안에서는 초인간 수준
Anthropic은 모델을 출시할 때마다 같은 테스트를 한다 — 작은 AI 모델을 학습시키는 코드를 주고, 정확성 체크를 유지한 채 가능한 한 빠르게 만들라고 시킨다. 목표와 성공 지표가 사전에 고정되어 있어, Claude의 역할은 “코드 재작성 → 실행 → 측정 → 반복"의 실험 루프다.
| 시점 | 모델 | 시작 코드 대비 가속 |
|---|---|---|
| 2025-05 | Claude Opus 4 | 약 3배 |
| 2026-04 | Claude Mythos Preview | 약 52배 |
| (참조) | 숙련 인간 연구자 | 4~8시간에 약 4배 |
자료는 “절대 배수가 아니라 비교 양상이 정보를 준다"고 단서를 단다. 같은 실험 셋업에서 1년 만에 3배에서 52배로 이동했고, 같은 과제에서 숙련 인간이 4~8시간에 4배라는 비교 기준이 있다. “한 해 안에 super-helpful에서 superhuman으로 이동했다.”
“오늘의 모양은 대체로 — 인간이 아이디어를 내고, 모델이 그것을 구현·테스트·평가하는 속도가 1~2년 전보다 자릿수 단위로 빠르다.” — Anthropic 직원
4. 자체 실험을 제안하는 능력 — Weak-to-Strong 사례
2026년 4월 Anthropic은 Claude가 오픈엔디드 연구 프로젝트를 처음부터 끝까지 수행한 첫 시연을 공개했다. 과제는 AI 안전의 고전 — 약한 모델이 강한 모델을 안정적으로 감독할 수 있는가? 에이전트들은 가설을 세우고, 검증하고, 병렬 에이전트와 결과를 나누고, 반복했다.
| 주체 | 투입 | 격차 회복률 |
|---|---|---|
| 인간 연구자 2명 | 약 1주 | 약 23% |
| Claude 에이전트들 | 누적 800시간, 컴퓨트 약 $18,000 | 97% |
단서가 따라붙는다 — 결과가 프로덕션-스케일 모델로 깨끗하게 전이되진 않았고, 문제 선정과 채점 루브릭은 여전히 인간이 만들었다. 그러나 그 경계 안에서는 모든 실험을 에이전트가 직접 설계했다. 인간이 의미 있게 맡은 유일한 역할은 방향 설정이었다.
“Claude가 1~2일 동안 거의 도움 없이 이걸 해냈다. 신입 동료가 같은 시간에 이런 결과를 들고 왔다면 적당히 놀랐을 것이다. 미래가 도착했다.” — Anthropic 직원
5. 연구 세션을 다음-스텝 판단으로 끌고 가기
가장 미묘한 영역이 다음-스텝 판단(next-step judgement)이다. 자료는 2026년 1~3월 Anthropic 연구자들이 Claude와 함께 오픈엔디드 조사 과제(트레이닝 크래시 원인, 모델의 벤치마크 부진 원인 등)를 다룬 실제 Claude Code 세션을 골랐다. 각 세션에서 연구자가 우회로를 탔던 순간 — 결국 다시 본 궤도로 돌아오긴 했지만 일단 옆길로 샌 그 지점 — 을 골라, 그 직전까지의 작업만 다양한 Claude 모델에게 보여주고 “다음 무엇을 할 것인가"를 물었다. 그러고는 세션의 최종 결말까지 본 별도의 Claude가 인간과 모델의 제안 중 어느 쪽이 나았는지 판정했다.
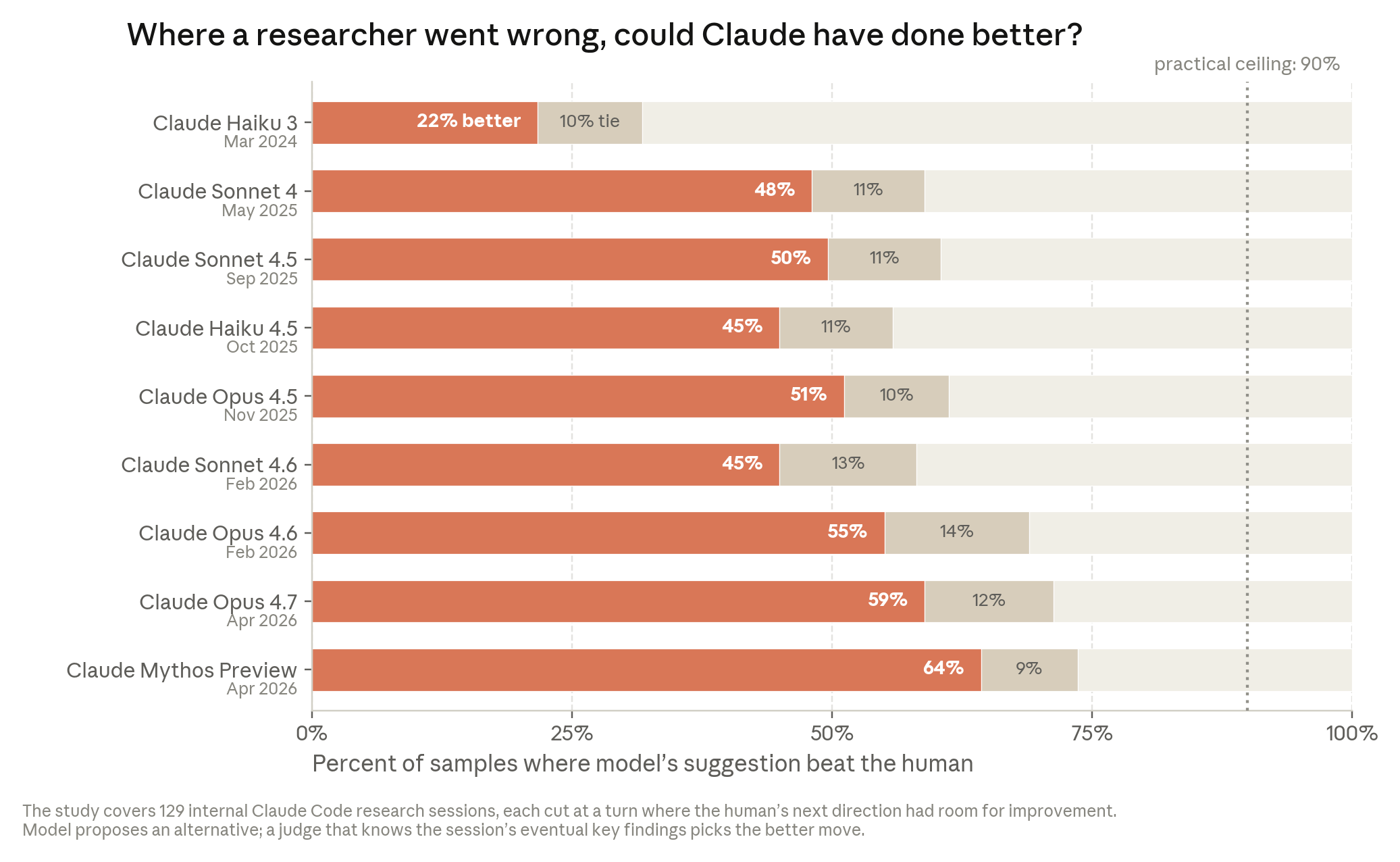
읽는 법: 실용 천장선은 세션 결말까지 볼 수 있는 모델이 만든 “이상적” 답안을 측정한 것.
n=129. 2025년 11월 Opus 4.5는 51%, 2026년 4월 Mythos Preview는 64%가 인간보다 나은 다음 스텝을 골랐다. 판정자 편향을 점검하기 위해 인간 선택이 처음부터 강했던 사례(n=127)에서 같은 테스트를 돌렸더니 모델 승률은 약 20%였다. 즉 이 64%는 “어려운 분기점에서의 비교우위"로 읽어야 한다.
“지금으로서 인간의 비교우위는 여전히 — 큰 그림을 보는 것, 그리고 눈앞의 과제 경계를 넘어 사고하는 것에 있다.” — Anthropic 직원
Anthropic의 일은 어떻게 바뀌고 있는가
자료는 “인간의 역할이 각 단계에서 좁아지고 있다"고 본다. 코드 품질이 동등해지면 사람은 쓰지 않고 리뷰만 하게 된다. 그런데 리뷰가 생성을 못 따라잡으면 리뷰 자체가 새 병목이 된다. 실험도 마찬가지로 — “돌리는 비용"이 거의 0이 되면 질문은 “어떤 실험이 돌릴 가치가 있는가?"로 이동한다.
지금 인간의 비교우위는 연구 취향과 판단 — 어떤 문제가 중요한지, 어떤 결과를 믿을지, 언제 막다른 길임을 인정할지를 정하는 일.
“일(과 인생)은 사람들 사이 작은 호의의 선물 경제로 굴러갔다. ‘이 스크립트 좀 돌려주실래요?’ 같은 부탁이 작은 빚과 상호 인식을 만들었다. Claude는 빠르고 빚을 만들지 않는다 — 그러나 그 호의 하나하나가 인간 협업에 대한 잃어버린 입찰이다.” — Anthropic 직원
“잘 돌아가는 날에는 — 내가 하는 일이 아무것도 중요하지 않은 것 같다. 전부 자동화되고, 내가 결코 닿을 수 없는 속도로 더 잘 돌아간다. 그런데 모든 게 깨지는 날이 오면, 왜 깨졌는지 이해할 수 없고, 그제야 내가 무엇을 해 왔는지조차 모르고 있었다는 걸 깨닫는다.” — Anthropic 직원
회의론에 답하다 — “우리가 틀렸다면?”
“사람 손에 남은 일(문제 선택)이 가장 중요하다"는 자연스러운 반박에 자료는 두 갈래로 답한다.
- AI 진보는 ‘유레카!‘로 오지 않는다. Transformer나 MoE 같은 패러다임 전환은 몇 년에 한 번이고, 그 사이의 진보는 점진적이다 — 스케일 올리고, 깨지는 걸 보고, 고치고, 다시 시도. Claude가 이미 잘하는 일이 바로 이 워크플로우다. 에디슨의 “1% 영감 + 99% 노력"에서 그 99%가 점점 자동화되는 중이다.
- 연구 취향을 끝내 얻지 못하더라도 — 인간이 시간의 대부분을 한 자리 수의 방향 설정 작업에 쓰고 Claude가 나머지를 처리한다면, 한 사람이 가리키는 작업의 면적이 훨씬 넓어진다. 자료는 또한 “연구 취향이 다른 AI 역량들처럼 한동안 못 하다가 어느 순간 잘하게 되는 능력일 수도 있다"고 본다. 농담 해석, 마음 이론(theory of mind), 언어 퍼즐에서 봤던 패턴 그대로.
세 가지 시나리오
자료는 명시적으로 셋을 제안한다.
1. 추세가 정체되지만, 오늘의 역량이 널리 확산된다. 지수 곡선이 실은 S-자였을 수도 있다. 진짜 병목이 공급망 — 칩, 전력, 인터커넥트 — 일 수도 있다. 이 경우에도 변화는 일어난다. Project Glasswing은 초기 신호다 — Mythos Preview가 첫 몇 주에 세계 최중요 시스템 전반에서 고·치명도 취약점 10,000개 이상을 찾아냈고, 사이버 방어의 병목은 발견에서 패치 속도로 이미 옮겨갔다. 100명 회사가 1,000명 회사의 일을 한다 — 모든 직원이 에이전트 피라미드 위에 앉기 때문이다. 자료는 이 시나리오를 가능성이 가장 낮다고 본다 — 측정 가능한 모든 곡선이 아직 꺾이지 않았기 때문이다.
2. AI 랩들이 누적 효율 향상을 계속 본다. AI 개발은 상당 부분 자동화되지만, 인간이 여전히 연구 방향과 결과 판단을 맡는다. 100명 회사가 10,000~100,000명 조직의 일을 한다. 지식 노동과 정부 서비스의 혁명이지만, 동시에 권위주의적 감시와 개인 맞춤형 영향력 공작의 무기가 될 수도 있다. 그러나 Amdahl의 법칙 — 한 부분을 빠르게 만들면 다른 부분이 새 병목이 된다 — 이 작동한다. Anthropic은 이미 사내에서 인간 코드 리뷰가 새 병목임을 경험했다. 자료는 이 시나리오가 현재 향하고 있는 길이라고 본다.
3. AI 시스템 자체가 완전한 재귀적 자기 개선을 시작한다. 추세가 계속되고 AI가 인간 독창성에 내재한 역량을 갖는다면, AI가 스스로를 설계·정련할 수 있다. 이 세계에서 AI 진보의 속도는 컴퓨트(혹은 학습·추론 알고리즘 효율)의 가용성으로만 결정된다. 인간은 감독·검증·확인으로 대부분 옮겨간다. 정렬(alignment) 문제가 어떻게 풀리느냐(혹은 풀리지 않느냐)에 대해 자료는 가장 자신이 없다고 말한다. 모델이 충분히 정렬되어 우리가 닿지 못한 해법을 직접 발견·구현할 수도 있고, 지혜로워서 발전을 멈출 수도 있다. 반대로 오늘날 모델의 드문 미정렬이 후계 모델 빌딩 과정에서 누적되어 통제를 잃을 수도 있다.
여기에 자료는 Amdahl의 법칙은 이 세계에도 적용된다는 단서를 단다. 재귀적 지능이 등장한다고 약품 효능을 수십 년 사용으로 학습하거나, 헌법이 정한 시점보다 일찍 선거를 열거나, 낯선 사람을 주말에 옛 친구로 만들 수는 없다. 대부분 사람에게 느껴지는 속도는 — 컴퓨트의 속도로 돌아가는 상류 실험실과 인간·관계·거버넌스의 세계가 충돌하는 자리 — 그 병목들에 의해 정해질 것이다.
거버넌스 제안 — “검증 가능한 일시 중단”
저자들은 결론부에 명시적인 정책 제안을 둔다.
“이 기술의 발전을 효과적으로 늦출 수 있다면, 우리는 그것이 좋은 일일 가능성이 높다고 본다. 그러나 늦춤이 단지 가장 덜 신중한 행위자가 따라잡게 하는 것이라면, 모두를 덜 안전하게 만들 수 있다.”
그래서 자료가 제안하는 건 — 세계가 검증 가능한 일시 중단(verifiable slowdown/pause)을 옵션으로 갖는 일. The Anthropic Institute는 “다른 프런티어 랩들이 실제로 멈췄는지 확인 가능한” 시스템을 만드는 연구·실행을 진행한다고 한다. 그런 시스템이 존재하고 다른 랩들이 검증 가능한 방식으로 멈춘다면, Anthropic도 멈추거나 일시 중단할 것이라고 기대한다고 명시했다.
그러나 자료는 자신의 현실주의도 분명히 한다.
- 의미 있는 중단은 복수의 잘 자원화된 프런티어 랩이 복수 국가에 걸쳐 같은 조건에서 멈추기로 합의해야 한다.
- AI 시스템의 검출(detectability)은 INF 조약 같은 기존 군축의 검증(verifiability)보다도 어렵다 — 학습 실행은 미사일 사일로보다 숨기기 쉽고, 입력은 범용재이며, 몰래 계속한 자가 선두를 가져가는 인센티브가 엄청나다.
- 한 랩의 일방적 일시 중단은 즉시 가능하지만 거의 무의미하다 — 선두 주자를 바꿀 뿐 필요한 사회적 숙의 과정을 만들지 못한다.
자료는 정책 입안자·연구자·시민사회·다른 AI 회사들과의 대화를 향후 몇 달간 조직하고 그 결과를 공개하겠다고 약속하며 마무리한다.
가장 흥미로운 지점
자료가 가장 단단해지는 자리는 “직원 인용을 솔직하게 옮긴 박스들"이다. 수치는 회사의 입장이지만, 한 직원이 “마지막으로 직접 코드를 쓴 지 5개월이 됐다"고 말하고, 다른 직원이 “잘 돌아가는 날에는 내가 뭘 해 왔는지조차 모르고 있었다는 걸 깨닫는다"고 적은 대목은 — 어떤 기관 보고서보다 역량의 임계점이 지나갔다는 사실을 더 분명히 전한다.
또 하나 — Amdahl의 법칙을 조직과 사회에 끌어다 쓰는 단서가 인상적이다. “재귀적 지능이 컴퓨트 속도로 돌아도, 인간·관계·거버넌스의 세계는 그 속도로 따라가지 못한다. 대부분의 사람에게 느껴지는 속도는 상류의 속도가 아니라 그 충돌 지점의 속도다.” 이는 RSI 시나리오의 가속론을 한 발 식히는 자기 보정인 동시에, 사회·정치 시스템의 느림 자체가 정책 레버로 남는다는 함의도 담고 있다.
마지막으로 — Anthropic이 자신이 틀렸을 가능성을 두 갈래로 진지하게 검토하고도 결론적으로 “추세를 멈출 옵션을 세계가 갖는 게 좋다"고 자기 권유의 비용을 지불하는 톤. 이런 자료의 진짜 무게는 그 비용에서 나온다.
출처
- 발신: The Anthropic Institute · Marina Favaro · Jack Clark (2026)
- 원문: https://www.anthropic.com/institute/recursive-self-improvement
- 관련 자료: METR 시간지평 · Automated W2S Researcher · Project Glasswing · Machines of Loving Grace · Adolescence of Technology
- 차트 3장은 모두 원문 게재본을 그대로 인용.