3줄 요약
- Anthropic이 2026년 1월에 공개한 RCT다. 주니어 SWE 52명에게 새 Python 라이브러리(Trio)를 학습시키고, AI 보조 사용 여부에 따라 직후 퀴즈 점수를 비교했다.123
- AI 보조군은 퀴즈 평균 50%, 손코딩군은 67%로 17%p 차이(Cohen’s d = 0.738, p = 0.01)였다. 격차는 디버깅 문항에서 가장 컸고, 속도 이득은 통계적으로 유의하지 않았다.
- 같은 AI 도구도 사용 방식에 따라 결과가 갈렸다. 코드 위임형 패턴은 점수가 낮았고, 코드 생성 후 follow-up 질문이나 개념 질문으로 이해를 보강한 패턴은 손코딩군과 비슷하거나 더 높은 점수를 받았다.
연구가 던지는 질문
선행 연구는 두 갈래로 갈린다. 한쪽에서는 AI가 일부 작업을 80% 빠르게 만든다고 보고하고, 다른 한쪽에서는 사람들이 AI를 쓸수록 일에 덜 몰입하고 사고 노력을 줄인다고 보고한다. 이른바 인지 오프로딩(cognitive offloading)이다.
본 연구의 질문은 그 사이에 놓인다. AI가 코드를 대신 짜주는 환경에서, 사람은 자신이 작성 중인 시스템을 정말로 이해하는가? 학습 단계의 사람은 AI 사용으로 생산성과 숙달을 동시에 얻을 수 있는가, 아니면 생산성 이득이 숙달을 잠식하는가?
AI가 점점 더 많은 코드를 쓰게 되더라도, 사람은 오류를 잡아내고 출력을 통제하고 고위험 환경의 AI를 감독해야 한다. 그 감독 역량 자체가 학습 단계에서 길러진다면, 학습 단계에 AI를 어떻게 쓰는지가 결국 감독 역량의 형성을 결정한다.
연구 설계
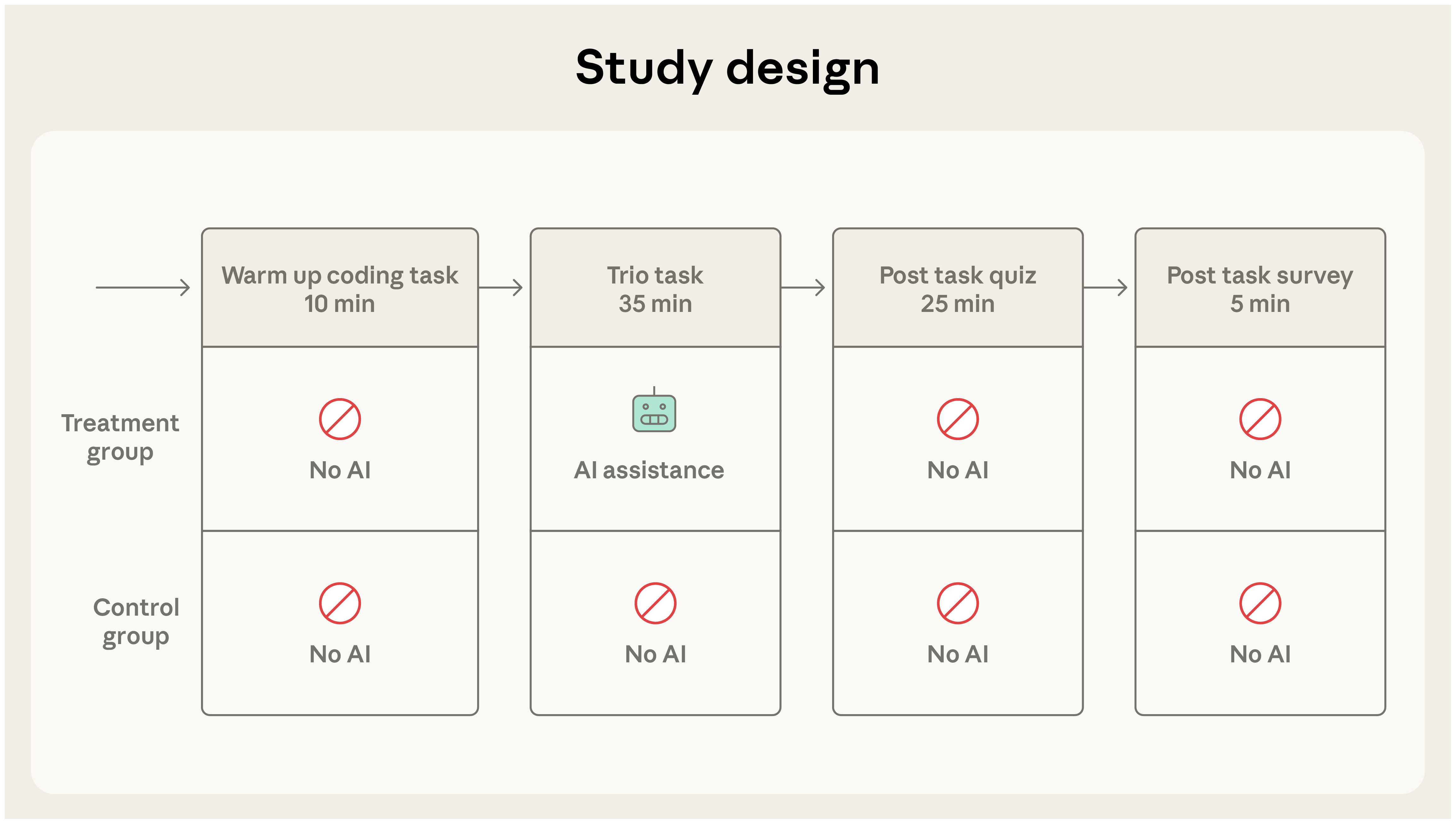
참가자 모집 조건은 다음과 같다.
- 주니어 위주의 소프트웨어 엔지니어 52명
- Python을 주 1회 이상 1년 넘게 사용한 경험
- AI 코딩 보조 도구에 어느 정도 익숙함
- 실험 과제 라이브러리인 Trio(비동기 프로그래밍)에는 미경험
실험은 세 단계로 구성됐다.
- 워밍업
- 메인 과제 — Trio로 두 개의 기능을 코딩. 비동기 프로그래밍 개념 이해가 필요한 과제.
- 퀴즈 — 방금 작성한 코드의 개념을 평가.
참가자는 퀴즈가 있다는 사실을 알고 있었지만 가능한 한 빠르게 작업하라는 지시를 받았다. AI 보조군은 사이드바에 코드 접근 권한이 있는 AI 어시스턴트(요청 시 정답 코드를 그대로 내놓을 수 있는 수준)를 썼고, 손코딩군은 보조 도구 없이 진행했다.
저자들은 CS 교육 연구를 따라 숙달 평가를 네 유형으로 나눴다.
- 디버깅: 오류를 찾고 진단하는 능력. AI 생성 코드가 틀렸을 때 그것을 감지하는 데 결정적.
- 코드 읽기: 코드의 동작을 읽고 이해하는 능력. AI가 쓴 코드를 배포 전에 검증하는 데 필요.
- 코드 쓰기: 올바른 코드를 직접 작성하거나 선택하는 능력. 저자들은 문법 암기는 비중을 낮추고 고수준 설계 쪽을 본다.
- 개념: 도구·라이브러리의 핵심 원칙 이해. 생성된 코드가 라이브러리 설계 의도에 맞는지 판단하는 데 필요.
평가의 무게는 디버깅·코드 읽기·개념에 실렸다. 이 셋이 “점점 더 AI가 쓰게 될 코드를 감독하는 역량"의 핵심이라고 본 것이다.
결과
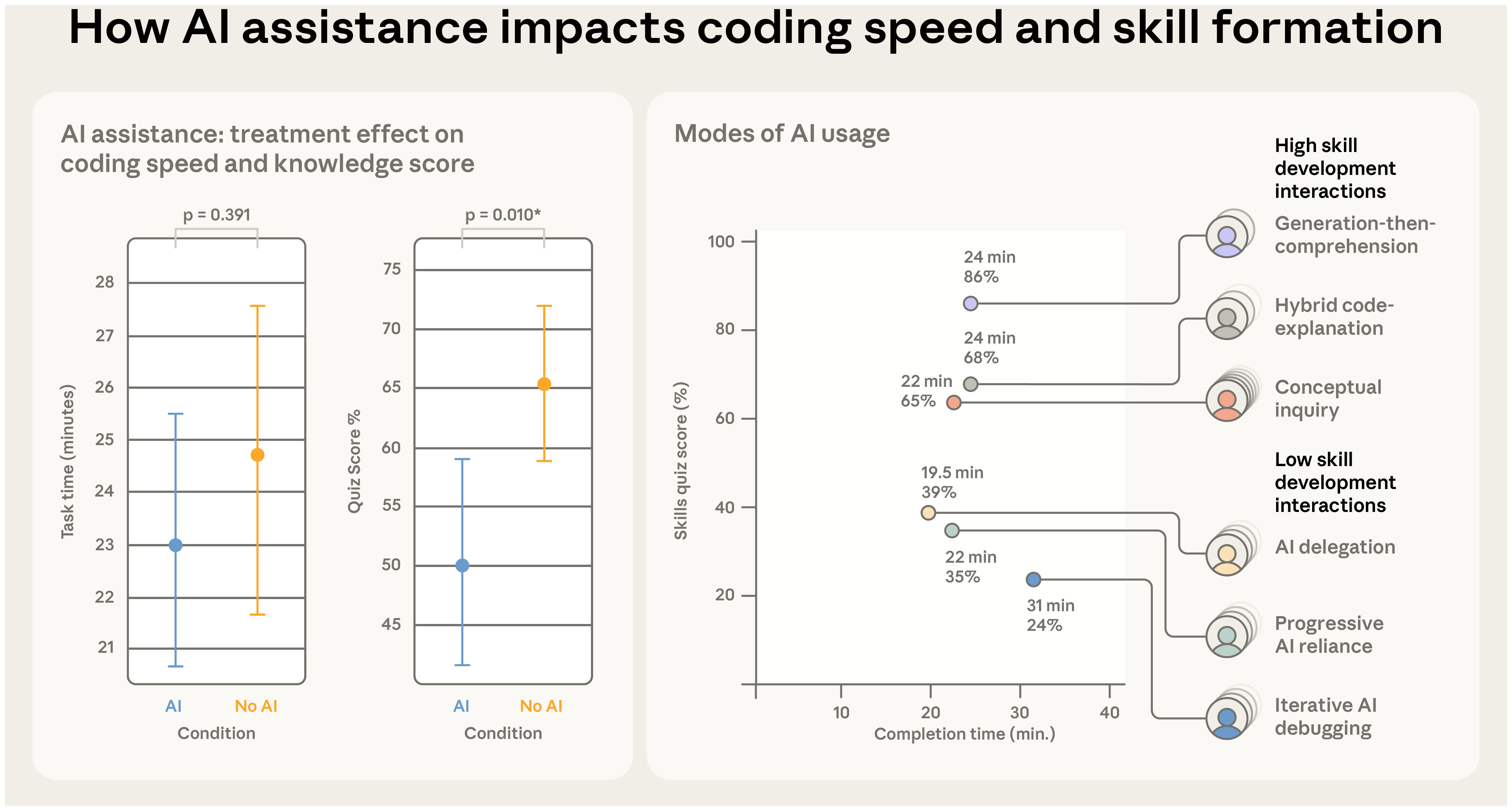
핵심 수치는 다음과 같다.
| 지표 | AI 보조군 | 손코딩군 | 비고 |
|---|---|---|---|
| 작업 완료 시간 | 약 2분 빠름 | 기준 | 통계적 비유의 |
| 퀴즈 평균 점수 | 50% | 67% | Cohen’s d = 0.738, p = 0.01 |
| 등급 환산 | ~2학점 등급 낮음 | — | — |
| 가장 큰 격차 | 디버깅 문항 | — | — |
해석은 두 갈래다.
첫째, 속도 이득은 작고 점수 격차는 컸다. AI 보조군은 평균적으로 빠르지 않았다. 일부는 11분(전체 시간의 30%)을 AI에 질의를 작성하는 데 썼고, 최대 15개 쿼리를 던졌다. 익숙하지 않은 라이브러리를 처음 다룰 때는 AI 활용 자체가 인지 비용을 발생시키는 것으로 보인다.
둘째, 디버깅에서 격차가 가장 컸다. 손코딩군은 더 많은 오류를 만났고 — 문법 오류와 Trio 개념 오류 모두 — 그 오류를 직접 해결하면서 디버깅 회로를 훈련했을 가능성이 있다. AI 보조군은 오류 자체에 노출되는 빈도가 낮았다.
AI 상호작용 패턴 — 같은 도구, 다른 결과
저자들은 화면 녹화를 수동 주석으로 분석해 AI 보조군 내부의 행동 패턴을 분류했다. 같은 도구를 같은 시간 쓴 사람들이 점수에서 크게 갈렸기 때문이다.
저점 패턴 (퀴즈 평균 40% 미만)
AI에 대한 강한 의존이 공통점이다. 독립적 사고가 적고 인지 오프로딩이 크다.
- AI delegation (n=4) — AI에 코드 작성을 전적으로 위임. 가장 빠르고 오류가 거의 없었다.
- Progressive AI reliance (n=4) — 처음에는 한두 질문만 던지다가 결국 모든 코드 작성을 AI에 넘김. 두 번째 과제의 개념을 거의 익히지 못해 점수가 낮았다.
- Iterative AI debugging (n=4) — AI를 디버깅·검증 도구로 사용. 질문은 많이 던졌지만, 자기 이해를 명료히 하기 위한 질문이 아니라 문제를 AI에게 떠넘기는 질문이었다. 점수도 낮고 속도도 느렸다.
고점 패턴 (퀴즈 평균 65% 이상)
AI를 코드 생성용으로도 쓰지만 이해 보강에 함께 쓴 패턴이다.
- Generation-then-comprehension (n=2) — AI에게 코드를 생성하게 한 뒤 직접 복사·붙여넣었지만, 생성 후 follow-up 질문으로 이해를 점검했다. 속도는 빠르지 않았으나 이해도가 높았다. 행동 외형은 AI delegation과 거의 같았고, 결정적 차이는 follow-up 질문 한 단계의 유무였다.
- Hybrid code-explanation (n=3) — 코드 생성과 설명을 묶어서 요청. 설명을 읽고 이해하는 시간이 들었지만 이해도가 따라왔다.
- Conceptual inquiry (n=7) — 코드 생성은 의뢰하지 않고 개념 질문만 던졌다. 오류를 많이 만났지만 스스로 해결했다. 고점 그룹 중 가장 빨랐고, 전체 패턴 중 두 번째로 빨랐다(가장 빠른 건 AI delegation).
저자들은 이 분석이 인과를 단정하지 않는다고 명시한다. 다만 학습 결과와 결합되는 행동 패턴을 가리킨다.
두 결과는 모순이 아니라 양립한다
본 연구는 같은 Anthropic의 선행 연구 — AI가 일부 작업을 80% 단축한다는 관찰 — 와 결과가 엇갈리는 듯 보인다. 저자들의 화해는 단순하다.
선행 연구는 이미 가진 스킬에 대한 생산성을 측정했고, 본 연구는 새 스킬 습득을 측정했다. AI는 숙련 스킬의 생산성을 올리면서 동시에 신규 스킬의 습득을 저해할 수 있다.
이 분리는 회사 단위에서도, 개인 단위에서도 의미가 크다. 시니어가 AI로 가속되는 동안 주니어가 같은 도구를 쓰는 방식에 따라 시니어가 되는 경로 자체가 짧아질 수도, 끊길 수도 있다.
함의 — 매니저와 개인 모두에게
저자들이 명시적으로 짚는 함의는 두 가지다.
조직 단위
“관리자는 AI 도구를 어떻게 대규모로 배포할지 의도적으로 생각해야 한다. 엔지니어가 일하면서 계속 학습하도록 — 그래서 자신이 만드는 시스템을 의미 있게 감독할 수 있도록 — 시스템이나 의도적 설계 선택을 고려해야 한다.”
시간 압박과 조직 압력이 있으면 주니어는 학습을 희생해서라도 빨리 끝내려 한다. AI 도구는 그 압력의 출구를 제공한다. 매니저가 그 압력을 그대로 두면서 도구만 풀면 학습이 가장 먼저 잘려나간다.
개인 단위
“인지 노력 — 심지어 고통스럽게 막히는 것 — 도 숙달에 중요할 수 있다.”
저자들은 LLM 서비스가 제공하는 학습 모드를 짧게 언급한다. Claude Code의 Learning·Explanatory 모드와 ChatGPT Study Mode가 그렇다. 이해를 우선시하도록 설계된 모드들이다.45
한계와 후속 질문
저자들이 직접 밝히는 한계다.
- 표본이 52명으로 비교적 작다.
- 평가는 코딩 직후 시점의 이해도를 잰 것이다. 직후 퀴즈 성적이 장기 스킬 발달을 예측하는지는 본 연구가 답하지 못한다.
- 코딩 외 도메인에 같은 효과가 있는지, 엔지니어가 도구에 익숙해질수록 효과가 사라지는지, AI 보조가 인간 멘토 보조와 같은지 — 모두 후속 연구의 몫이다.
- 실험에 쓴 사이드바형 보조는 Claude Code 같은 에이전틱 도구와는 다르다. 저자들은 각주에서 에이전틱 환경의 영향은 더 클 것으로 본다고 적었다.
가장 흥미로운 지점
본 연구에서 내가 가장 오래 머문 지점은 두 가지다.
하나는 generation-then-comprehension과 AI delegation의 비교다. 두 패턴은 외형이 거의 같다. 차이는 코드를 받은 뒤 follow-up 질문을 던지는가 한 단계뿐이다. 그런데 점수 차이는 컸다. AI 학습 도구의 설계는 “생성하지 마라"가 아니라 “생성과 이해 사이에 명시적 간격을 강제하라"로 가야 한다는 시사로 읽힌다. 사람들 사이에서 이미 떠도는 “AI로 받은 코드는 작성자에게 설명을 시켜라"라는 실천 지침이 이 데이터로 약하게 뒷받침된다.
다른 하나는 디버깅 격차가 가장 컸다는 사실이다. METR이 시니어조차 AI로 19% 더 느려진다고 보고했고, AI 의존이 감독 역량 자체를 침식한다는 관찰이 여러 자리에서 나온다. 본 연구는 거기에 인과 가설을 하나 보탠다. AI 보조군은 오류를 덜 만났기에 디버깅을 덜 훈련했다. 만들어지는 결과물보다 잘못된 결과물을 거르는 방어선 역량이 먼저 마모된다는 그림이 된다. 고위험 환경에서 AI를 운영할 조직이라면 생산 단계의 가속만큼 검증 단계의 인간 훈련 구조를 의도적으로 설계해야 한다는 뜻이다.6
출처
- 발신: Anthropic — Alignment 팀
- 저자: Judy Hanwen Shen, Alex Tamkin
- 발표일: 2026-01-29
- 블로그 원문: https://www.anthropic.com/research/AI-assistance-coding-skills
Anthropic, “Estimating productivity gains from AI”: https://www.anthropic.com/research/estimating-productivity-gains ↩︎
Lee 2025 (Microsoft, AI critical thinking survey): https://www.microsoft.com/en-us/research/wp-content/uploads/2025/01/lee_2025_ai_critical_thinking_survey.pdf ↩︎
Claude Code Learning·Explanatory mode: https://code.claude.com/docs/en/output-styles ↩︎
ChatGPT Study Mode: https://openai.com/index/chatgpt-study-mode/ ↩︎
METR 2025-07 (AI와 개발자 생산성): https://arxiv.org/abs/2507.09089 ↩︎