We Must Address the Growing Rage Against the A.I. Machine
Eric Schmidt와 Selina Xu가 NYT Opinion에 기고했다. 미국의 AI 대중 반발이 커지는 상황을 진단하고, 중국의 안정 우선 조치들과 대비한 뒤, AI를 공공 프로젝트로 다루는 ‘포퓰리스트 AI 어젠다’ 세 가지를 제안한다.
Eric Schmidt와 Selina Xu가 NYT Opinion에 기고했다. 미국의 AI 대중 반발이 커지는 상황을 진단하고, 중국의 안정 우선 조치들과 대비한 뒤, AI를 공공 프로젝트로 다루는 ‘포퓰리스트 AI 어젠다’ 세 가지를 제안한다.
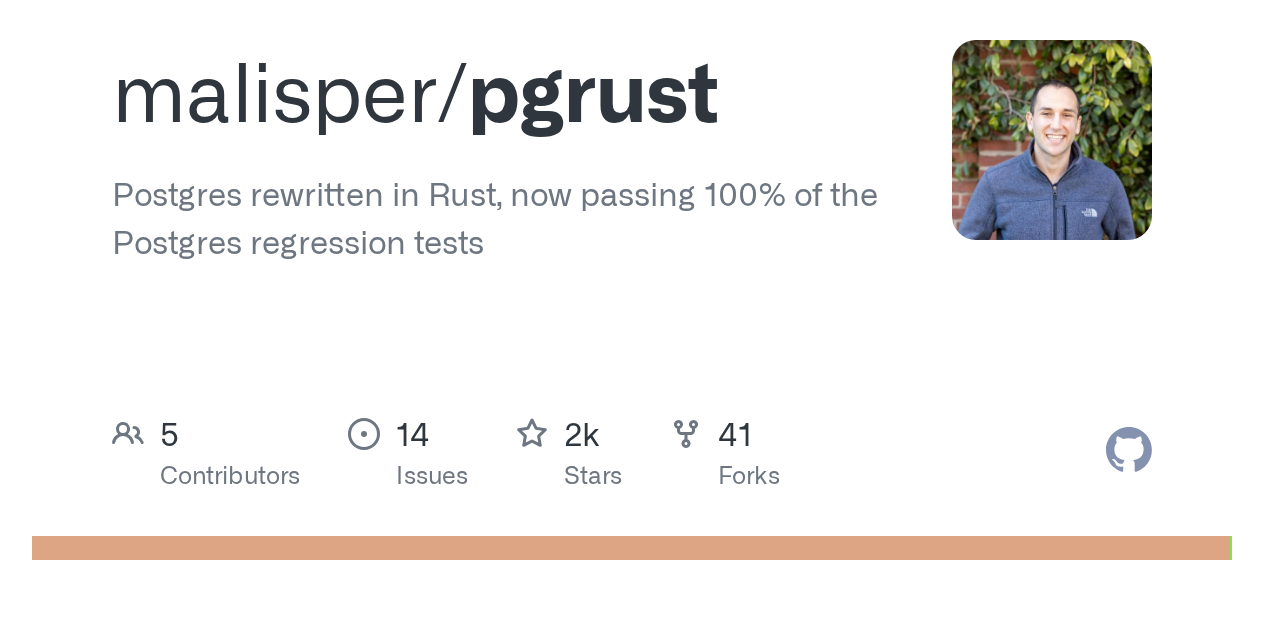
PostgreSQL 18.3의 동작과 디스크 형식을 Rust로 재현하는 pgrust 저장소를 살핀다. 공개판은 4만6천 건이 넘는 회귀 질의 결과 일치를 내세우며, 실제 PostgreSQL 테스트를 정답지로 삼아 호환성을 먼저 고정한 뒤 내부 구조를 바꾸려 한다.
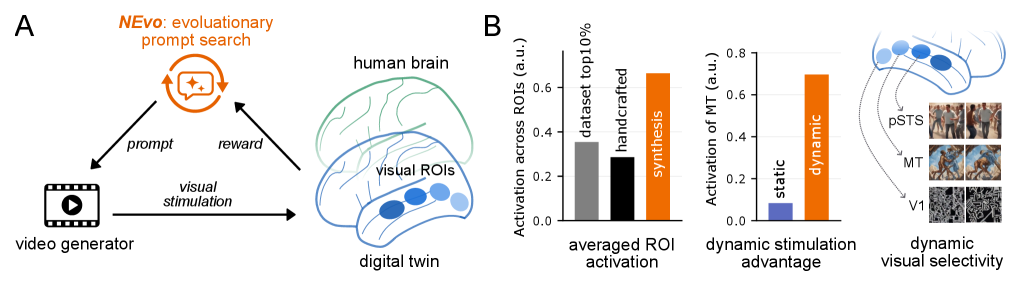
뇌의 특정 시각 피질을 가장 강하게 활성화할 2초짜리 영상을 진화 검색으로 만들어내는 EPFL·존스홉킨스의 프레임워크. 정적 이미지에 갇혀 있던 in silico 자극 합성을 동적 영상으로 확장한 첫 사례다.
OpenAI가 GPT-5.6 패밀리(Sol, Terra, Luna)를 정식 출시했다. 토큰당 유효 작업량이라는 효율 지표를 전면에 세우고, 코딩과 지식 노동, 사이버보안, 과학에서 다수의 최고 기록과 함께 병렬 멀티에이전트 설정 ultra, 강화된 안전 체계를 공개했다.

World Machine 스타일의 침식 지형을, 시뮬레이션 없이 단일 픽셀 셰이더 한 패스로 재현하는 필터의 8개월치 발전 기록. Rune Skovbo Johansen이 Clay John(2018)·Fewes(2023) 계보 위에 fade approach와 stacked fading을 새로 얹었다.

아이가 초등학년 사이에 배우는 모든 것을 1,590개 마이크로 토픽으로 잘게 쪼개고, 그 사이 3,221개 선수학습 엣지로 엮은 뒤 7개국 커리큘럼 표준까지 정렬해 공개한 오픈 데이터셋.

2,000달러로는 Qwen과 로컬 STT까지, 40,000달러로는 거의 Opus급 GLM-5.2까지. Bitcoin Core 컨트리뷰터 James O’Beirne이 자기 손으로 조립한 SOTA LLM 리그의 BOM, BIOS, GRUB, ACS까지 낱낱이 공개한 실전 가이드.
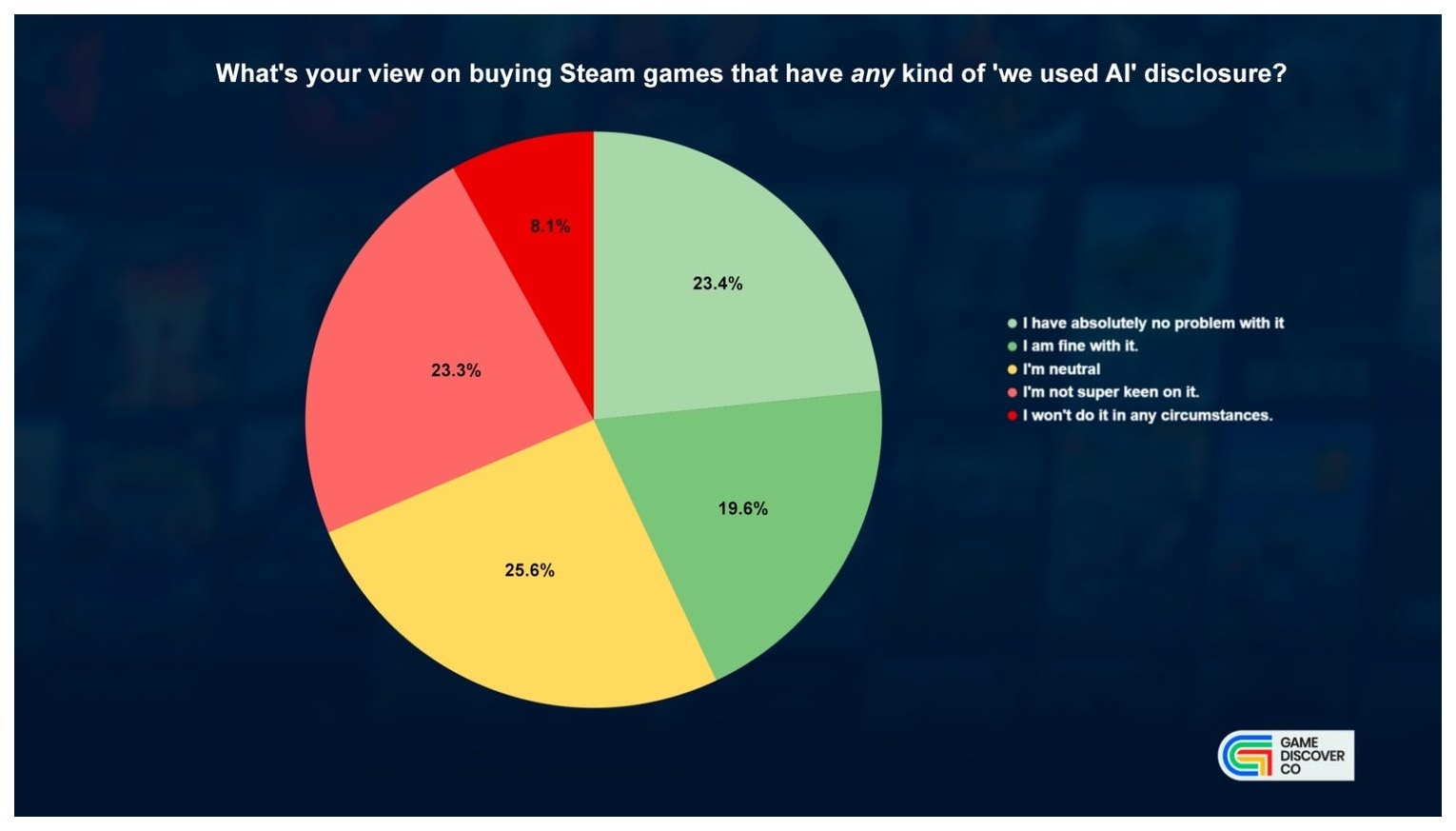
GameDiscoverCo가 Steam 유저 약 3,800명을 대상으로 진행한 설문 조사. 43%는 생성 AI가 쓰인 게임 구매에 지장이 없다고 답했고, 31%는 부정적, 25%는 중립. 자유 응답에서는 코딩·프로토타입 등 조건부 허용이 다수였다.

Modulate의 AI 음성 채팅 모더레이션 ToxMod가 GTA Online에 전면 도입된 뒤, 2025년 한 해 동안 일일 평균 위반이 약 35% 줄고 위반 유저 비율이 3.2%에서 0.49%로 떨어졌다. 음성 채팅 학대는 반복 사망보다 강한 분노·이탈 요인이었다는 계량 결과가 함께 공개됐다.

Cloudflare가 자사 뒤에 있는 모든 리소스(웹 페이지·데이터셋·API·MCP 툴)에 사용량 기반으로 과금하는 Monetization Gateway 대기자 명단을 연다. 정산은 x402 오픈 프로토콜과 스테이블코인으로 이뤄지며, 에이전트가 웹의 주 구매자가 되는 시대에 맞춘 결제 인프라다.