
3줄 요약
- agentmemory는 코딩 에이전트가 세션 종료 후에도 코드베이스 맥락·결정·실수 패턴을 기억하도록 만드는 self-hosted 메모리 엔진이다. Karpathy의 LLM Wiki gist 패턴(1,200 stars)을 실제 운영 가능한 시스템으로 구현했다.12
- 다른 메모리 시스템과의 핵심 차별은 12개 훅으로 무수동 자동 캡처, BM25+Vector+Graph 삼중 검색, iii 엔진 단일 의존(외부 DB 0), MCP·REST 단일 서버로 에이전트 횡단 공유, 저장 이전 단계 프라이버시 필터링, 멀티 에이전트 조율 프리미티브(lease·signal·routine)다.
- 기대 효과는 토큰 비용 ~92% 절감(세션당 ~1,900토큰), R@5 95.2%(ICLR 2025 LongMemEval-S), 에이전트 락인 해소(Claude Code·Cursor·Codex·Gemini CLI 횡단 메모리 공유), 자기 청소되는 지식 베이스(TTL·중요도 eviction·모순 탐지)다.3
자료 개요
- 저자·리포: Rohit Ghumare (
rohitg00/agentmemory)45 - 라이선스·배포: npm
@agentmemory/agentmemory, Docker, fly.io·Railway·Render·Coolify 원클릭 템플릿 제공 - 규모: 118 소스 파일, ~21,800 LOC, 123 함수, 34 KV scope, 950개 이상 테스트 통과
- 핵심 수치: 51 MCP 도구, 12 라이프사이클 훅, 외부 DB 의존성 0, LongMemEval-S R@5 95.2%
- 빌딩 블록: iii engine (HTTP Trigger·KV State·Stream·OTEL·Worker Supervision) 위에 구축
- 계보: Karpathy의 LLM Wiki gist 패턴을 신뢰도 점수·라이프사이클·지식 그래프·하이브리드 검색으로 확장한 구현체
설치는 한 줄로 끝난다.
npm install -g @agentmemory/agentmemory
agentmemory # 포트 3111에 메모리 서버 기동
agentmemory connect claude-code # Claude Code에 자동 와이어링 (codex/cursor/gemini-cli 등)
다른 메모리 시스템과 어떻게 다른가
mem0(53K stars)·Letta/MemGPT(22K stars)·CLAUDE.md(빌트인)·claude-mem·Hippo·mempalace 같은 인접 시스템과 비교했을 때 agentmemory가 갈라지는 지점은 여덟 가지다.
1. 12개 훅으로 무수동 자동 캡처
SessionStart·UserPromptSubmit·PreToolUse·PostToolUse·PostToolUseFailure·PreCompact·SubagentStart/Stop·Stop·SessionEnd 등 12개 라이프사이클 훅에 자동으로 끼어들어 모든 도구 사용을 관찰한다. mem0가 사용자에게 add() 호출을 시키고, Letta가 에이전트의 자체 편집에 맡기는 것과 정반대다. 사용자가 “이거 기억해줘"라고 말할 필요가 없다 — 사용한 모든 것이 자동으로 들어간다.
2. BM25 + Vector + Graph 삼중 검색
키워드 매칭(BM25, 스테밍·동의어 확장), 임베딩 유사도(Vector, 코사인), 지식 그래프 BFS(Graph, 엔티티 매칭) 세 스트림을 Reciprocal Rank Fusion(k=60)으로 합치고 세션 다양성(세션당 최대 3개)으로 후처리한다. mem0(Vector+Graph)·Letta(Vector only)와의 검색 아키텍처 차이가 가장 직접적인 축이다.
| 시스템 | 검색 전략 | LongMemEval-S R@5 |
|---|---|---|
| agentmemory | BM25 + Vector + Graph (RRF 융합) | 95.2% |
| agentmemory (BM25-only 폴백) | BM25 only | 86.2% |
| mempalace | Vector only (큰 임베딩) | 96.6% |
| Letta / MemGPT | Vector (archival) | 83.2% (LoCoMo) |
| mem0 | Vector + Graph | 68.5% (LoCoMo) |
벤치마크가 LongMemEval-S와 LoCoMo로 다른 점에 유의해야 한다. 같은 데이터셋 안에서 BM25-only(86.2%) → BM25+Vector(95.2%)로 +9pp 끌어올린 결과가 융합 자체의 기여를 입증한다. 알고리즘 수준의 구현은 아래 “그래프로 정돈하는 알고리즘” 섹션에서 따로 본다.
3. 4계층 메모리 콘솔리데이션
인간 수면 시 일어나는 기억 정리 과정을 본떠 메모리를 네 단계로 단계적으로 압축한다.
| 계층 | 내용 | 비유 |
|---|---|---|
| Working | 도구 사용에서 나온 원시 관찰 | 단기 기억 |
| Episodic | 압축된 세션 요약 | “무슨 일이 있었나” |
| Semantic | 추출된 사실·패턴 | “내가 아는 것” |
| Procedural | 워크플로 결정 패턴 | “어떻게 하는가” |
Ebbinghaus 곡선 기반 decay로 오래된 메모리는 약해지고, 자주 접근되는 메모리는 강화되며, 모순은 자동 탐지·해결된다. 정적 파일을 들고 다니는 CLAUDE.md 방식과 가장 근본적으로 갈라지는 지점이다.
4. 외부 DB 의존 0 — iii 엔진 단일 의존
Qdrant·pgvector·Postgres 같은 외부 벡터/RDB 의존성 없이 iii 엔진의 KV State와 인-메모리 벡터 인덱스만으로 동작한다. mem0(Qdrant/pgvector)·Letta(Postgres+벡터 DB)와 운영 부담이 크게 갈라진다. self-host가 기본값이 되고, 단일 명령으로 fly.io·Railway·Render·Coolify에 배포 가능하다.
5. MCP·REST 단일 서버로 에이전트 횡단 공유
한 번 띄운 서버를 동일한 MCP 블록으로 Claude Code·Cursor·Codex CLI·Gemini CLI·Windsurf·Cline·Roo·Goose·Claude Desktop·OpenCode 등이 공유한다.
{
"mcpServers": {
"agentmemory": {
"command": "npx",
"args": ["-y", "@agentmemory/mcp"],
"env": { "AGENTMEMORY_URL": "http://localhost:3111" }
}
}
}
.cursorrules·CLAUDE.md처럼 에이전트별 파일이 분리되지 않으며, 같은 프로젝트 메모리를 모든 에이전트가 같은 인덱스로 읽는다.
6. 저장 이전 단계의 프라이버시 필터링
API 키·시크릿·<private> 태그가 붙은 내용은 저장 이전 단계에서 스트립된다. mem0·Letta·CLAUDE.md 모두 이 단계가 없어, 시크릿이 한번 메모리에 들어가면 검색 결과로 다른 세션에 새어 나갈 위험이 있다. agentmemory만이 “메모리에 시크릿이 들어가지 않는다"를 기본 보증한다.
7. 멀티 에이전트 조율 프리미티브
단순 read/write를 넘어 멀티 에이전트 조율을 1급 도구로 제공한다.
| 프리미티브 | 역할 |
|---|---|
memory_lease | 독점 액션 잠금 (동시 작업 방지) |
memory_signal_send/read | 에이전트 간 메시징·읽음 수신 |
memory_routine_run | 워크플로 인스턴스화 |
memory_sentinel_create/trigger | 이벤트 감시·외부 트리거 |
memory_mesh_sync | P2P 인스턴스 동기화 |
memory_checkpoint | 외부 조건 게이트 |
여러 에이전트가 같은 코드베이스에서 협업할 때 “누가 무엇을 잠그고 있는가"를 메모리 계층에서 푼다.
8. 거버넌스·감사·citation 프로비넌스
모든 변형(memory_governance_delete 등)이 감사 로그에 기록되고, 모든 메모리 항목은 memory_verify로 원본 관찰까지 역추적 가능한 citation 체인을 가진다. Git-versioned snapshot으로 메모리 상태 자체를 롤백할 수 있다. “메모리도 git처럼 다뤄야 한다"는 입장이며, mem0·Letta·CLAUDE.md에 없는 축이다.
그래프로 정돈하는 알고리즘
여덟 가지 차별점 가운데 시스템의 실제 성능을 받치는 가장 핵심 모듈은 그래프 추출·검색 파이프라인이다. 이 부분만 따로 떼어 본다. 소스 위치는 src/prompts/graph-extraction.ts, src/functions/graph.ts, src/functions/graph-retrieval.ts, src/functions/temporal-graph.ts, src/state/hybrid-search.ts 다섯 파일이다.
1단계 — LLM이 XML로 엔티티·관계를 토해낸다
압축된 관찰(CompressedObservation)이 들어오면, 시스템 프롬프트(GRAPH_EXTRACTION_SYSTEM)가 LLM에게 XML 출력을 강제한다. 엔티티 타입은 여덟 가지로 닫혀 있다.
file | function | concept | error | decision | pattern | library | person
관계 타입도 일곱 가지로 닫혀 있고, 각각 0.1~1.0 가중치를 갖는다.
uses | imports | modifies | causes | fixes | depends_on | related_to
weight: 1.0 = 명시적 진술, 0.5 = 추론, 0.1 = 추측
LLM 자유 출력을 받지 않고 닫힌 어휘를 강제한다는 점이 중요하다. “지식 그래프"라는 이름이 흔히 가지는 무정형성을 막고, 동일한 엔티티가 여러 관찰에서 같은 이름·같은 타입으로 일관되게 추출되도록 유도한다.
시간 그래프 모드(temporal-graph.ts)에서는 엔티티 타입이 13가지로(project·preference·location·organization·event 추가), 관계 타입이 16가지로(works_at·prefers·blocked_by·caused_by·optimizes_for·rejected·avoids·located_in·succeeded_by 추가) 확장되고, 각 관계마다 reasoning·sentiment·alternatives·valid_from·valid_to 메타데이터를 추가로 받아온다.
2단계 — 같은 엔티티를 만나면 합쳐진다
새로 추출된 노드를 KV 스토어에 저장할 때, (name, type) 조합이 같은 기존 노드가 있으면 합친다.
properties: merge (새 값이 기존 키 덮어씀)
sourceObservationIds: union (어느 관찰에서 봤는지 모두 보존)
엣지도 마찬가지로 (sourceNodeId, targetNodeId, type) 키로 동일 관계가 있으면 sourceObservationIds를 합집합한다. 즉 같은 사실이 N번 관찰되면 그래프 안에서는 한 엣지의 관찰 출처가 N개로 누적된다. 이 누적량 자체가 신뢰도의 대용 신호가 되며, 나중에 검색 점수에 반영된다.
여기서 시간 그래프 모드의 핵심 정책이 갈라진다 — “NEVER overwrite existing relationships — always create new versioned edges”. 같은 (source, target, type)이라도 시간이 지나 변하면 합치지 않고 새 버전의 엣지를 추가한다. “내가 jose를 썼다"는 사실이 6개월 뒤 “이제 jsonwebtoken을 쓴다"로 바뀔 때, 옛 엣지는 사라지지 않고 valid_to가 채워지며 나란히 보존된다.
3단계 — 두 갈래의 BFS 검색
검색 시 그래프는 두 갈래로 활용된다(graph-retrieval.ts).
(a) searchByEntities — 사용자 쿼리에서 엔티티 후보를 뽑아(extractEntitiesFromQuery), 이름이 부분 매칭되는 노드를 시작점으로 잡고, maxDepth=2까지 BFS로 이웃 노드를 훑는다. 도달한 각 노드의 sourceObservationIds에서 관찰 ID를 수확하며, 점수는 경로의 평균 엣지 가중치를 길이로 나눈다.
score = avg(edge.weight along path) × (1 / pathLength)
가까울수록·관계가 강할수록 높은 점수. 시작 노드와 직접 연결된 관찰은 길이 0으로 점수 1.0을 받는다.
(b) expandFromChunks — 벡터 검색의 상위 5개 관찰에서 시작해, 그 관찰을 출처로 둔 노드들로부터 maxDepth=1까지 BFS로 확장한다. “벡터가 비슷한 것을 먼저 찾고, 그 주변을 그래프로 한 걸음 더 본다"는 보조 전략이다. 점수는 0.5에 길이 보정을 곱한다.
두 갈래의 결과는 합쳐져 단일 graph 스트림이 된다. 그래프 검색은 best-effort로 묶여 있어, 엔티티가 안 뽑히거나 BFS가 실패해도 BM25·Vector는 계속 돈다.
4단계 — RRF로 세 스트림을 합친다
BM25·Vector·Graph 세 스트림의 결과를 Reciprocal Rank Fusion으로 합친다(hybrid-search.ts:208-219). 핵심 한 줄은 다음과 같다.
combinedScore =
w_bm25 × 1 / (60 + bm25Rank) +
w_vector × 1 / (60 + vectorRank) +
w_graph × 1 / (60 + graphRank)
k=60 상수는 RRF 표준값이다. 기본 가중치는 BM25=0.4, Vector=0.6, Graph=0.3이며 — 가용한 스트림이 없으면 그 가중치는 0으로 떨어뜨리고 나머지를 정규화한다. 임베딩 제공자가 없는 환경에서는 자동으로 BM25+Graph 두 스트림으로 운영되고, 엔티티가 안 뽑힌 쿼리에서는 자동으로 BM25+Vector 두 스트림으로 운영된다.
같은 관찰 ID가 세 스트림 모두에 나타나면 세 항이 모두 더해진다. 즉 “키워드도 맞고·의미도 가깝고·그래프 이웃이기도 한” 관찰이 가장 높은 점수를 받는다. 한 신호만 강한 결과보다, 신호 셋이 동의하는 결과가 위로 올라온다.
후처리 두 단계가 더 있다. 세션 다양성 — 같은 세션에서 나온 결과는 최대 3개로 제한해, 한 세션이 결과를 독점하지 않게 한다. 선택적 리랭커 — RERANK_ENABLED=true면 상위 20개를 다시 정렬한다.
5단계 — 시간 차원과 graphContext
융합 점수 외에도, 그래프 검색이 반환하는 graphContext 필드는 “왜 이 결과가 나왔는가“의 경로를 자연어로 들고 다닌다.
[concept] JWT auth (provider=jose) --uses--> [file] src/middleware/auth.ts
[reasoning: Edge runtime compatibility required] @2025-09-12
temporalQuery(entityName, asOf)로 특정 시점의 그래프 단면을 잘라낼 수도 있다.
"2025-03-15 기준 우리 인증 미들웨어는 무엇이었는가?"
→ asOf 이전에 tcommit/tvalid가 있고, tvalidEnd가 asOf 이후인 엣지만 반환
→ jose 시기의 결정 + 그 결정의 reasoning + 대체로 고려했던 alternatives까지
mem0·Letta 같은 인접 시스템에서 가장 옅은 부분이 바로 이 시간 차원이다. agentmemory에서 그래프 모듈이 가장 큰 변별력을 갖는 이유는 — 단순히 “지식 그래프가 있다"가 아니라, (1) 닫힌 어휘로 일관된 엔티티 추출, (2) 머지·버전 정책의 명시화, (3) 두 갈래 BFS 검색, (4) RRF 융합 시 세 신호의 동의를 가중, (5) bi-temporal 메타데이터로 결정의 시간적 변화 보존 다섯 가지가 한 파이프라인으로 결합되어 있어서다.
어떤 효과를 기대할 수 있는가
토큰 비용 ~92% 절감
240개 관찰 기준 CLAUDE.md 방식(22K+ 토큰)을 token-budgeted top-K 인젝션(약 1,900 토큰)으로 대체한다. 연간 비용 비교는 다음과 같다.
| 접근 | 토큰/년 | 비용/년 |
|---|---|---|
| 전체 컨텍스트 페이스트 | 19.5M+ | 불가능 (윈도우 초과) |
| LLM 요약 메모리 | ~650K | ~$500 |
| agentmemory (API 임베딩) | ~170K | ~$10 |
| agentmemory (로컬 임베딩) | ~170K | $0 |
로컬 임베딩(all-MiniLM-L6-v2)을 쓰면 임베딩 비용도 사라진다. npx @agentmemory/agentmemory status로 실제 절감액을 그대로 보여준다.
재설명 비용 제거 — 세션 횡단 컨텍스트
원문이 드는 예시 그대로 옮기면: 세션 1에서 JWT 인증을 jose 미들웨어(src/middleware/auth.ts)로 구현했고, 테스트는 test/auth.test.ts에 있고, jose를 jsonwebtoken 대신 고른 이유가 Edge 호환성이라는 사실을 — 세션 2에서 “레이트 리미팅 추가해줘"라고만 해도 에이전트가 이미 안다. 매 세션 처음 5분의 스택 재설명 비용이 사라지고, 같은 결정을 두 번 내리지 않게 된다.
회상 정확도 R@5 95.2%
ICLR 2025 LongMemEval-S 500개 질문(세션당 ~115K 토큰, ~48 세션) 기준 R@5 95.2% / R@10 98.6% / MRR 88.2%. 같은 시스템 안에서 BM25-only 폴백(86.2%) 대비 임베딩+융합으로 +9pp 끌어올린 효과는 동일 데이터셋 내에서 통제된 비교다. mem0(LoCoMo 68.5%)·Letta(LoCoMo 83.2%)와는 벤치마크가 달라 직접 비교는 신중해야 한다.
에이전트 락인 해소
Claude Code에서 시작한 프로젝트 작업을 Cursor·Codex·Gemini CLI로 넘기더라도 같은 메모리 인덱스를 공유한다. 도구를 바꾼다고 “기억"이 흩어지지 않으며, 팀원이 다른 에이전트를 쓰더라도 같은 프로젝트 컨텍스트를 본다. 빌트인 메모리의 “에이전트별 파일” 모델에서 완전히 벗어난다.
자기 청소되는 지식 베이스
수동 정비 없이도 메모리가 스스로 정돈된다.
- TTL 만료 — 기한 지난 메모리 자동 제거
- 중요도 기반 eviction — 사용 빈도 낮은 메모리부터 잘라냄
- 모순 탐지·해결 — 새 사실이 기존 사실과 충돌하면 자동 비교
- Supersession — 이전 결정이 새 결정으로 대체될 때 옛 것을 자동 강등 (Jaccard 기반)
- Lesson decay — Ebbinghaus 곡선 적용
CLAUDE.md처럼 “200줄을 넘으면 사용자가 직접 가지치기” 부담이 사라진다.
아키텍처적 입장
iii 엔진 위의 어플리케이션
agentmemory는 단순한 라이브러리가 아니라 iii 엔진 위에 만든 어플리케이션이다. 전통 스택과의 대응 관계는 다음과 같다.
| 전통 스택 | agentmemory가 쓰는 것 |
|---|---|
| Express.js / Fastify | iii HTTP Triggers |
| SQLite / Postgres + pgvector | iii KV State + 인-메모리 벡터 인덱스 |
| SSE / Socket.io | iii Streams (WebSocket) |
| pm2 / systemd | iii engine worker supervision |
| Prometheus / Grafana | iii OTEL + 헬스 모니터 |
| 커스텀 플러그인 시스템 | iii worker add <name> |
확장도 한 줄 명령으로 이뤄진다.
iii worker add iii-pubsub # 모든 인스턴스로 메모리 쓰기 팬아웃
iii worker add iii-cron # 야간 콘솔리데이션, 주간 스냅샷, decay 스케줄
iii worker add iii-queue # 임베딩·압축 작업 내구성 큐
iii worker add iii-sandbox # 회상된 코드를 격리 microVM에서 실행
iii 콘솔(iii console --port 3114)을 띄우면 메모리 작업이 OpenTelemetry 트레이스 워터폴로 보인다.
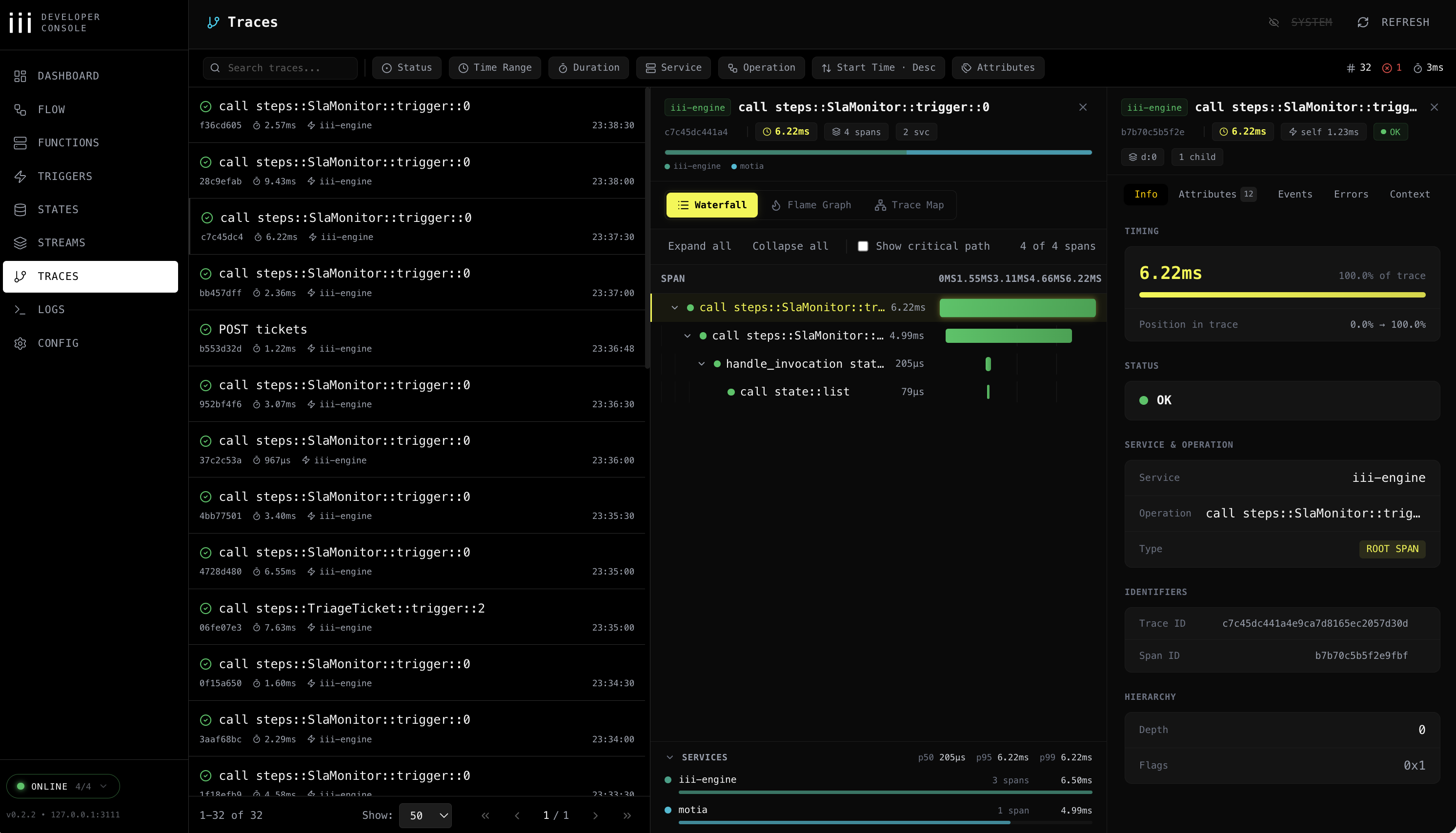
memory_smart_search 한 번이 BM25 스캔 → 임베딩 룩업 → RRF 융합 → 리랭커로 분해되는 모습을 그대로 볼 수 있다.
Karpathy LLM Wiki 패턴의 구현체
저자 본인의 표현으로 “gist는 설계서, agentmemory는 구현체"다. Andrej Karpathy가 공유한 LLM Wiki gist는 viral 1,200 stars / 172 forks를 모았지만, 그것 자체는 노트 패턴에 가깝다. agentmemory는 거기에 신뢰도 점수·라이프사이클·지식 그래프·하이브리드 검색을 더해 실제 운영 시스템으로 만들었다.
가장 흥미로운 지점 — 융합 전략은 임베딩 크기를 대체할 수 있다
agentmemory의 R@5 95.2%는 all-MiniLM-L6-v2(384-dim 로컬 임베딩)와 BM25+Vector+Graph 융합의 조합으로 얻은 수치다. 같은 LongMemEval-S 벤치마크에서 mempalace는 더 큰 임베딩으로 Vector-only 96.6%에 도달했다. 두 시스템이 거의 같은 95%대에 두 다른 경로로 닿았다는 사실이 흥미롭다.6
같은 시스템 안에서 BM25-only(86.2%) → BM25+Vector(95.2%)로 +9pp 끌어올린 통제 비교는 융합 자체가 실제 일을 한다는 증거다. 시사하는 바는 분명하다 — 에이전트 메모리에서 top-K 회상 정확도는 임베딩 모델 크기만의 함수가 아니라 융합 전략의 함수이기도 하다. 작은 로컬 임베딩에 다중 신호 융합을 더하는 것으로 큰 임베딩 단독 수준에 도달할 수 있고, OpenAI 임베딩 API 비용 없이 온디바이스로 SOTA급 회상을 운영할 수 있다.
“임베딩 모델을 더 좋은 걸로 갈아끼우자"는 흔한 직관이 항상 옳지는 않다는 뜻이다. 융합 파이프라인 자체에 투자하는 편이 더 비용 효율적일 수 있다.
의의와 한계
agentmemory가 보여주는 의의는 — 에이전트 영구 메모리가 더 이상 “메모리 레이어 API”(mem0)나 “전체 에이전트 런타임”(Letta)이라는 두 갈래로만 풀리는 문제가 아니라는 점이다. 자동 캡처·하이브리드 검색·자기 청소·거버넌스를 모두 갖춘 단일 self-hosted 엔진이라는 제3의 답이 자리잡았고, 그것이 외부 DB 의존 없이 iii 위에서 돌아간다는 점이 운영 차원의 진입 장벽을 크게 낮춘다.
한계도 있다. (1) iii 엔진 v0.11.2에 핀이 걸려 있어 최신 sandbox 모델로의 마이그레이션이 아직 필요하다. (2) LongMemEval-S와 mem0·Letta가 측정하는 LoCoMo가 다른 벤치마크라 직접 비교에 신중해야 한다. (3) LLM 압축(AGENTMEMORY_AUTO_COMPRESS)은 기본 OFF — Stop 훅 재귀 위험(#149) 때문이며, 활성화 시 토큰 비용이 다시 늘어난다. (4) “메모리에 시크릿이 들어가지 않는다"는 보증은 정규식 기반 필터링에 의존하므로 비전형 패턴은 새어 나갈 여지가 남는다.
출처
참고 — Karpathy LLM Wiki gist: https://gist.github.com/rohitg00/2067ab416f7bbe447c1977edaaa681e2 ↩︎
참고 — LongMemEval (ICLR 2025): https://arxiv.org/abs/2410.10813 ↩︎
벤치마크 비교: https://github.com/rohitg00/agentmemory/blob/main/benchmark/COMPARISON.md ↩︎
LongMemEval 보고: https://github.com/rohitg00/agentmemory/blob/main/benchmark/LONGMEMEVAL.md ↩︎